 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Indic Language Capabilities in LLMs
Jan 23, 2025



This report evaluates the performance of text-in text-out Large Language Models (LLMs) to understand and generate Indic languages. This evaluation is used to identify and prioritize Indic languages suited for inclusion in safety benchmarks. We conduct this study by reviewing existing evaluation studies and datasets; and a set of twenty-eight LLMs that support Indic languages. We analyze the LLMs on the basis of the training data, license for model and data, type of access and model developers. We also compare Indic language performance across evaluation datasets and find that significant performance disparities in performance across Indic languages. Hindi is the most widely represented language in models. While model performance roughly correlates with number of speakers for the top five languages, the assessment after that varies.
Overview of the 2023 ICON Shared Task on Gendered Abuse Detection in Indic Languages
Jan 08, 2024This paper reports the findings of the ICON 2023 on Gendered Abuse Detection in Indic Languages. The shared task deals with the detection of gendered abuse in online text. The shared task was conducted as a part of ICON 2023, based on a novel dataset in Hindi, Tamil and the Indian dialect of English. The participants were given three subtasks with the train dataset consisting of approximately 6500 posts sourced from Twitter. For the test set, approximately 1200 posts were provided. The shared task received a total of 9 registrations. The best F-1 scores are 0.616 for subtask 1, 0.572 for subtask 2 and, 0.616 and 0.582 for subtask 3. The paper contains examples of hateful content owing to its topic.
The Uli Dataset: An Exercise in Experience Led Annotation of oGBV
Nov 15, 2023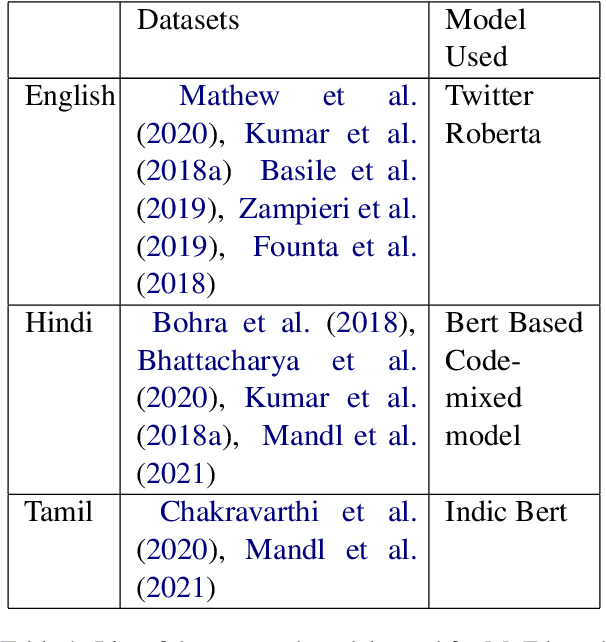
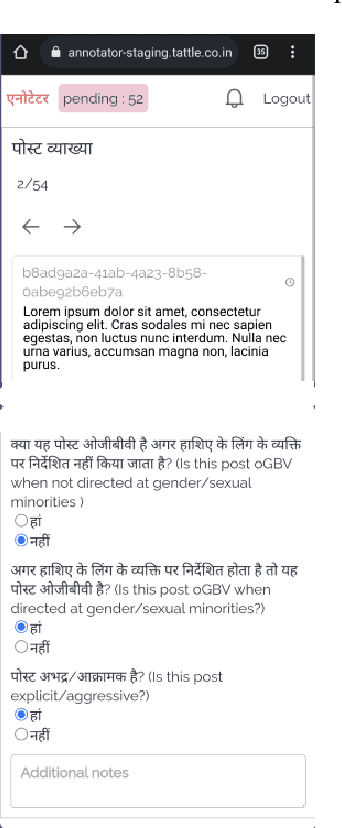
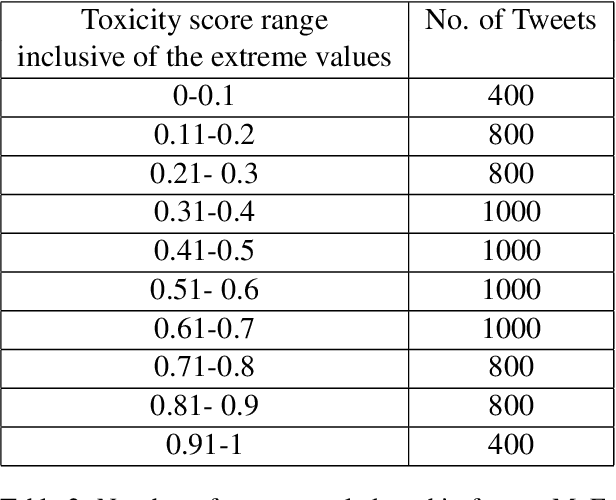

Online gender based violence has grown concomitantly with adoption of the internet and social media. Its effects are worse in the Global majority where many users use social media in languages other than English. The scale and volume of conversations on the internet has necessitated the need for automated detection of hate speech, and more specifically gendered abuse. There is, however, a lack of language specific and contextual data to build such automated tools. In this paper we present a dataset on gendered abuse in three languages- Hindi, Tamil and Indian English. The dataset comprises of tweets annotated along three questions pertaining to the experience of gender abuse, by experts who identify as women or a member of the LGBTQIA community in South Asia. Through this dataset we demonstrate a participatory approach to creating datasets that drive AI systems.