 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Contrastive Explanations with Monotonic Attribute Functions
May 29, 2019



Explaining decisions of deep neural networks is a hot research topic with applications in medical imaging, video surveillance, and self driving cars. Many methods have been proposed in literature to explain these decisions by identifying relevance of different pixels. In this paper, we propose a method that can generate contrastive explanations for such data where we not only highlight aspects that are in themselves sufficient to justify the classification by the deep model, but also new aspects which if added will change the classification. One of our key contributions is how we define "addition" for such rich data in a formal yet humanly interpretable way that leads to meaningful results. This was one of the open questions laid out in Dhurandhar et.al. (2018) [5], which proposed a general framework for creating (local) contrastive explanations for deep models. We showcase the efficacy of our approach on CelebA and Fashion-MNIST in creating intuitive explanations that are also quantitatively superior compared with other state-of-the-art interpretability methods.
Explanations based on the Missing: Towards Contrastive Explanations with Pertinent Negatives
Oct 29, 2018
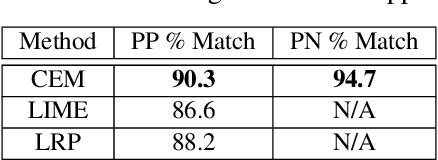

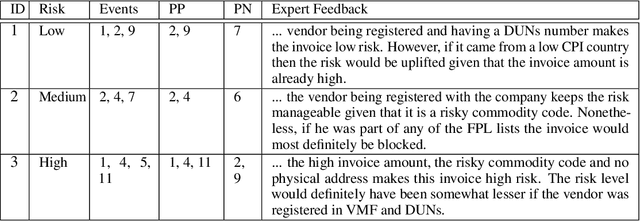
In this paper we propose a novel method that provides contrastive explanations justifying the classification of an input by a black box classifier such as a deep neural network. Given an input we find what should be %necessarily and minimally and sufficiently present (viz. important object pixels in an image) to justify its classification and analogously what should be minimally and necessarily \emph{absent} (viz. certain background pixels). We argue that such explanations are natural for humans and are used commonly in domains such as health care and criminology. What is minimally but critically \emph{absent} is an important part of an explanation, which to the best of our knowledge, has not been explicitly identified by current explanation methods that explain predictions of neural networks. We validate our approach on three real datasets obtained from diverse domains; namely, a handwritten digits dataset MNIST, a large procurement fraud dataset and a brain activity strength dataset. In all three cases, we witness the power of our approach in generating precise explanations that are also easy for human experts to understand and evaluate.
AutoZOOM: Autoencoder-based Zeroth Order Optimization Method for Attacking Black-box Neural Networks
Sep 06, 2018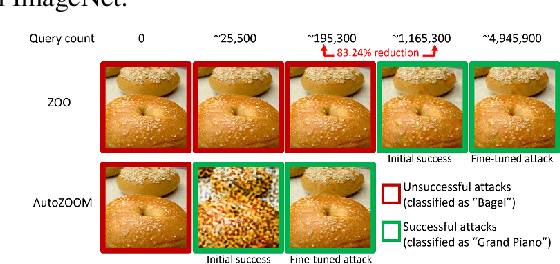
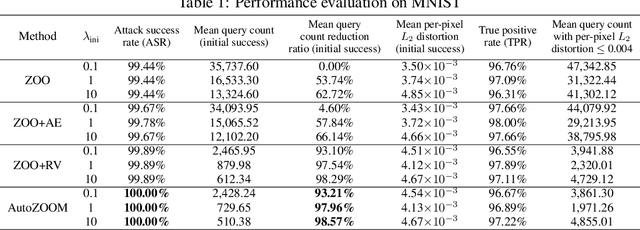
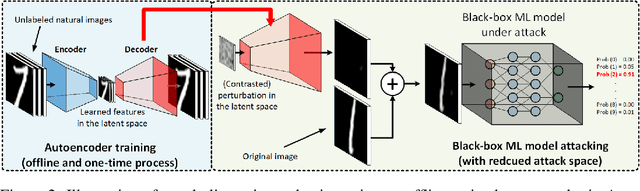
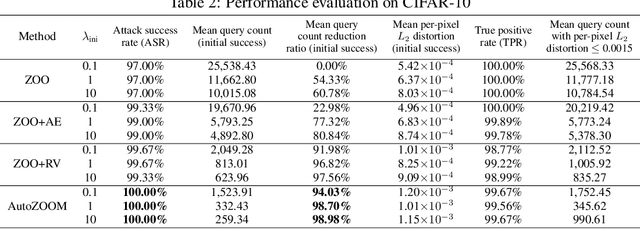
Recent studies have shown that adversarial examples in state-of-the-art image classifiers trained by deep neural networks (DNN) can be easily generated when the target model is transparent to an attacker, known as the white-box setting. However, when attacking a deployed machine learning service, one can only acquire the input-output correspondences of the target model; this is the so-called black-box attack setting. The major drawback of existing black-box attacks is the need for excessive model queries, which may give a false sense of model robustness due to inefficient query designs. To bridge this gap, we propose a generic framework for query-efficient black-box attacks. Our framework, AutoZOOM, which is short for Autoencoder-based Zeroth Order Optimization Method, has two novel building blocks towards efficient black-box attacks: (i) an adaptive random gradient estimation strategy to balance query counts and distortion, and (ii) an autoencoder that is either trained offline with unlabeled data or a bilinear resizing operation for attack acceleration. Experimental results suggest that, by applying AutoZOOM to a state-of-the-art black-box attack (ZOO), a significant reduction in model queries can be achieved without sacrificing the attack success rate and the visual quality of the resulting adversarial examples. In particular, when compared to the standard ZOO method, AutoZOOM can consistently reduce the mean query counts in finding successful adversarial examples (or reaching the same distortion level) by at least 93% on MNIST, CIFAR-10 and ImageNet datasets, leading to novel insights on adversarial robustness.
FEAST: An Automated Feature Selection Framework for Compilation Tasks
Oct 29, 2016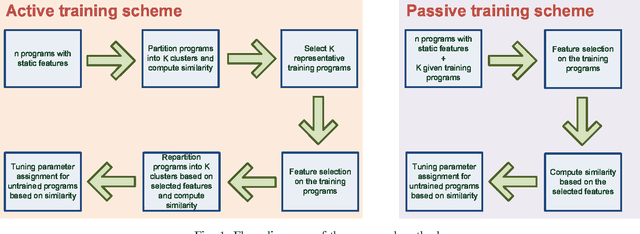
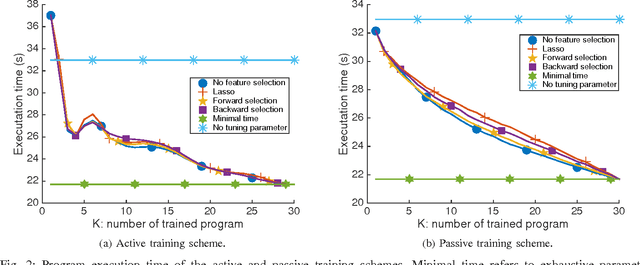
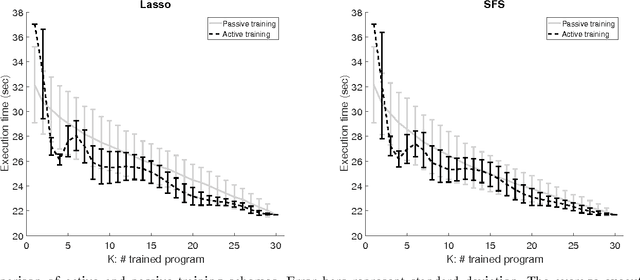
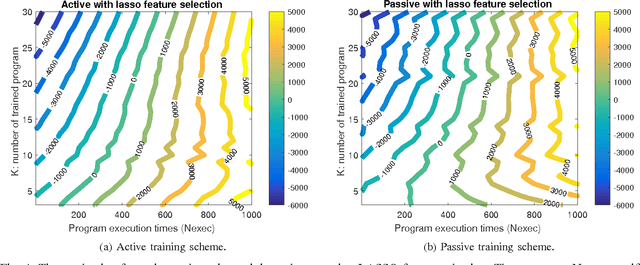
The success of the application of machine-learning techniques to compilation tasks can be largely attributed to the recent development and advancement of program characterization, a process that numerically or structurally quantifies a target program. While great achievements have been made in identifying key features to characterize programs, choosing a correct set of features for a specific compiler task remains an ad hoc procedure. In order to guarantee a comprehensive coverage of features, compiler engineers usually need to select excessive number of features. This, unfortunately, would potentially lead to a selection of multiple similar features, which in turn could create a new problem of bias that emphasizes certain aspects of a program's characteristics, hence reducing the accuracy and performance of the target compiler task. In this paper, we propose FEAture Selection for compilation Tasks (FEAST), an efficient and automated framework for determining the most relevant and representative features from a feature pool. Specifically, FEAST utilizes widely used statistics and machine-learning tools, including LASSO, sequential forward and backward selection, for automatic feature selection, and can in general be applied to any numerical feature set. This paper further proposes an automated approach to compiler parameter assignment for assessing the performance of FEAST. Intensive experimental results demonstrate that, under the compiler parameter assignment task, FEAST can achieve comparable results with about 18% of features that are automatically selected from the entire feature pool. We also inspect these selected features and discuss their roles in program execution.