 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgesPhinX: Sample Efficient Multilingual Instruction Fine-Tuning Through N-shot Guided Prompting
Jul 16, 2024Despite the remarkable success of LLMs in English, there is a significant gap in performance in non-English languages. In order to address this, we introduce a novel recipe for creating a multilingual synthetic instruction tuning dataset, sPhinX, which is created by selectively translating instruction response pairs from English into 50 languages. We test the effectiveness of sPhinX by using it to fine-tune two state-of-the-art models, Phi-3-small and Mistral-7B and then evaluating them across a comprehensive suite of multilingual benchmarks that test reasoning, question answering, and reading comprehension. Our results show that Phi-3-small and Mistral-7B fine-tuned with sPhinX perform better on an average by 4.2%pt and 5%pt respectively as compared to the baselines. We also devise a strategy to incorporate N-shot examples in each fine-tuning sample which further boosts the performance of these models by 3%pt and 10%pt respectively. Additionally, sPhinX also outperforms other multilingual instruction tuning datasets on the same benchmarks along with being sample efficient and diverse, thereby reducing dataset creation costs. Additionally, instruction tuning with sPhinX does not lead to regression on most standard LLM benchmarks.
Semi-Structured Object Sequence Encoders
Jan 10, 2023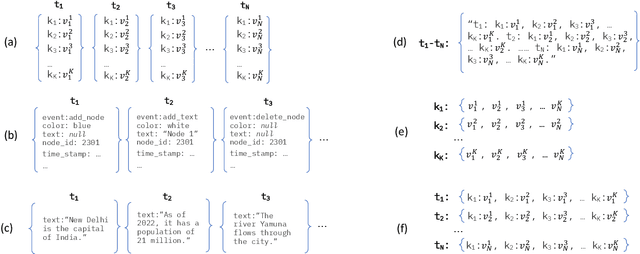

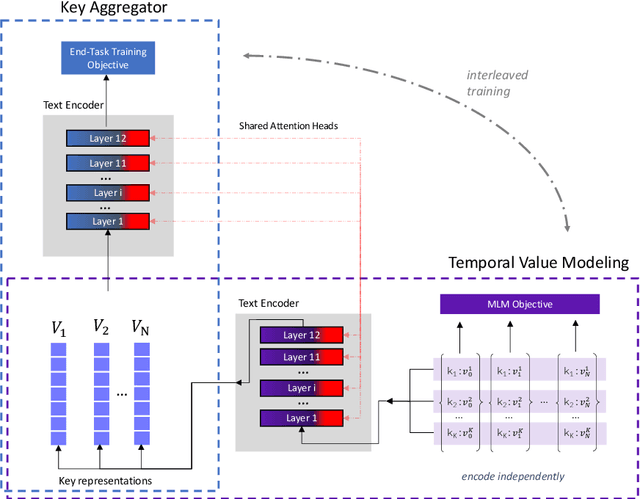
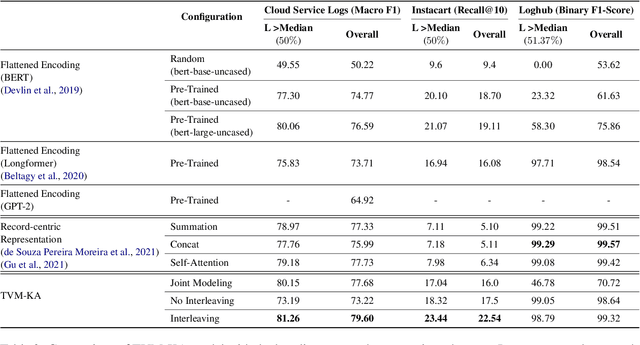
In this paper we explore the task of modeling (semi) structured object sequences; in particular we focus our attention on the problem of developing a structure-aware input representation for such sequences. In such sequences, we assume that each structured object is represented by a set of key-value pairs which encode the attributes of the structured object. Given a universe of keys, a sequence of structured objects can then be viewed as an evolution of the values for each key, over time. We encode and construct a sequential representation using the values for a particular key (Temporal Value Modeling - TVM) and then self-attend over the set of key-conditioned value sequences to a create a representation of the structured object sequence (Key Aggregation - KA). We pre-train and fine-tune the two components independently and present an innovative training schedule that interleaves the training of both modules with shared attention heads. We find that this iterative two part-training results in better performance than a unified network with hierarchical encoding as well as over, other methods that use a {\em record-view} representation of the sequence \cite{de2021transformers4rec} or a simple {\em flattened} representation of the sequence. We conduct experiments using real-world data to demonstrate the advantage of interleaving TVM-KA on multiple tasks and detailed ablation studies motivating our modeling choices. We find that our approach performs better than flattening sequence objects and also allows us to operate on significantly larger sequences than existing methods.
Role of Language Relatedness in Multilingual Fine-tuning of Language Models: A Case Study in Indo-Aryan Languages
Sep 22, 2021
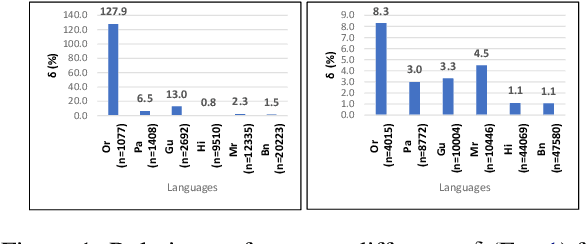

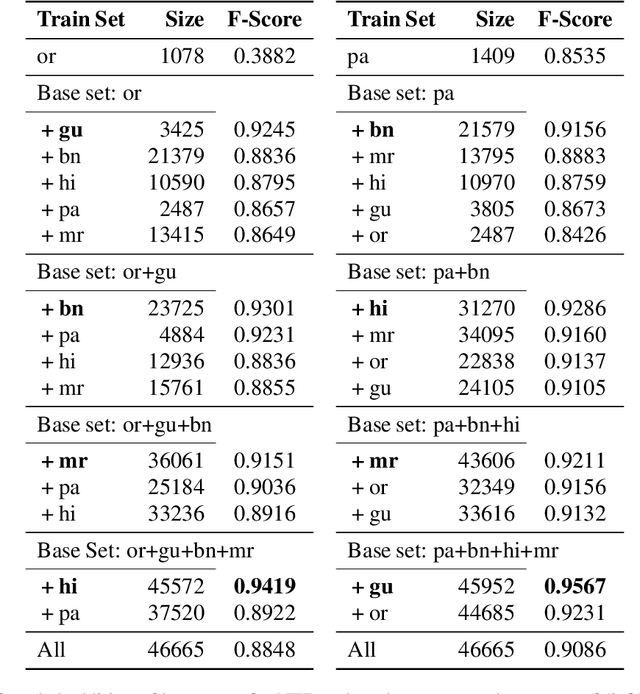
We explore the impact of leveraging the relatedness of languages that belong to the same family in NLP models using multilingual fine-tuning. We hypothesize and validate that multilingual fine-tuning of pre-trained language models can yield better performance on downstream NLP applications, compared to models fine-tuned on individual languages. A first of its kind detailed study is presented to track performance change as languages are added to a base language in a graded and greedy (in the sense of best boost of performance) manner; which reveals that careful selection of subset of related languages can significantly improve performance than utilizing all related languages. The Indo-Aryan (IA) language family is chosen for the study, the exact languages being Bengali, Gujarati, Hindi, Marathi, Oriya, Punjabi and Urdu. The script barrier is crossed by simple rule-based transliteration of the text of all languages to Devanagari. Experiments are performed on mBERT, IndicBERT, MuRIL and two RoBERTa-based LMs, the last two being pre-trained by us. Low resource languages, such as Oriya and Punjabi, are found to be the largest beneficiaries of multilingual fine-tuning. Textual Entailment, Entity Classification, Section Title Prediction, tasks of IndicGLUE and POS tagging form our test bed. Compared to monolingual fine tuning we get relative performance improvement of up to 150% in the downstream tasks. The surprise take-away is that for any language there is a particular combination of other languages which yields the best performance, and any additional language is in fact detrimental.