 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidential Domain Adaptation for Remaining Useful Life Prediction with Incomplete Degradation
Mar 15, 2026Accurate Remaining Useful Life (RUL) prediction without labeled target domain data is a critical challenge, and domain adaptation (DA) has been widely adopted to address it by transferring knowledge from a labeled source domain to an unlabeled target domain. Despite its success, existing DA methods struggle significantly when faced with incomplete degradation trajectories in the target domain, particularly due to the absence of late degradation stages. This missing data introduces a key extrapolation challenge. When applied to such incomplete RUL prediction tasks, current DA methods encounter two primary limitations. First, most DA approaches primarily focus on global alignment, which can misaligns late degradation stage in the source domain with early degradation stage in the target domain. Second, due to varying operating conditions in RUL prediction, degradation patterns may differ even within the same degradation stage, resulting in different learned features. As a result, even if degradation stages are partially aligned, simple feature matching cannot fully align two domains. To overcome these limitations, we propose a novel evidential adaptation approach called EviAdapt, which leverages evidential learning to enhance domain adaptation. The method first segments the source and target domain data into distinct degradation stages based on degradation rate, enabling stage-wise alignment that ensures samples from corresponding stages are accurately matched. To address the second limitation, we introduce an evidential uncertainty alignment technique that estimates uncertainty using evidential learning and aligns the uncertainty across matched stages.
Adaptive Stylization Modulation for Domain Generalized Semantic Segmentation
Apr 20, 2023Obtaining sufficient labelled data for model training is impractical for most real-life applications. Therefore, we address the problem of domain generalization for semantic segmentation tasks to reduce the need to acquire and label additional data. Recent work on domain generalization increase data diversity by varying domain-variant features such as colour, style and texture in images. However, excessive stylization or even uniform stylization may reduce performance. Performance reduction is especially pronounced for pixels from minority classes, which are already more challenging to classify compared to pixels from majority classes. Therefore, we introduce a module, $ASH_{+}$, that modulates stylization strength for each pixel depending on the pixel's semantic content. In this work, we also introduce a parameter that balances the element-wise and channel-wise proportion of stylized features with the original source domain features in the stylized source domain images. This learned parameter replaces an empirically determined global hyperparameter, allowing for more fine-grained control over the output stylized image. We conduct multiple experiments to validate the effectiveness of our proposed method. Finally, we evaluate our model on the publicly available benchmark semantic segmentation datasets (Cityscapes and SYNTHIA). Quantitative and qualitative comparisons indicate that our approach is competitive with state-of-the-art. Code is made available at \url{https://github.com/placeholder}
Label-efficient Time Series Representation Learning: A Review
Feb 13, 2023



The scarcity of labeled data is one of the main challenges of applying deep learning models on time series data in the real world. Therefore, several approaches, e.g., transfer learning, self-supervised learning, and semi-supervised learning, have been recently developed to promote the learning capability of deep learning models from the limited time series labels. In this survey, for the first time, we provide a novel taxonomy to categorize existing approaches that address the scarcity of labeled data problem in time series data based on their reliance on external data sources. Moreover, we present a review of the recent advances in each approach and conclude the limitations of the current works and provide future directions that could yield better progress in the field.
CoTMix: Contrastive Domain Adaptation for Time-Series via Temporal Mixup
Dec 03, 2022Unsupervised Domain Adaptation (UDA) has emerged as a powerful solution for the domain shift problem via transferring the knowledge from a labeled source domain to a shifted unlabeled target domain. Despite the prevalence of UDA for visual applications, it remains relatively less explored for time-series applications. In this work, we propose a novel lightweight contrastive domain adaptation framework called CoTMix for time-series data. Unlike existing approaches that either use statistical distances or adversarial techniques, we leverage contrastive learning solely to mitigate the distribution shift across the different domains. Specifically, we propose a novel temporal mixup strategy to generate two intermediate augmented views for the source and target domains. Subsequently, we leverage contrastive learning to maximize the similarity between each domain and its corresponding augmented view. The generated views consider the temporal dynamics of time-series data during the adaptation process while inheriting the semantics among the two domains. Hence, we gradually push both domains towards a common intermediate space, mitigating the distribution shift across them. Extensive experiments conducted on four real-world time-series datasets show that our approach can significantly outperform all state-of-the-art UDA methods. The implementation code of CoTMix is available at \href{https://github.com/emadeldeen24/CoTMix}{github.com/emadeldeen24/CoTMix}.
Self-supervised Learning for Label-Efficient Sleep Stage Classification: A Comprehensive Evaluation
Oct 10, 2022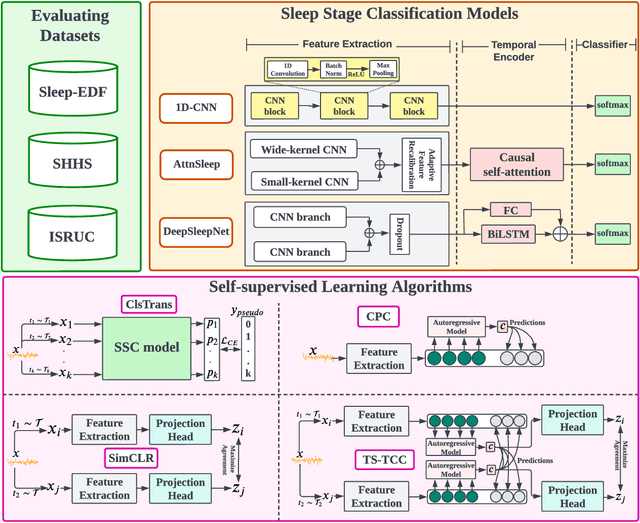
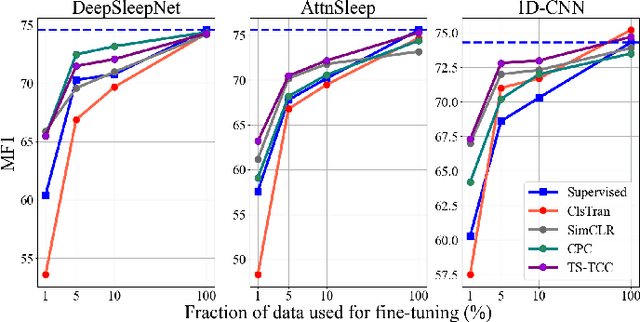
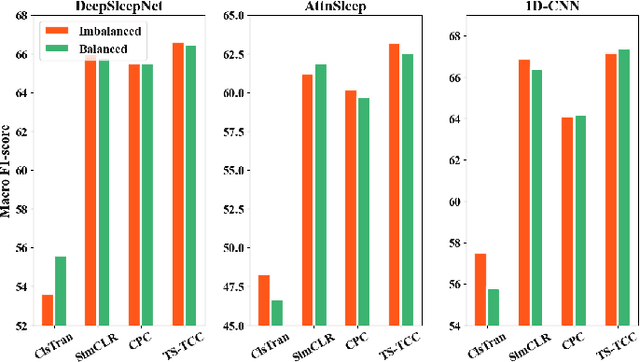

The past few years have witnessed a remarkable advance in deep learning for EEG-based sleep stage classification (SSC). However, the success of these models is attributed to possessing a massive amount of labeled data for training, limiting their applicability in real-world scenarios. In such scenarios, sleep labs can generate a massive amount of data, but labeling these data can be expensive and time-consuming. Recently, the self-supervised learning (SSL) paradigm has shined as one of the most successful techniques to overcome the scarcity of labeled data. In this paper, we evaluate the efficacy of SSL to boost the performance of existing SSC models in the few-labels regime. We conduct a thorough study on three SSC datasets, and we find that fine-tuning the pretrained SSC models with only 5% of labeled data can achieve competitive performance to the supervised training with full labels. Moreover, self-supervised pretraining helps SSC models to be more robust to data imbalance and domain shift problems. The code is publicly available at \url{https://github.com/emadeldeen24/eval_ssl_ssc}.
Self-supervised Contrastive Representation Learning for Semi-supervised Time-Series Classification
Aug 13, 2022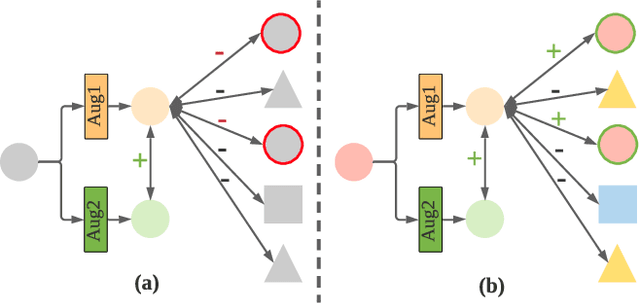
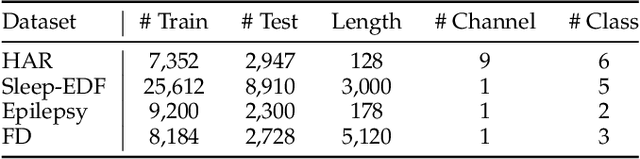
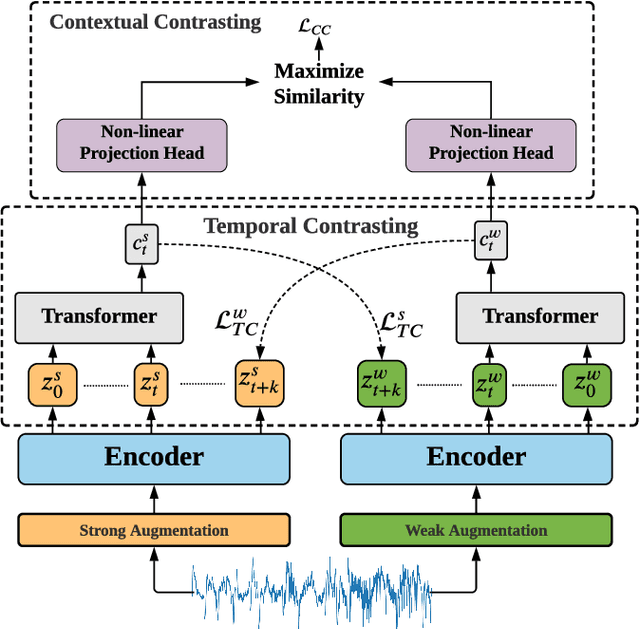
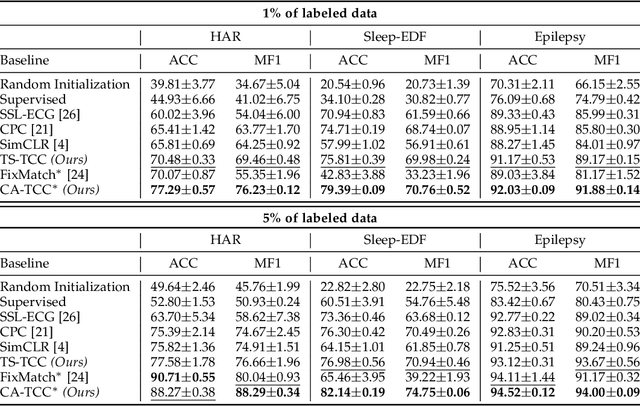
Learning time-series representations when only unlabeled data or few labeled samples are available can be a challenging task. Recently, contrastive self-supervised learning has shown great improvement in extracting useful representations from unlabeled data via contrasting different augmented views of data. In this work, we propose a novel Time-Series representation learning framework via Temporal and Contextual Contrasting (TS-TCC) that learns representations from unlabeled data with contrastive learning. Specifically, we propose time-series specific weak and strong augmentations and use their views to learn robust temporal relations in the proposed temporal contrasting module, besides learning discriminative representations by our proposed contextual contrasting module. Additionally, we conduct a systematic study of time-series data augmentation selection, which is a key part of contrastive learning. We also extend TS-TCC to the semi-supervised learning settings and propose a Class-Aware TS-TCC (CA-TCC) that benefits from the available few labeled data to further improve representations learned by TS-TCC. Specifically, we leverage robust pseudo labels produced by TS-TCC to realize class-aware contrastive loss. Extensive experiments show that the linear evaluation of the features learned by our proposed framework performs comparably with the fully supervised training. Additionally, our framework shows high efficiency in few labeled data and transfer learning scenarios. The code is publicly available at \url{https://github.com/emadeldeen24/TS-TCC}.
ADATIME: A Benchmarking Suite for Domain Adaptation on Time Series Data
Mar 15, 2022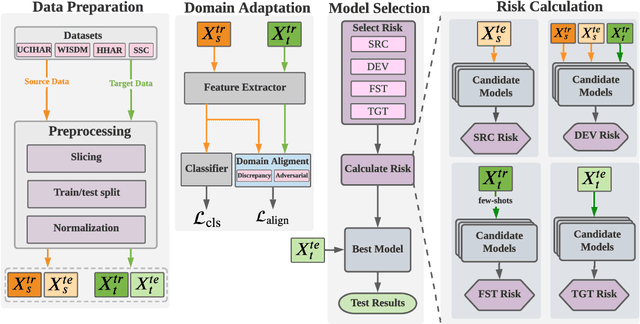
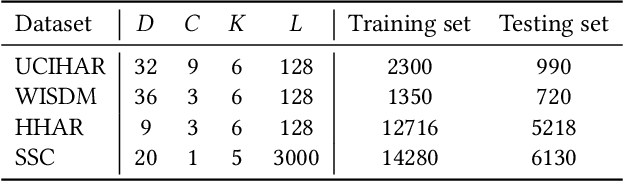


Unsupervised domain adaptation methods aim to generalize well on unlabeled test data that may have a different (shifted) distribution from the training data. Such methods are typically developed on image data, and their application to time series data is less explored. Existing works on time series domain adaptation suffer from inconsistencies in evaluation schemes, datasets, and backbone neural network architectures. Moreover, labeled target data are usually employed for model selection, which violates the fundamental assumption of unsupervised domain adaptation. To address these issues, we develop a benchmarking evaluation suite (ADATIME) to systematically and fairly evaluate different domain adaptation methods on time series data. Specifically, we standardize the backbone neural network architectures and benchmarking datasets, while also exploring more realistic model selection approaches that can work with no labeled data or just few labeled samples. Our evaluation includes adapting state-of-the-art visual domain adaptation methods to time series data in addition to the recent methods specifically developed for time series data. We conduct extensive experiments to evaluate 10 state-of-the-art methods on four representative datasets spanning 20 cross-domain scenarios. Our results suggest that with careful selection of hyper-parameters, visual domain adaptation methods are competitive with methods proposed for time series domain adaptation. In addition, we find that hyper-parameters could be selected based on realistic model selection approaches. Our work unveils practical insights for applying domain adaptation methods on time series data and builds a solid foundation for future works in the field. The code is available at \href{https://github.com/emadeldeen24/AdaTime}{github.com/emadeldeen24/AdaTime}.
Attention over Self-attention:Intention-aware Re-ranking with Dynamic Transformer Encoders for Recommendation
Jan 14, 2022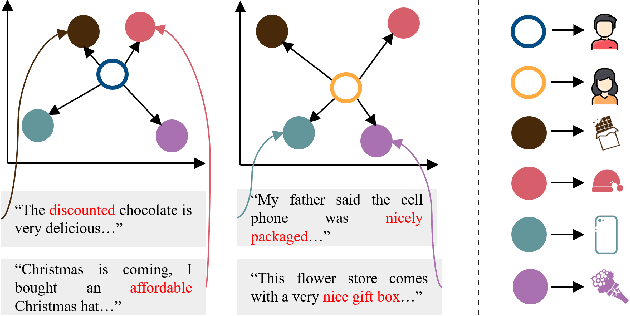
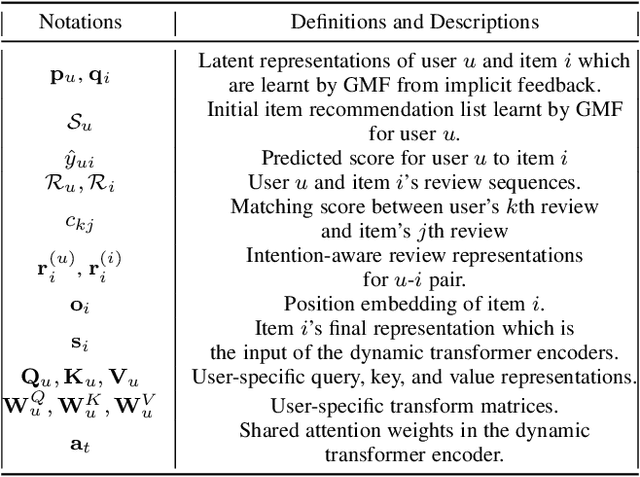
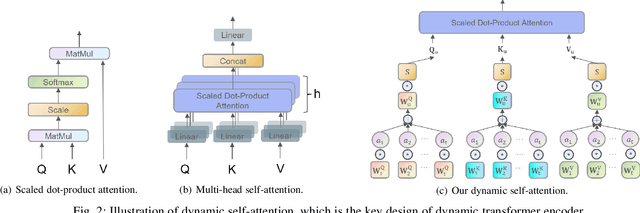
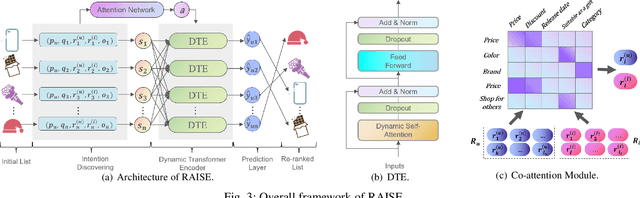
Re-ranking models refine the item recommendation list generated by the prior global ranking model with intra-item relationships. However, most existing re-ranking solutions refine recommendation list based on the implicit feedback with a shared re-ranking model, which regrettably ignore the intra-item relationships under diverse user intentions. In this paper, we propose a novel Intention-aware Re-ranking Model with Dynamic Transformer Encoder (RAISE), aiming to perform user-specific prediction for each target user based on her intentions. Specifically, we first propose to mine latent user intentions from text reviews with an intention discovering module (IDM). By differentiating the importance of review information with a co-attention network, the latent user intention can be explicitly modeled for each user-item pair. We then introduce a dynamic transformer encoder (DTE) to capture user-specific intra-item relationships among item candidates by seamlessly accommodating the learnt latent user intentions via IDM. As such, RAISE is able to perform user-specific prediction without increasing the depth (number of blocks) and width (number of heads) of the prediction model. Empirical study on four public datasets shows the superiority of our proposed RAISE, with up to 13.95%, 12.30%, and 13.03% relative improvements evaluated by Precision, MAP, and NDCG respectively.
Self-supervised Autoregressive Domain Adaptation for Time Series Data
Nov 29, 2021
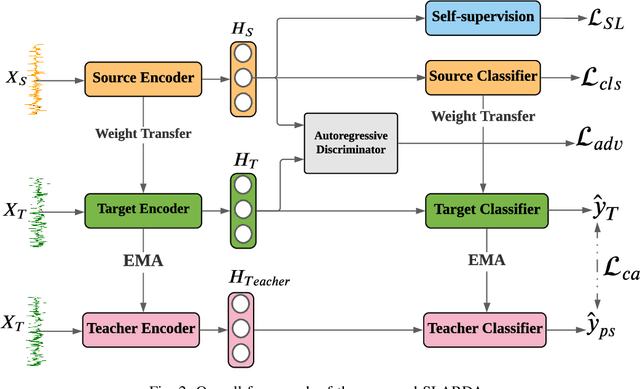
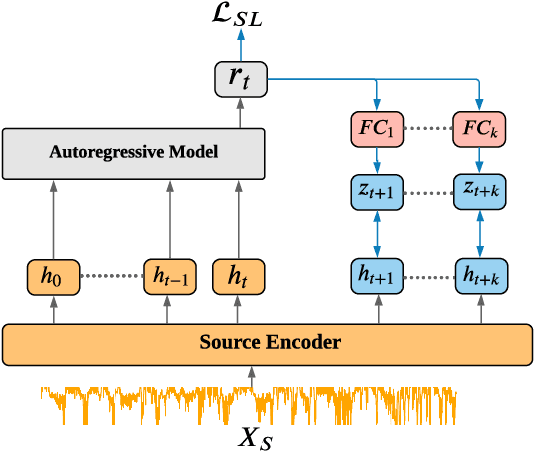
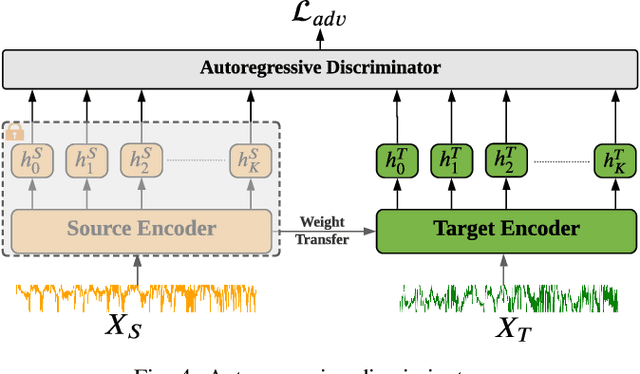
Unsupervised domain adaptation (UDA) has successfully addressed the domain shift problem for visual applications. Yet, these approaches may have limited performance for time series data due to the following reasons. First, they mainly rely on large-scale dataset (i.e., ImageNet) for the source pretraining, which is not applicable for time-series data. Second, they ignore the temporal dimension on the feature space of the source and target domains during the domain alignment step. Last, most of prior UDA methods can only align the global features without considering the fine-grained class distribution of the target domain. To address these limitations, we propose a Self-supervised Autoregressive Domain Adaptation (SLARDA) framework. In particular, we first design a self-supervised learning module that utilizes forecasting as an auxiliary task to improve the transferability of the source features. Second, we propose a novel autoregressive domain adaptation technique that incorporates temporal dependency of both source and target features during domain alignment. Finally, we develop an ensemble teacher model to align the class-wise distribution in the target domain via a confident pseudo labeling approach. Extensive experiments have been conducted on three real-world time series applications with 30 cross-domain scenarios. Results demonstrate that our proposed SLARDA method significantly outperforms the state-of-the-art approaches for time series domain adaptation.
Adversarial Domain Adaptation with Self-Training for EEG-based Sleep Stage Classification
Jul 09, 2021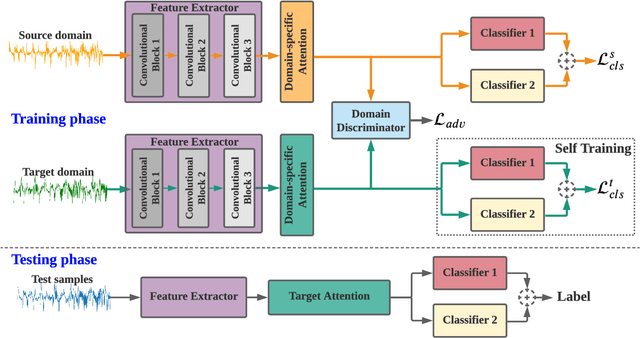
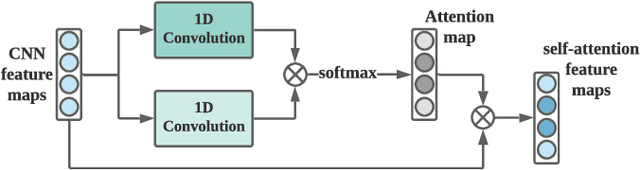


Sleep staging is of great importance in the diagnosis and treatment of sleep disorders. Recently, numerous data driven deep learning models have been proposed for automatic sleep staging. They mainly rely on the assumption that training and testing data are drawn from the same distribution which may not hold in real-world scenarios. Unsupervised domain adaption (UDA) has been recently developed to handle this domain shift problem. However, previous UDA methods applied for sleep staging has two main limitations. First, they rely on a totally shared model for the domain alignment, which may lose the domain-specific information during feature extraction. Second, they only align the source and target distributions globally without considering the class information in the target domain, which hinders the classification performance of the model. In this work, we propose a novel adversarial learning framework to tackle the domain shift problem in the unlabeled target domain. First, we develop unshared attention mechanisms to preserve the domain-specific features in the source and target domains. Second, we design a self-training strategy to align the fine-grained class distributions for the source and target domains via target domain pseudo labels. We also propose dual distinct classifiers to increase the robustness and quality of the pseudo labels. The experimental results on six cross-domain scenarios validate the efficacy of our proposed framework for sleep staging and its advantage over state-of-the-art UDA methods.