 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multimodal Protein Function Prediction Through Dual-Branch Dynamic Selection with Reconstructive Pre-Training
Nov 06, 2025Multimodal protein features play a crucial role in protein function prediction. However, these features encompass a wide range of information, ranging from structural data and sequence features to protein attributes and interaction networks, making it challenging to decipher their complex interconnections. In this work, we propose a multimodal protein function prediction method (DSRPGO) by utilizing dynamic selection and reconstructive pre-training mechanisms. To acquire complex protein information, we introduce reconstructive pre-training to mine more fine-grained information with low semantic levels. Moreover, we put forward the Bidirectional Interaction Module (BInM) to facilitate interactive learning among multimodal features. Additionally, to address the difficulty of hierarchical multi-label classification in this task, a Dynamic Selection Module (DSM) is designed to select the feature representation that is most conducive to current protein function prediction. Our proposed DSRPGO model improves significantly in BPO, MFO, and CCO on human datasets, thereby outperforming other benchmark models.
Ascend HiFloat8 Format for Deep Learning
Sep 26, 2024



This preliminary white paper proposes a novel 8-bit floating-point data format HiFloat8 (abbreviated as HiF8) for deep learning. HiF8 features tapered precision. For normal value encoding, it provides 7 exponent values with 3-bit mantissa, 8 exponent values with 2-bit mantissa, and 16 exponent values with 1-bit mantissa. For denormal value encoding, it extends the dynamic range by 7 extra powers of 2, from 31 to 38 binades (notice that FP16 covers 40 binades). Meanwhile, HiF8 encodes all the special values except that positive zero and negative zero are represented by only one bit-pattern. Thanks to the better balance between precision and dynamic range, HiF8 can be simultaneously used in both forward and backward passes of AI training. In this paper, we will describe the definition and rounding methods of HiF8, as well as the tentative training and inference solutions. To demonstrate the efficacy of HiF8, massive simulation results on various neural networks, including traditional neural networks and large language models (LLMs), will also be presented.
A Versatile Hub Model For Efficient Information Propagation And Feature Selection
Jul 05, 2023



Hub structure, characterized by a few highly interconnected nodes surrounded by a larger number of nodes with fewer connections, is a prominent topological feature of biological brains, contributing to efficient information transfer and cognitive processing across various species. In this paper, a mathematical model of hub structure is presented. The proposed method is versatile and can be broadly applied to both computational neuroscience and Recurrent Neural Networks (RNNs) research. We employ the Echo State Network (ESN) as a means to investigate the mechanistic underpinnings of hub structures. Our findings demonstrate a substantial enhancement in performance upon incorporating the hub structure. Through comprehensive mechanistic analyses, we show that the hub structure improves model performance by facilitating efficient information processing and better feature extractions.
Fine-Grained Texture Identification for Reliable Product Traceability
Apr 23, 2021
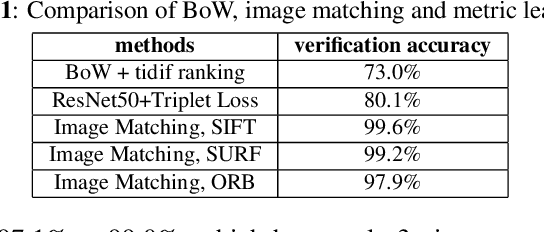
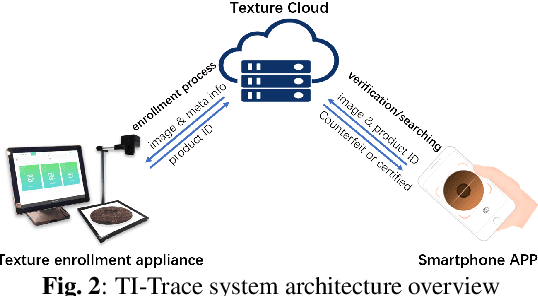

Texture exists in lots of the products, such as wood, beef and compression tea. These abundant and stochastic texture patterns are significantly different between any two products. Unlike the traditional digital ID tracking, in this paper, we propose a novel approach for product traceability, which directly uses the natural texture of the product itself as the unique identifier. A texture identification based traceability system for Pu'er compression tea is developed to demonstrate the feasibility of the proposed solution. With tea-brick images collected from manufactures and individual users, a large-scale dataset has been formed to evaluate the performance of tea-brick texture verification and searching algorithm. The texture similarity approach with local feature extraction and matching achieves the verification accuracy of 99.6% and the top-1 searching accuracy of 98.9%, respectively.
Automatic low-bit hybrid quantization of neural networks through meta learning
Apr 24, 2020



Model quantization is a widely used technique to compress and accelerate deep neural network (DNN) inference, especially when deploying to edge or IoT devices with limited computation capacity and power consumption budget. The uniform bit width quantization across all the layers is usually sub-optimal and the exploration of hybrid quantization for different layers is vital for efficient deep compression. In this paper, we employ the meta learning method to automatically realize low-bit hybrid quantization of neural networks. A MetaQuantNet, together with a Quantization function, are trained to generate the quantized weights for the target DNN. Then, we apply a genetic algorithm to search the best hybrid quantization policy that meets compression constraints. With the best searched quantization policy, we subsequently retrain or finetune to further improve the performance of the quantized target network. Extensive experiments demonstrate the performance of searched hybrid quantization scheme surpass that of uniform bitwidth counterpart. Compared to the existing reinforcement learning (RL) based hybrid quantization search approach that relies on tedious explorations, our meta learning approach is more efficient and effective for any compression requirements since the MetaQuantNet only needs be trained once.
Design Flow of Accelerating Hybrid Extremely Low Bit-width Neural Network in Embedded FPGA
Oct 25, 2018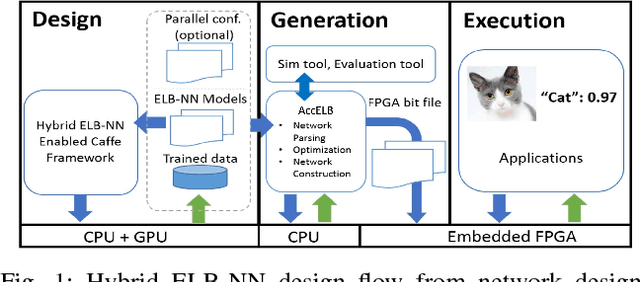
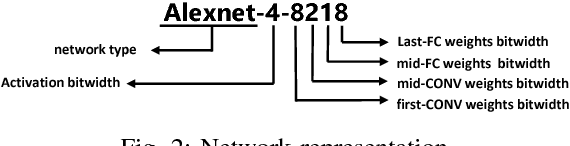
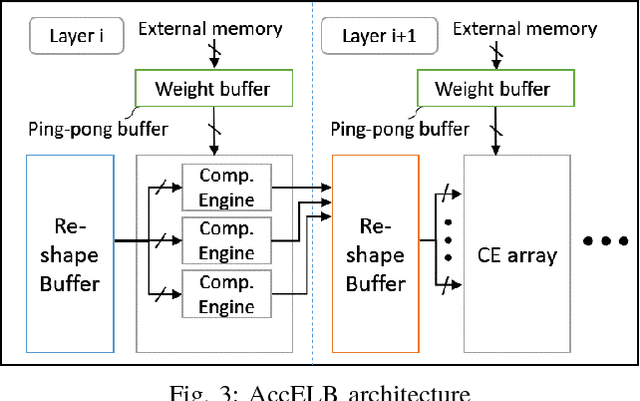
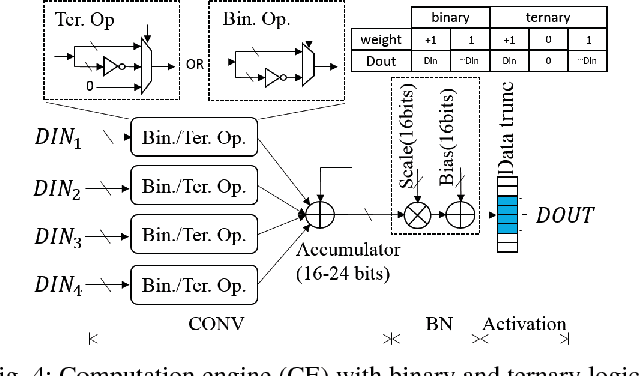
Neural network accelerators with low latency and low energy consumption are desirable for edge computing. To create such accelerators, we propose a design flow for accelerating the extremely low bit-width neural network (ELB-NN) in embedded FPGAs with hybrid quantization schemes. This flow covers both network training and FPGA-based network deployment, which facilitates the design space exploration and simplifies the tradeoff between network accuracy and computation efficiency. Using this flow helps hardware designers to deliver a network accelerator in edge devices under strict resource and power constraints. We present the proposed flow by supporting hybrid ELB settings within a neural network. Results show that our design can deliver very high performance peaking at 10.3 TOPS and classify up to 325.3 image/s/watt while running large-scale neural networks for less than 5W using embedded FPGA. To the best of our knowledge, it is the most energy efficient solution in comparison to GPU or other FPGA implementations reported so far in the literature.