 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Volume: Quantifying and Detecting both External and Internal Uncertainty in LLMs
Feb 28, 2025Large language models (LLMs) have demonstrated remarkable performance across diverse tasks by encoding vast amounts of factual knowledge. However, they are still prone to hallucinations, generating incorrect or misleading information, often accompanied by high uncertainty. Existing methods for hallucination detection primarily focus on quantifying internal uncertainty, which arises from missing or conflicting knowledge within the model. However, hallucinations can also stem from external uncertainty, where ambiguous user queries lead to multiple possible interpretations. In this work, we introduce Semantic Volume, a novel mathematical measure for quantifying both external and internal uncertainty in LLMs. Our approach perturbs queries and responses, embeds them in a semantic space, and computes the determinant of the Gram matrix of the embedding vectors, capturing their dispersion as a measure of uncertainty. Our framework provides a generalizable and unsupervised uncertainty detection method without requiring white-box access to LLMs. We conduct extensive experiments on both external and internal uncertainty detection, demonstrating that our Semantic Volume method consistently outperforms existing baselines in both tasks. Additionally, we provide theoretical insights linking our measure to differential entropy, unifying and extending previous sampling-based uncertainty measures such as the semantic entropy. Semantic Volume is shown to be a robust and interpretable approach to improving the reliability of LLMs by systematically detecting uncertainty in both user queries and model responses.
Analysis of Indic Language Capabilities in LLMs
Jan 23, 2025



This report evaluates the performance of text-in text-out Large Language Models (LLMs) to understand and generate Indic languages. This evaluation is used to identify and prioritize Indic languages suited for inclusion in safety benchmarks. We conduct this study by reviewing existing evaluation studies and datasets; and a set of twenty-eight LLMs that support Indic languages. We analyze the LLMs on the basis of the training data, license for model and data, type of access and model developers. We also compare Indic language performance across evaluation datasets and find that significant performance disparities in performance across Indic languages. Hindi is the most widely represented language in models. While model performance roughly correlates with number of speakers for the top five languages, the assessment after that varies.
DARD: A Multi-Agent Approach for Task-Oriented Dialog Systems
Nov 01, 2024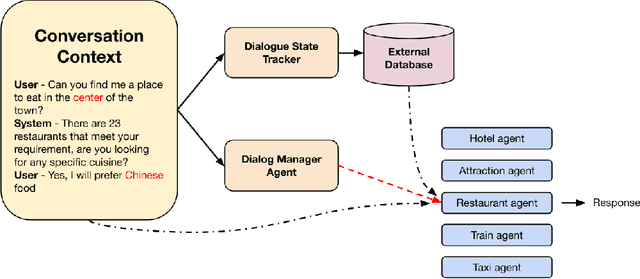
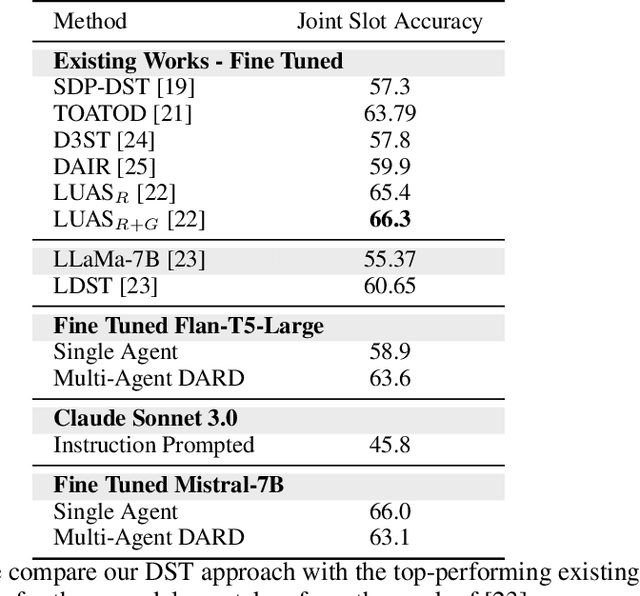
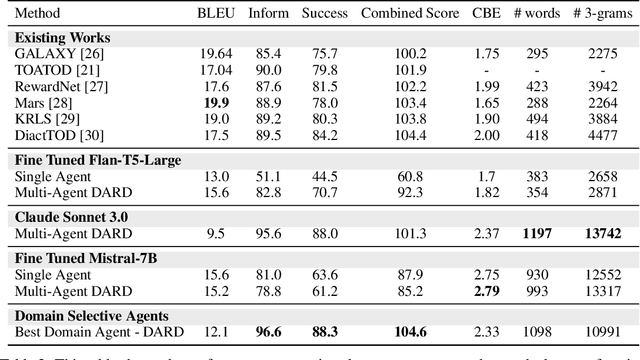

Task-oriented dialogue systems are essential for applications ranging from customer service to personal assistants and are widely used across various industries. However, developing effective multi-domain systems remains a significant challenge due to the complexity of handling diverse user intents, entity types, and domain-specific knowledge across several domains. In this work, we propose DARD (Domain Assigned Response Delegation), a multi-agent conversational system capable of successfully handling multi-domain dialogs. DARD leverages domain-specific agents, orchestrated by a central dialog manager agent. Our extensive experiments compare and utilize various agent modeling approaches, combining the strengths of smaller fine-tuned models (Flan-T5-large & Mistral-7B) with their larger counterparts, Large Language Models (LLMs) (Claude Sonnet 3.0). We provide insights into the strengths and limitations of each approach, highlighting the benefits of our multi-agent framework in terms of flexibility and composability. We evaluate DARD using the well-established MultiWOZ benchmark, achieving state-of-the-art performance by improving the dialogue inform rate by 6.6% and the success rate by 4.1% over the best-performing existing approaches. Additionally, we discuss various annotator discrepancies and issues within the MultiWOZ dataset and its evaluation system.