 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaSA: Large Language and Structured Data Assistant
Nov 16, 2024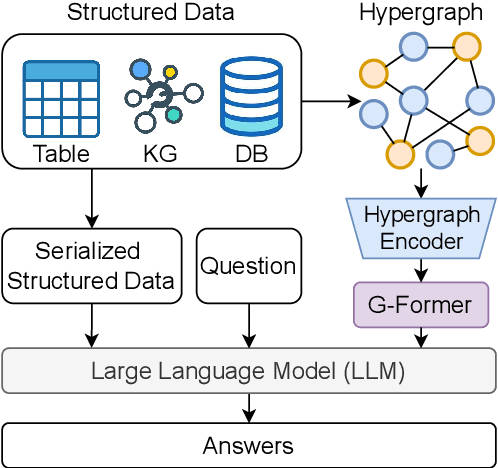
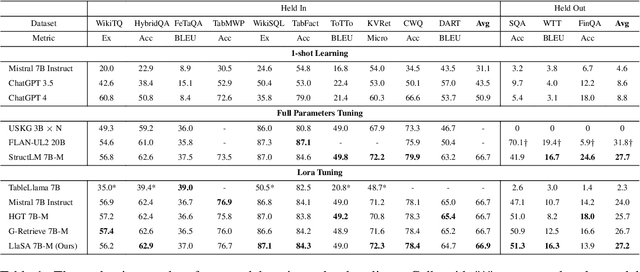
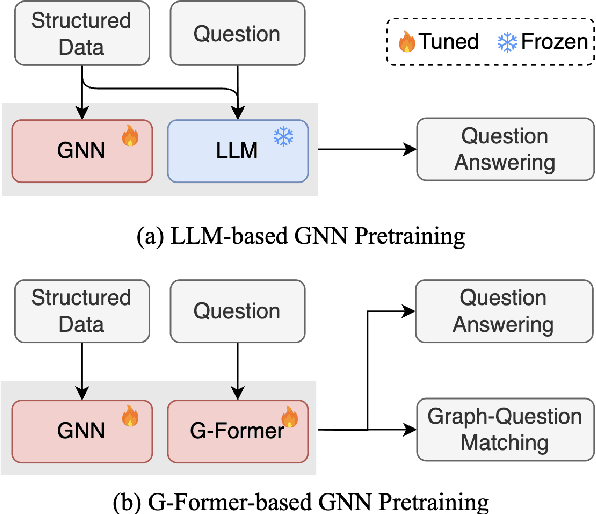
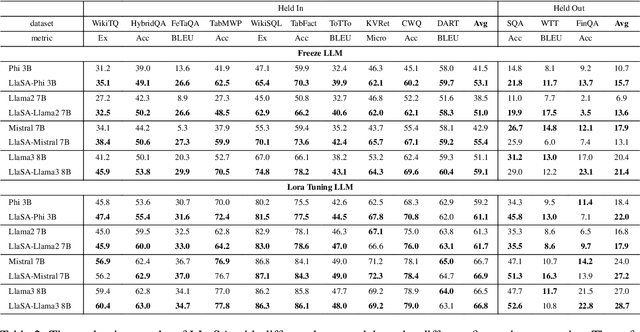
Structured data, such as tables, graphs, and databases, play a critical role in plentiful NLP tasks such as question answering and dialogue system. Recently, inspired by Vision-Language Models, Graph Neutral Networks (GNNs) have been introduced as an additional modality into the input of Large Language Models (LLMs) to improve their performance on Structured Knowledge Grounding (SKG) tasks. However, those GNN-enhanced LLMs have the following limitations: (1) They employ diverse GNNs to model varying types of structured data, rendering them unable to uniformly process various forms of structured data. (2) The pretraining of GNNs is coupled with specific LLMs, which prevents GNNs from fully aligning with the textual space and limits their adaptability to other LLMs. To address these issues, we propose \textbf{L}arge \textbf{L}anguage and \textbf{S}tructured Data \textbf{A}ssistant (LLaSA), a general framework for enhancing LLMs' ability to handle structured data. Specifically, we represent various types of structured data in a unified hypergraph format, and use self-supervised learning to pretrain a hypergraph encoder, and a G-Former compressing encoded hypergraph representations with cross-attention. The compressed hypergraph representations are appended to the serialized inputs during training and inference stages of LLMs. Experimental results on multiple SKG tasks show that our pretrained hypergraph encoder can adapt to various LLMs and enhance their ability to process different types of structured data. Besides, LLaSA, with LoRA fine-tuning, outperforms previous SOTA method using full parameters tuning.