 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Robust RAG: Do We Still Need Complex Robust Training in the Era of Powerful LLMs?
Feb 17, 2025Retrieval-augmented generation (RAG) systems often suffer from performance degradation when encountering noisy or irrelevant documents, driving researchers to develop sophisticated training strategies to enhance their robustness against such retrieval noise. However, as large language models (LLMs) continue to advance, the necessity of these complex training methods is increasingly questioned. In this paper, we systematically investigate whether complex robust training strategies remain necessary as model capacity grows. Through comprehensive experiments spanning multiple model architectures and parameter scales, we evaluate various document selection methods and adversarial training techniques across diverse datasets. Our extensive experiments consistently demonstrate that as models become more powerful, the performance gains brought by complex robust training methods drop off dramatically. We delve into the rationale and find that more powerful models inherently exhibit superior confidence calibration, better generalization across datasets (even when trained with randomly selected documents), and optimal attention mechanisms learned with simpler strategies. Our findings suggest that RAG systems can benefit from simpler architectures and training strategies as models become more powerful, enabling more scalable applications with minimal complexity.
ToolCoder: A Systematic Code-Empowered Tool Learning Framework for Large Language Models
Feb 17, 2025
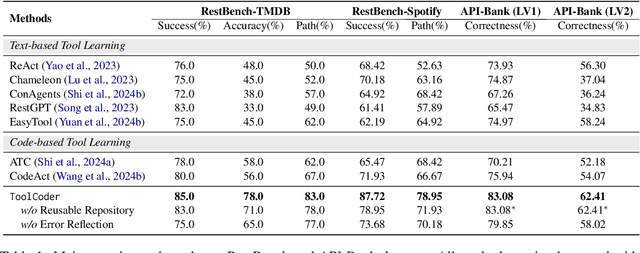
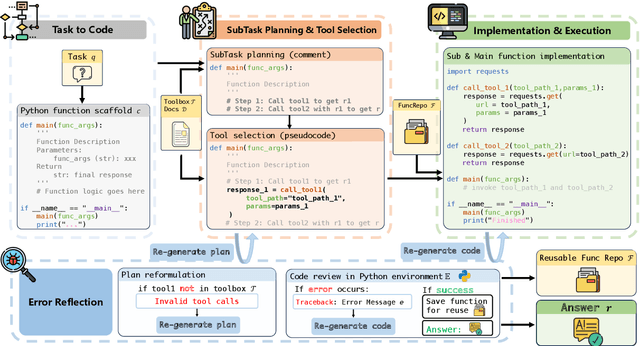
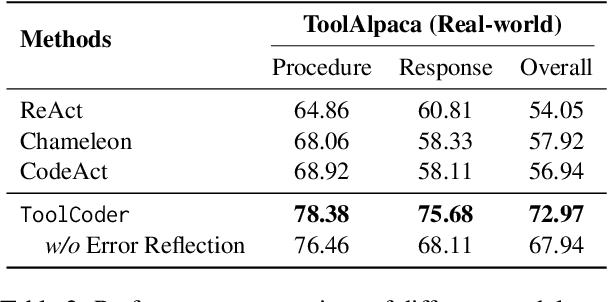
Tool learning has emerged as a crucial capability for large language models (LLMs) to solve complex real-world tasks through interaction with external tools. Existing approaches face significant challenges, including reliance on hand-crafted prompts, difficulty in multi-step planning, and lack of precise error diagnosis and reflection mechanisms. We propose ToolCoder, a novel framework that reformulates tool learning as a code generation task. Inspired by software engineering principles, ToolCoder transforms natural language queries into structured Python function scaffold and systematically breaks down tasks with descriptive comments, enabling LLMs to leverage coding paradigms for complex reasoning and planning. It then generates and executes function implementations to obtain final responses. Additionally, ToolCoder stores successfully executed functions in a repository to promote code reuse, while leveraging error traceback mechanisms for systematic debugging, optimizing both execution efficiency and robustness. Experiments demonstrate that ToolCoder achieves superior performance in task completion accuracy and execution reliability compared to existing approaches, establishing the effectiveness of code-centric approaches in tool learning.
UnKE: Unstructured Knowledge Editing in Large Language Models
May 24, 2024



Recent knowledge editing methods have primarily focused on modifying structured knowledge in large language models, heavily relying on the assumption that structured knowledge is stored as key-value pairs locally in MLP layers or specific neurons. However, this task setting overlooks the fact that a significant portion of real-world knowledge is stored in an unstructured format, characterized by long-form content, noise, and a complex yet comprehensive nature. The "knowledge locating" and "term-driven optimization" techniques conducted from the assumption used in previous methods (e.g., MEMIT) are ill-suited for unstructured knowledge. To address these challenges, we propose a novel unstructured knowledge editing method, namely UnKE, which extends previous assumptions in the layer dimension and token dimension. Firstly, in the layer dimension, we discard the "knowledge locating" step and treat first few layers as the key, which expand knowledge storage through layers to break the "knowledge stored locally" assumption. Next, we replace "term-driven optimization" with "cause-driven optimization" across all inputted tokens in the token dimension, directly optimizing the last layer of the key generator to perform editing to generate the required key vectors. By utilizing key-value pairs at the layer level, UnKE effectively represents and edits complex and comprehensive unstructured knowledge, leveraging the potential of both the MLP and attention layers. Results on newly proposed unstructure knowledge editing dataset (UnKEBench) and traditional structured datasets demonstrate that UnKE achieves remarkable performance, surpassing strong baselines.
When to Trust LLMs: Aligning Confidence with Response Quality
Apr 26, 2024Despite the success of large language models (LLMs) in natural language generation, much evidence shows that LLMs may produce incorrect or nonsensical text. This limitation highlights the importance of discerning when to trust LLMs, especially in safety-critical domains. Existing methods, which rely on verbalizing confidence to tell the reliability by inducing top-k responses and sampling-aggregating multiple responses, often fail, due to the lack of objective guidance of confidence. To address this, we propose CONfidence-Quality-ORDerpreserving alignment approach (CONQORD), leveraging reinforcement learning with a tailored dual-component reward function. This function encompasses quality reward and orderpreserving alignment reward functions. Specifically, the order-preserving reward incentivizes the model to verbalize greater confidence for responses of higher quality to align the order of confidence and quality. Experiments demonstrate that our CONQORD significantly improves the alignment performance between confidence levels and response accuracy, without causing the model to become over-cautious. Furthermore, the aligned confidence provided by CONQORD informs when to trust LLMs, and acts as a determinant for initiating the retrieval process of external knowledge. Aligning confidence with response quality ensures more transparent and reliable responses, providing better trustworthiness.
MLaKE: Multilingual Knowledge Editing Benchmark for Large Language Models
Apr 07, 2024



The extensive utilization of large language models (LLMs) underscores the crucial necessity for precise and contemporary knowledge embedded within their intrinsic parameters. Existing research on knowledge editing primarily concentrates on monolingual scenarios, neglecting the complexities presented by multilingual contexts and multi-hop reasoning. To address these challenges, our study introduces MLaKE (Multilingual Language Knowledge Editing), a novel benchmark comprising 4072 multi-hop and 5360 single-hop questions designed to evaluate the adaptability of knowledge editing methods across five languages: English, Chinese, Japanese, French, and German. MLaKE aggregates fact chains from Wikipedia across languages and utilizes LLMs to generate questions in both free-form and multiple-choice. We evaluate the multilingual knowledge editing generalization capabilities of existing methods on MLaKE. Existing knowledge editing methods demonstrate higher success rates in English samples compared to other languages. However, their generalization capabilities are limited in multi-language experiments. Notably, existing knowledge editing methods often show relatively high generalization for languages within the same language family compared to languages from different language families. These results underscore the imperative need for advancements in multilingual knowledge editing and we hope MLaKE can serve as a valuable resource for benchmarking and solution development.
Stable Knowledge Editing in Large Language Models
Feb 20, 2024


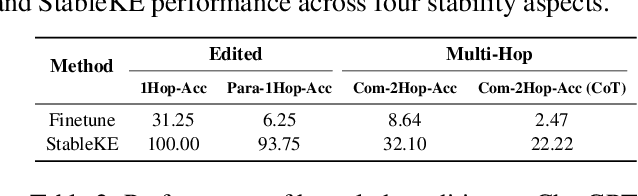
Efficient knowledge editing of large language models is crucial for replacing obsolete information or incorporating specialized knowledge on a large scale. However, previous methods implicitly assume that knowledge is localized and isolated within the model, an assumption that oversimplifies the interconnected nature of model knowledge. The premise of localization results in an incomplete knowledge editing, whereas an isolated assumption may impair both other knowledge and general abilities. It introduces instability to the performance of the knowledge editing method. To transcend these assumptions, we introduce StableKE, a method adopts a novel perspective based on knowledge augmentation rather than knowledge localization. To overcome the expense of human labeling, StableKE integrates two automated knowledge augmentation strategies: Semantic Paraphrase Enhancement strategy, which diversifies knowledge descriptions to facilitate the teaching of new information to the model, and Contextual Description Enrichment strategy, expanding the surrounding knowledge to prevent the forgetting of related information. StableKE surpasses other knowledge editing methods, demonstrating stability both edited knowledge and multi-hop knowledge, while also preserving unrelated knowledge and general abilities. Moreover, StableKE can edit knowledge on ChatGPT.
Retrieve Only When It Needs: Adaptive Retrieval Augmentation for Hallucination Mitigation in Large Language Models
Feb 16, 2024



Hallucinations pose a significant challenge for the practical implementation of large language models (LLMs). The utilization of parametric knowledge in generating factual content is constrained by the limited knowledge of LLMs, potentially resulting in internal hallucinations. While incorporating external information can help fill knowledge gaps, it also introduces the risk of irrelevant information, thereby increasing the likelihood of external hallucinations. A careful and balanced integration of the parametric knowledge within LLMs with external information is crucial to alleviate hallucinations. In this study, we present Rowen, a novel approach that enhances LLMs with a selective retrieval augmentation process tailored to address hallucinated outputs. This process is governed by a multilingual semantic-aware detection module, which evaluates the consistency of the perturbed responses across various languages for the same queries. Upon detecting inconsistencies indicative of hallucinations, Rowen activates the retrieval of external information to rectify the model outputs. Rowen adeptly harmonizes the intrinsic parameters in LLMs with external knowledge sources, effectively mitigating hallucinations by ensuring a balanced integration of internal reasoning and external evidence. Through a comprehensive empirical analysis, we demonstrate that Rowen surpasses the current state-of-the-art in both detecting and mitigating hallucinated content within the outputs of LLMs.
MacLaSa: Multi-Aspect Controllable Text Generation via Efficient Sampling from Compact Latent Space
May 22, 2023Multi-aspect controllable text generation aims to generate fluent sentences that possess multiple desired attributes simultaneously. Traditional methods either combine many operators in the decoding stage, often with costly iteration or search in the discrete text space, or train separate controllers for each aspect, resulting in a degeneration of text quality due to the discrepancy between different aspects. To address these limitations, we introduce a novel approach for multi-aspect control, namely MacLaSa, that estimates compact latent space for multiple aspects and performs efficient sampling with a robust sampler based on ordinary differential equations (ODEs). To eliminate the domain gaps between different aspects, we utilize a Variational Autoencoder (VAE) network to map text sequences from varying data sources into close latent representations. The estimated latent space enables the formulation of joint energy-based models (EBMs) and the plugging in of arbitrary attribute discriminators to achieve multi-aspect control. Afterwards, we draw latent vector samples with an ODE-based sampler and feed sampled examples to the VAE decoder to produce target text sequences. Experimental results demonstrate that MacLaSa outperforms several strong baselines on attribute relevance and textual quality while maintaining a high inference speed.