 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-User Chat Assistant : a Framework Using LLMs to Facilitate Group Conversations
Jan 10, 2024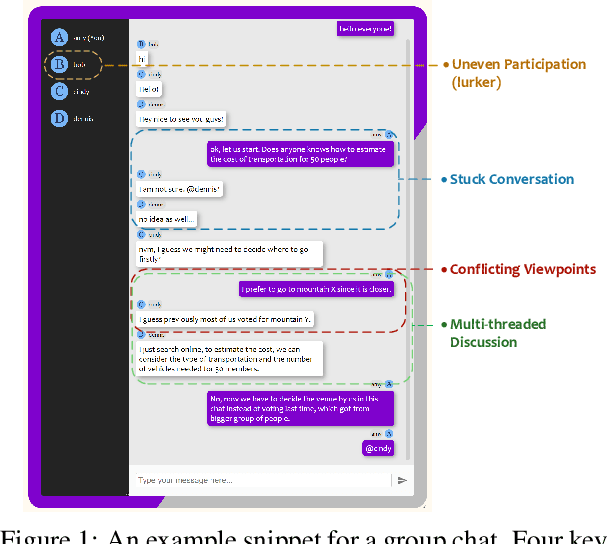
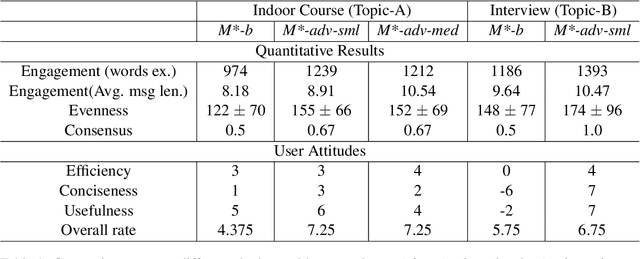
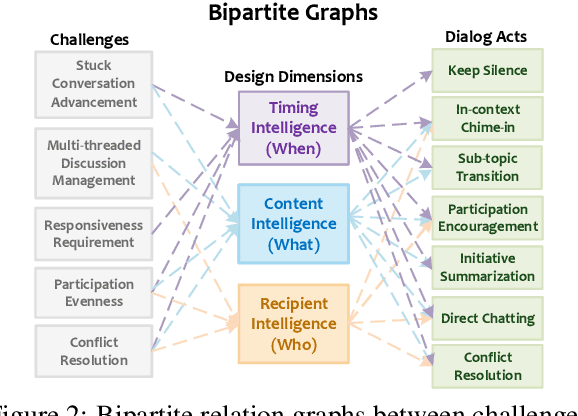
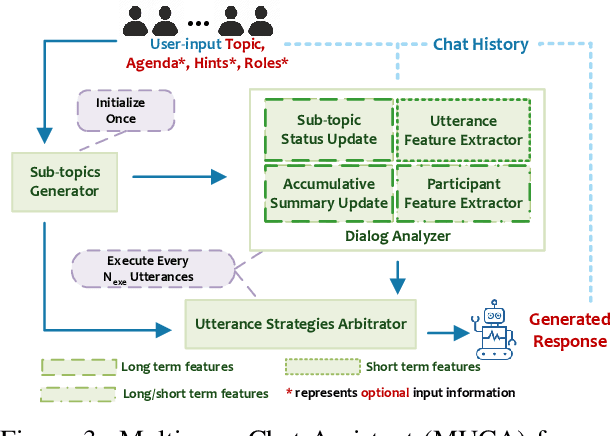
Recent advancements in large language models (LLMs) have provided a new avenue for chatbot development, while most existing research has primarily centered on single-user chatbots that focus on deciding "What" to answer after user inputs. In this paper, we identified that multi-user chatbots have more complex 3W design dimensions -- "What" to say, "When" to respond, and "Who" to answer. Additionally, we proposed Multi-User Chat Assistant (MUCA), which is an LLM-based framework for chatbots specifically designed for group discussions. MUCA consists of three main modules: Sub-topic Generator, Dialog Analyzer, and Utterance Strategies Arbitrator. These modules jointly determine suitable response contents, timings, and the appropriate recipients. To make the optimizing process for MUCA easier, we further propose an LLM-based Multi-User Simulator (MUS) that can mimic real user behavior. This enables faster simulation of a conversation between the chatbot and simulated users, making the early development of the chatbot framework much more efficient. MUCA demonstrates effectiveness, including appropriate chime-in timing, relevant content, and positive user engagement, in goal-oriented conversations with a small to medium number of participants, as evidenced by case studies and experimental results from user studies.
Explanations based on the Missing: Towards Contrastive Explanations with Pertinent Negatives
Oct 29, 2018
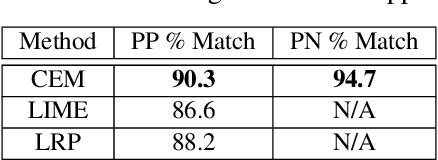

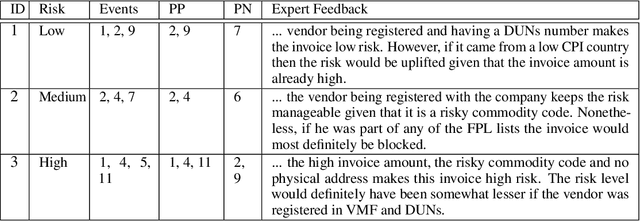
In this paper we propose a novel method that provides contrastive explanations justifying the classification of an input by a black box classifier such as a deep neural network. Given an input we find what should be %necessarily and minimally and sufficiently present (viz. important object pixels in an image) to justify its classification and analogously what should be minimally and necessarily \emph{absent} (viz. certain background pixels). We argue that such explanations are natural for humans and are used commonly in domains such as health care and criminology. What is minimally but critically \emph{absent} is an important part of an explanation, which to the best of our knowledge, has not been explicitly identified by current explanation methods that explain predictions of neural networks. We validate our approach on three real datasets obtained from diverse domains; namely, a handwritten digits dataset MNIST, a large procurement fraud dataset and a brain activity strength dataset. In all three cases, we witness the power of our approach in generating precise explanations that are also easy for human experts to understand and evaluate.
AutoZOOM: Autoencoder-based Zeroth Order Optimization Method for Attacking Black-box Neural Networks
Sep 06, 2018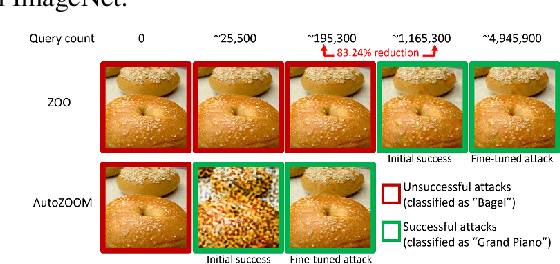
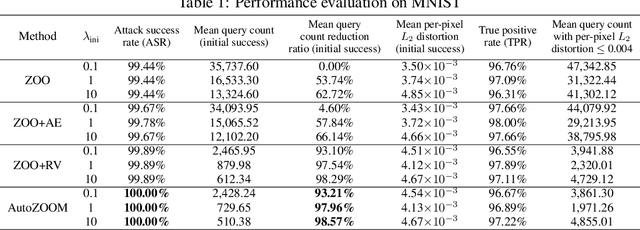
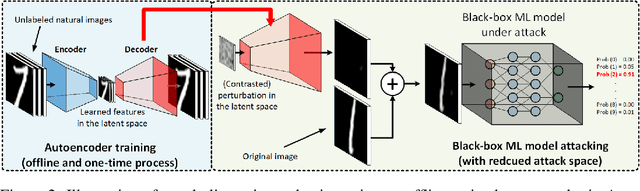
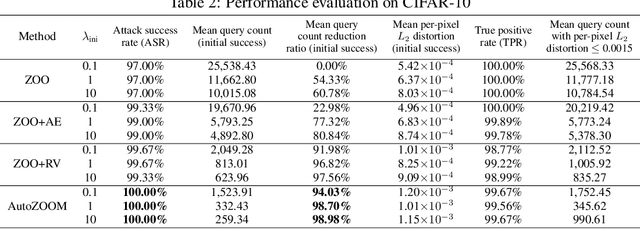
Recent studies have shown that adversarial examples in state-of-the-art image classifiers trained by deep neural networks (DNN) can be easily generated when the target model is transparent to an attacker, known as the white-box setting. However, when attacking a deployed machine learning service, one can only acquire the input-output correspondences of the target model; this is the so-called black-box attack setting. The major drawback of existing black-box attacks is the need for excessive model queries, which may give a false sense of model robustness due to inefficient query designs. To bridge this gap, we propose a generic framework for query-efficient black-box attacks. Our framework, AutoZOOM, which is short for Autoencoder-based Zeroth Order Optimization Method, has two novel building blocks towards efficient black-box attacks: (i) an adaptive random gradient estimation strategy to balance query counts and distortion, and (ii) an autoencoder that is either trained offline with unlabeled data or a bilinear resizing operation for attack acceleration. Experimental results suggest that, by applying AutoZOOM to a state-of-the-art black-box attack (ZOO), a significant reduction in model queries can be achieved without sacrificing the attack success rate and the visual quality of the resulting adversarial examples. In particular, when compared to the standard ZOO method, AutoZOOM can consistently reduce the mean query counts in finding successful adversarial examples (or reaching the same distortion level) by at least 93% on MNIST, CIFAR-10 and ImageNet datasets, leading to novel insights on adversarial robustness.
Zeroth-Order Stochastic Variance Reduction for Nonconvex Optimization
Jun 07, 2018
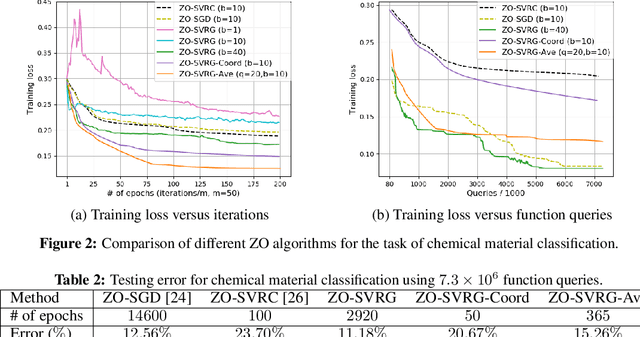
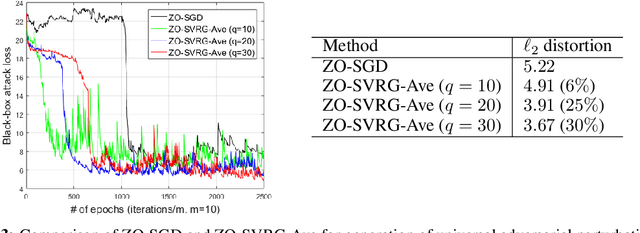
As application demands for zeroth-order (gradient-free) optimization accelerate, the need for variance reduced and faster converging approaches is also intensifying. This paper addresses these challenges by presenting: a) a comprehensive theoretical analysis of variance reduced zeroth-order (ZO) optimization, b) a novel variance reduced ZO algorithm, called ZO-SVRG, and c) an experimental evaluation of our approach in the context of two compelling applications, black-box chemical material classification and generation of adversarial examples from black-box deep neural network models. Our theoretical analysis uncovers an essential difficulty in the analysis of ZO-SVRG: the unbiased assumption on gradient estimates no longer holds. We prove that compared to its first-order counterpart, ZO-SVRG with a two-point random gradient estimator could suffer an additional error of order $O(1/b)$, where $b$ is the mini-batch size. To mitigate this error, we propose two accelerated versions of ZO-SVRG utilizing variance reduced gradient estimators, which achieve the best rate known for ZO stochastic optimization (in terms of iterations). Our extensive experimental results show that our approaches outperform other state-of-the-art ZO algorithms, and strike a balance between the convergence rate and the function query complexity.