 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Malicious Concepts Without Image Generation in AIGC
Feb 13, 2025The task of text-to-image generation has achieved tremendous success in practice, with emerging concept generation models capable of producing highly personalized and customized content. Fervor for concept generation is increasing rapidly among users, and platforms for concept sharing have sprung up. The concept owners may upload malicious concepts and disguise them with non-malicious text descriptions and example images to deceive users into downloading and generating malicious content. The platform needs a quick method to determine whether a concept is malicious to prevent the spread of malicious concepts. However, simply relying on concept image generation to judge whether a concept is malicious requires time and computational resources. Especially, as the number of concepts uploaded and downloaded on the platform continues to increase, this approach becomes impractical and poses a risk of generating malicious content. In this paper, we propose Concept QuickLook, the first systematic work to incorporate malicious concept detection into research, which performs detection based solely on concept files without generating any images. We define malicious concepts and design two work modes for detection: concept matching and fuzzy detection. Extensive experiments demonstrate that the proposed Concept QuickLook can detect malicious concepts and demonstrate practicality in concept sharing platforms. We also design robustness experiments to further validate the effectiveness of the solution. We hope this work can initiate malicious concept detection tasks and provide some inspiration.
Rethink Deep Learning with Invariance in Data Representation
Dec 06, 2024Integrating invariance into data representations is a principled design in intelligent systems and web applications. Representations play a fundamental role, where systems and applications are both built on meaningful representations of digital inputs (rather than the raw data). In fact, the proper design/learning of such representations relies on priors w.r.t. the task of interest. Here, the concept of symmetry from the Erlangen Program may be the most fruitful prior -- informally, a symmetry of a system is a transformation that leaves a certain property of the system invariant. Symmetry priors are ubiquitous, e.g., translation as a symmetry of the object classification, where object category is invariant under translation. The quest for invariance is as old as pattern recognition and data mining itself. Invariant design has been the cornerstone of various representations in the era before deep learning, such as the SIFT. As we enter the early era of deep learning, the invariance principle is largely ignored and replaced by a data-driven paradigm, such as the CNN. However, this neglect did not last long before they encountered bottlenecks regarding robustness, interpretability, efficiency, and so on. The invariance principle has returned in the era of rethinking deep learning, forming a new field known as Geometric Deep Learning (GDL). In this tutorial, we will give a historical perspective of the invariance in data representations. More importantly, we will identify those research dilemmas, promising works, future directions, and web applications.
Hierarchical Invariance for Robust and Interpretable Vision Tasks at Larger Scales
Feb 23, 2024
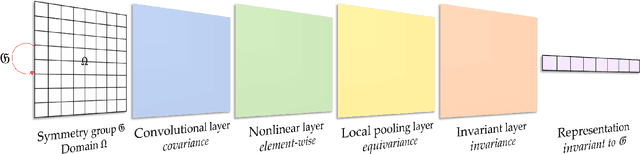
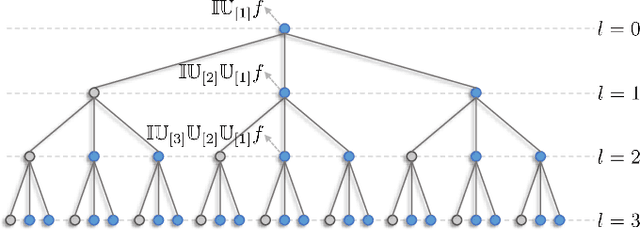
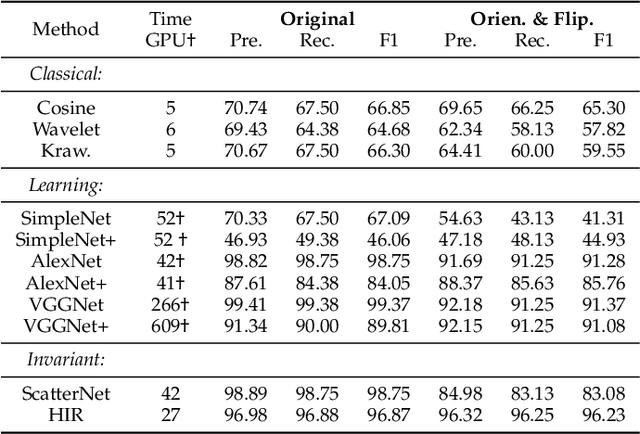
Developing robust and interpretable vision systems is a crucial step towards trustworthy artificial intelligence. In this regard, a promising paradigm considers embedding task-required invariant structures, e.g., geometric invariance, in the fundamental image representation. However, such invariant representations typically exhibit limited discriminability, limiting their applications in larger-scale trustworthy vision tasks. For this open problem, we conduct a systematic investigation of hierarchical invariance, exploring this topic from theoretical, practical, and application perspectives. At the theoretical level, we show how to construct over-complete invariants with a Convolutional Neural Networks (CNN)-like hierarchical architecture yet in a fully interpretable manner. The general blueprint, specific definitions, invariant properties, and numerical implementations are provided. At the practical level, we discuss how to customize this theoretical framework into a given task. With the over-completeness, discriminative features w.r.t. the task can be adaptively formed in a Neural Architecture Search (NAS)-like manner. We demonstrate the above arguments with accuracy, invariance, and efficiency results on texture, digit, and parasite classification experiments. Furthermore, at the application level, our representations are explored in real-world forensics tasks on adversarial perturbations and Artificial Intelligence Generated Content (AIGC). Such applications reveal that the proposed strategy not only realizes the theoretically promised invariance, but also exhibits competitive discriminability even in the era of deep learning. For robust and interpretable vision tasks at larger scales, hierarchical invariant representation can be considered as an effective alternative to traditional CNN and invariants.
Towards an Accurate and Secure Detector against Adversarial Perturbations
May 18, 2023The vulnerability of deep neural networks to adversarial perturbations has been widely perceived in the computer vision community. From a security perspective, it poses a critical risk for modern vision systems, e.g., the popular Deep Learning as a Service (DLaaS) frameworks. For protecting off-the-shelf deep models while not modifying them, current algorithms typically detect adversarial patterns through discriminative decomposition of natural-artificial data. However, these decompositions are biased towards frequency or spatial discriminability, thus failing to capture subtle adversarial patterns comprehensively. More seriously, they are typically invertible, meaning successful defense-aware (secondary) adversarial attack (i.e., evading the detector as well as fooling the model) is practical under the assumption that the adversary is fully aware of the detector (i.e., the Kerckhoffs's principle). Motivated by such facts, we propose an accurate and secure adversarial example detector, relying on a spatial-frequency discriminative decomposition with secret keys. It expands the above works on two aspects: 1) the introduced Krawtchouk basis provides better spatial-frequency discriminability and thereby is more suitable for capturing adversarial patterns than the common trigonometric or wavelet basis; 2) the extensive parameters for decomposition are generated by a pseudo-random function with secret keys, hence blocking the defense-aware adversarial attack. Theoretical and numerical analysis demonstrates the increased accuracy and security of our detector w.r.t. a number of state-of-the-art algorithms.
Representing Noisy Image Without Denoising
Jan 18, 2023A long-standing topic in artificial intelligence is the effective recognition of patterns from noisy images. In this regard, the recent data-driven paradigm considers 1) improving the representation robustness by adding noisy samples in training phase (i.e., data augmentation) or 2) pre-processing the noisy image by learning to solve the inverse problem (i.e., image denoising). However, such methods generally exhibit inefficient process and unstable result, limiting their practical applications. In this paper, we explore a non-learning paradigm that aims to derive robust representation directly from noisy images, without the denoising as pre-processing. Here, the noise-robust representation is designed as Fractional-order Moments in Radon space (FMR), with also beneficial properties of orthogonality and rotation invariance. Unlike earlier integer-order methods, our work is a more generic design taking such classical methods as special cases, and the introduced fractional-order parameter offers time-frequency analysis capability that is not available in classical methods. Formally, both implicit and explicit paths for constructing the FMR are discussed in detail. Extensive simulation experiments and an image security application are provided to demonstrate the uniqueness and usefulness of our FMR, especially for noise robustness, rotation invariance, and time-frequency discriminability.
Shrinking the Semantic Gap: Spatial Pooling of Local Moment Invariants for Copy-Move Forgery Detection
Jul 19, 2022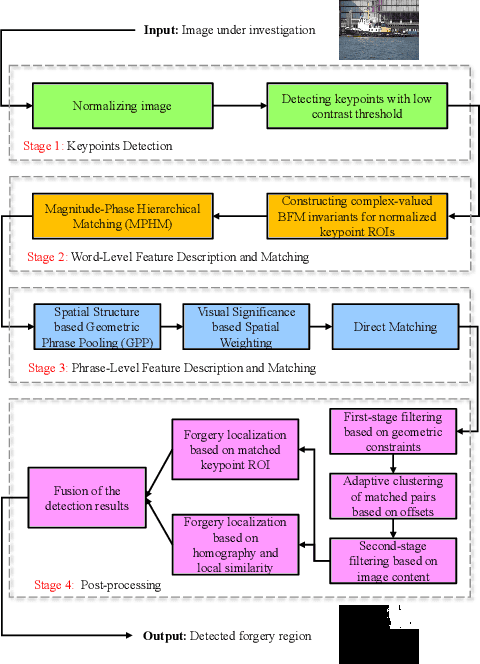
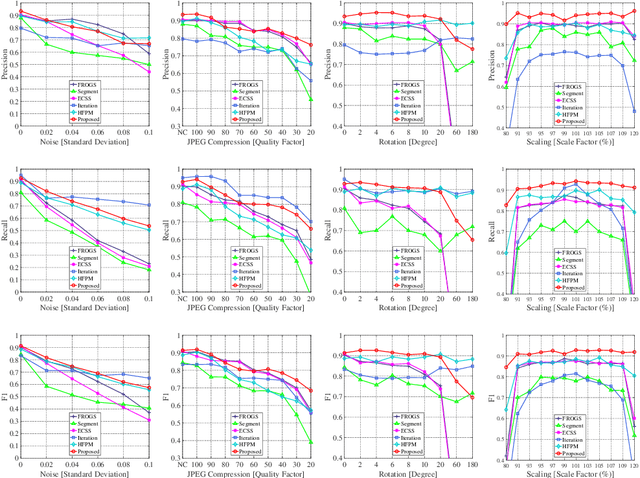
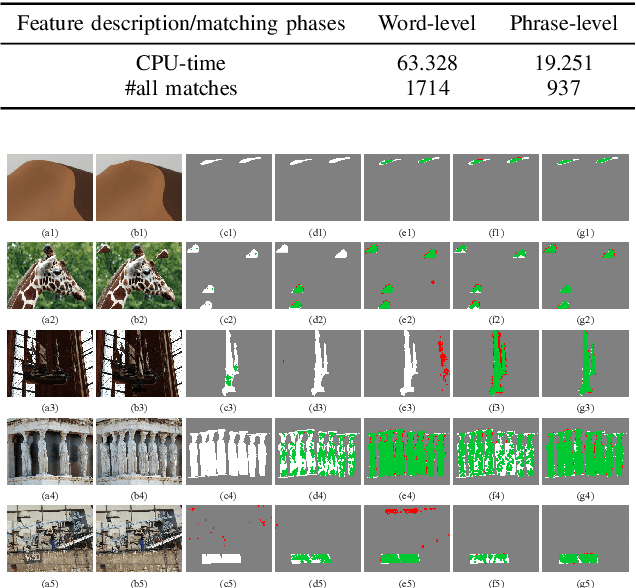

Copy-move forgery is a manipulation of copying and pasting specific patches from and to an image, with potentially illegal or unethical uses. Recent advances in the forensic methods for copy-move forgery have shown increasing success in detection accuracy and robustness. However, for images with high self-similarity or strong signal corruption, the existing algorithms often exhibit inefficient processes and unreliable results. This is mainly due to the inherent semantic gap between low-level visual representation and high-level semantic concept. In this paper, we present a very first study of trying to mitigate the semantic gap problem in copy-move forgery detection, with spatial pooling of local moment invariants for midlevel image representation. Our detection method expands the traditional works on two aspects: 1) we introduce the bag-of-visual-words model into this field for the first time, may meaning a new perspective of forensic study; 2) we propose a word-to-phrase feature description and matching pipeline, covering the spatial structure and visual saliency information of digital images. Extensive experimental results show the superior performance of our framework over state-of-the-art algorithms in overcoming the related problems caused by the semantic gap.
Detecting Recolored Image by Spatial Correlation
Apr 23, 2022


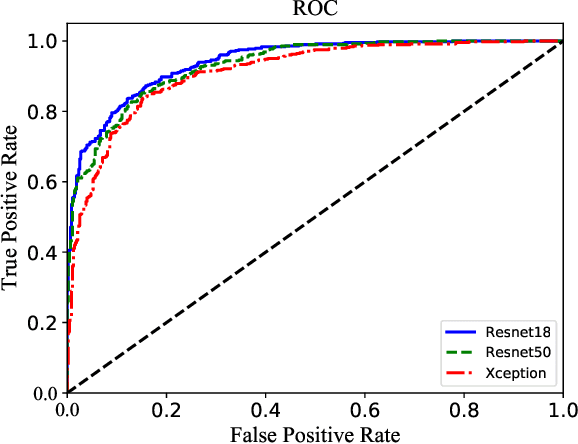
Image forensics, aiming to ensure the authenticity of the image, has made great progress in dealing with common image manipulation such as copy-move, splicing, and inpainting in the past decades. However, only a few researchers pay attention to an emerging editing technique called image recoloring, which can manipulate the color values of an image to give it a new style. To prevent it from being used maliciously, the previous approaches address the conventional recoloring from the perspective of inter-channel correlation and illumination consistency. In this paper, we try to explore a solution from the perspective of the spatial correlation, which exhibits the generic detection capability for both conventional and deep learning-based recoloring. Through theoretical and numerical analysis, we find that the recoloring operation will inevitably destroy the spatial correlation between pixels, implying a new prior of statistical discriminability. Based on such fact, we generate a set of spatial correlation features and learn the informative representation from the set via a convolutional neural network. To train our network, we use three recoloring methods to generate a large-scale and high-quality data set. Extensive experimental results in two recoloring scenes demonstrate that the spatial correlation features are highly discriminative. Our method achieves the state-of-the-art detection accuracy on multiple benchmark datasets and exhibits well generalization for unknown types of recoloring methods.
A Principled Design of Image Representation: Towards Forensic Tasks
Mar 02, 2022



Image forensics is a rising topic as the trustworthy multimedia content is critical for modern society. Like other vision-related applications, forensic analysis relies heavily on the proper image representation. Despite the importance, current theoretical understanding for such representation remains limited, with varying degrees of neglect for its key role. For this gap, we attempt to investigate the forensic-oriented image representation as a distinct problem, from the perspectives of theory, implementation, and application. Our work starts from the abstraction of basic principles that the representation for forensics should satisfy, especially revealing the criticality of robustness, interpretability, and coverage. At the theoretical level, we propose a new representation framework for forensics, called Dense Invariant Representation (DIR), which is characterized by stable description with mathematical guarantees. At the implementation level, the discrete calculation problems of DIR are discussed, and the corresponding accurate and fast solutions are designed with generic nature and constant complexity. We demonstrate the above arguments on the dense-domain pattern detection and matching experiments, providing comparison results with state-of-the-art descriptors. Also, at the application level, the proposed DIR is initially explored in passive and active forensics, namely copy-move forgery detection and perceptual hashing, exhibiting the benefits in fulfilling the requirements of such forensic tasks.
A Survey of Orthogonal Moments for Image Representation: Theory, Implementation, and Evaluation
Mar 27, 2021
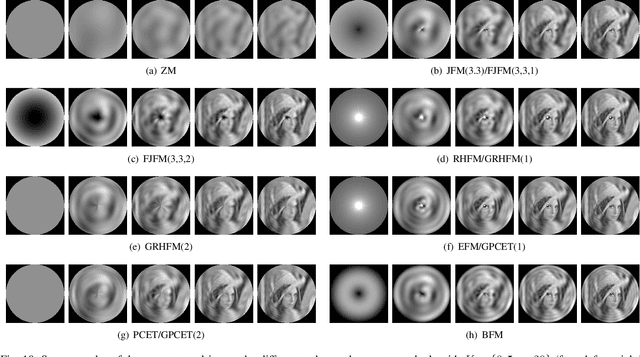


Image representation is an important topic in computer vision and pattern recognition. It plays a fundamental role in a range of applications towards understanding visual contents. Moment-based image representation has been reported to be effective in satisfying the core conditions of semantic description due to its beneficial mathematical properties, especially geometric invariance and independence. This paper presents a comprehensive survey of the orthogonal moments for image representation, covering recent advances in fast/accurate calculation, robustness/invariance optimization, and definition extension. We also create a software package for a variety of widely-used orthogonal moments and evaluate such methods in a same base. The presented theory analysis, software implementation, and evaluation results can support the community, particularly in developing novel techniques and promoting real-world applications.