 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Uli Dataset: An Exercise in Experience Led Annotation of oGBV
Nov 15, 2023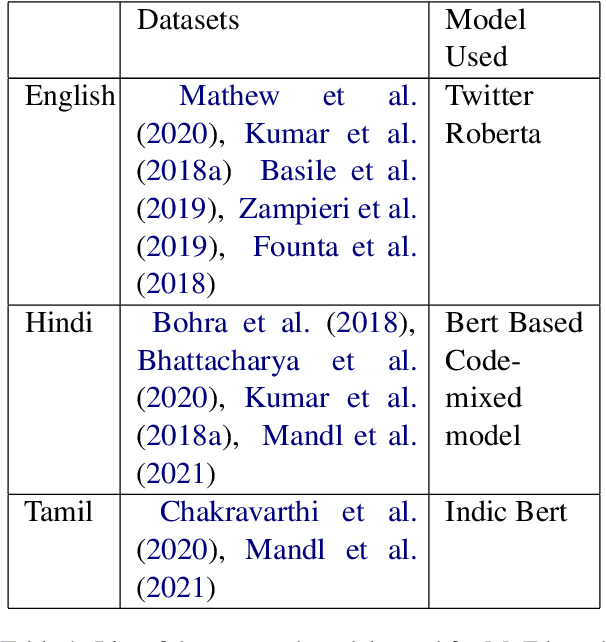
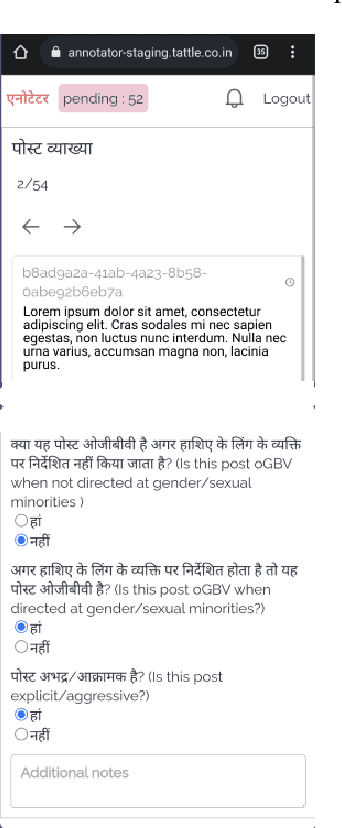
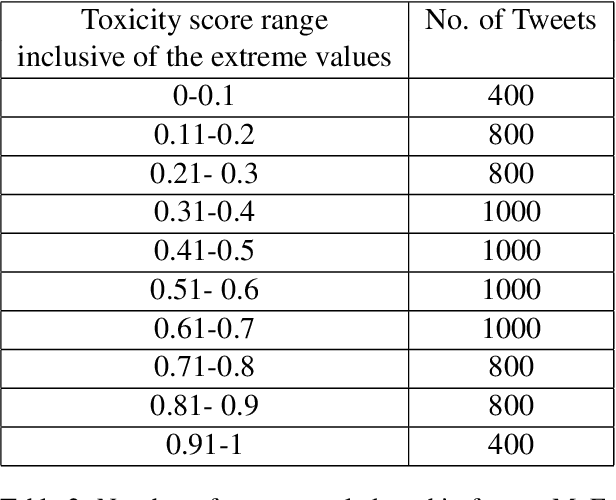

Online gender based violence has grown concomitantly with adoption of the internet and social media. Its effects are worse in the Global majority where many users use social media in languages other than English. The scale and volume of conversations on the internet has necessitated the need for automated detection of hate speech, and more specifically gendered abuse. There is, however, a lack of language specific and contextual data to build such automated tools. In this paper we present a dataset on gendered abuse in three languages- Hindi, Tamil and Indian English. The dataset comprises of tweets annotated along three questions pertaining to the experience of gender abuse, by experts who identify as women or a member of the LGBTQIA community in South Asia. Through this dataset we demonstrate a participatory approach to creating datasets that drive AI systems.