 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShrinking the Semantic Gap: Spatial Pooling of Local Moment Invariants for Copy-Move Forgery Detection
Paper and Code
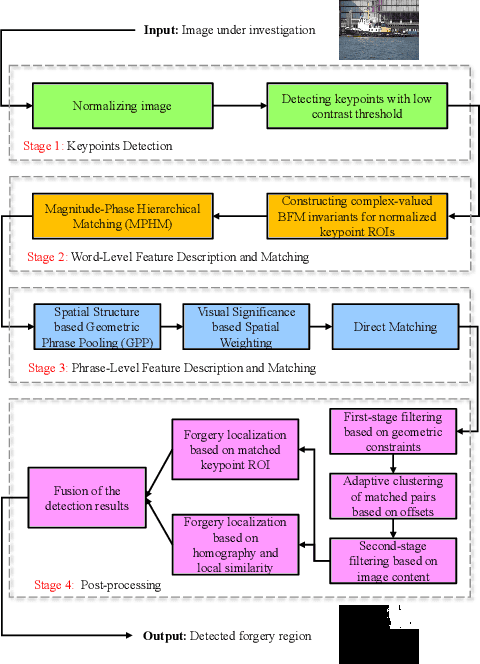
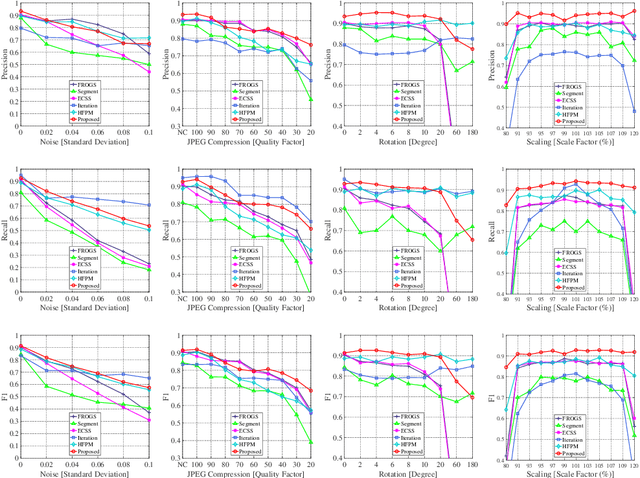
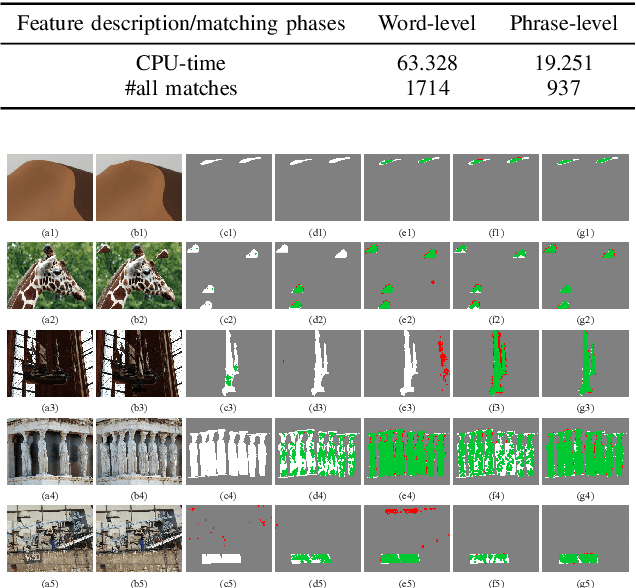

Copy-move forgery is a manipulation of copying and pasting specific patches from and to an image, with potentially illegal or unethical uses. Recent advances in the forensic methods for copy-move forgery have shown increasing success in detection accuracy and robustness. However, for images with high self-similarity or strong signal corruption, the existing algorithms often exhibit inefficient processes and unreliable results. This is mainly due to the inherent semantic gap between low-level visual representation and high-level semantic concept. In this paper, we present a very first study of trying to mitigate the semantic gap problem in copy-move forgery detection, with spatial pooling of local moment invariants for midlevel image representation. Our detection method expands the traditional works on two aspects: 1) we introduce the bag-of-visual-words model into this field for the first time, may meaning a new perspective of forensic study; 2) we propose a word-to-phrase feature description and matching pipeline, covering the spatial structure and visual saliency information of digital images. Extensive experimental results show the superior performance of our framework over state-of-the-art algorithms in overcoming the related problems caused by the semantic gap.