 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization of Lightweight Malware Detection Models For AIoT Devices
Apr 06, 2024Malware intrusion is problematic for Internet of Things (IoT) and Artificial Intelligence of Things (AIoT) devices as they often reside in an ecosystem of connected devices, such as a smart home. If any devices are infected, the whole ecosystem can be compromised. Although various Machine Learning (ML) models are deployed to detect malware and network intrusion, generally speaking, robust high-accuracy models tend to require resources not found in all IoT devices, compared to less robust models defined by weak learners. In order to combat this issue, Fadhilla proposed a meta-learner ensemble model comprised of less robust prediction results inherent with weak learner ML models to produce a highly robust meta-learning ensemble model. The main problem with the prior research is that it cannot be deployed in low-end AIoT devices due to the limited resources comprising processing power, storage, and memory (the required libraries quickly exhaust low-end AIoT devices' resources.) Hence, this research aims to optimize the proposed super learner meta-learning ensemble model to make it viable for low-end AIoT devices. We show the library and ML model memory requirements associated with each optimization stage and emphasize that optimization of current ML models is necessitated for low-end AIoT devices. Our results demonstrate that we can obtain similar accuracy and False Positive Rate (FPR) metrics from high-end AIoT devices running the derived ML model, with a lower inference duration and smaller memory footprint.
AutoZOOM: Autoencoder-based Zeroth Order Optimization Method for Attacking Black-box Neural Networks
Sep 06, 2018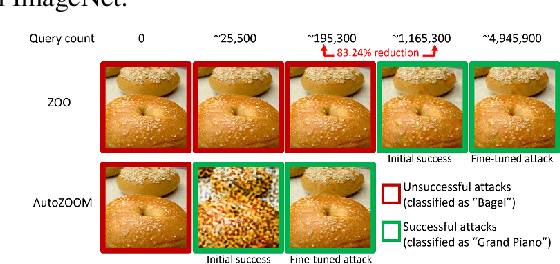
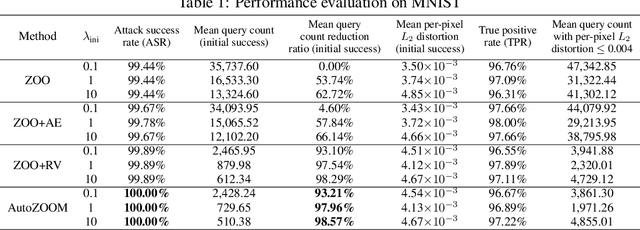
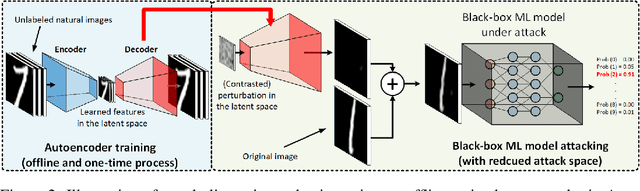
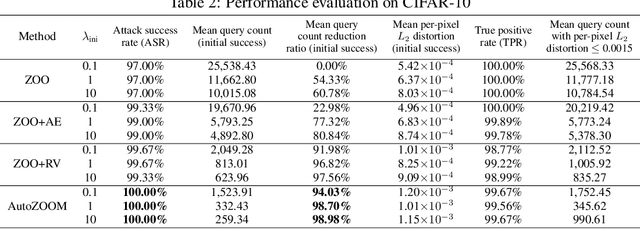
Recent studies have shown that adversarial examples in state-of-the-art image classifiers trained by deep neural networks (DNN) can be easily generated when the target model is transparent to an attacker, known as the white-box setting. However, when attacking a deployed machine learning service, one can only acquire the input-output correspondences of the target model; this is the so-called black-box attack setting. The major drawback of existing black-box attacks is the need for excessive model queries, which may give a false sense of model robustness due to inefficient query designs. To bridge this gap, we propose a generic framework for query-efficient black-box attacks. Our framework, AutoZOOM, which is short for Autoencoder-based Zeroth Order Optimization Method, has two novel building blocks towards efficient black-box attacks: (i) an adaptive random gradient estimation strategy to balance query counts and distortion, and (ii) an autoencoder that is either trained offline with unlabeled data or a bilinear resizing operation for attack acceleration. Experimental results suggest that, by applying AutoZOOM to a state-of-the-art black-box attack (ZOO), a significant reduction in model queries can be achieved without sacrificing the attack success rate and the visual quality of the resulting adversarial examples. In particular, when compared to the standard ZOO method, AutoZOOM can consistently reduce the mean query counts in finding successful adversarial examples (or reaching the same distortion level) by at least 93% on MNIST, CIFAR-10 and ImageNet datasets, leading to novel insights on adversarial robustness.
FEAST: An Automated Feature Selection Framework for Compilation Tasks
Oct 29, 2016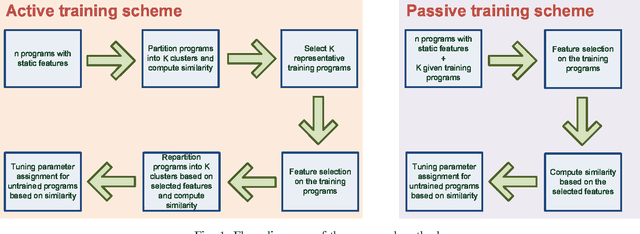
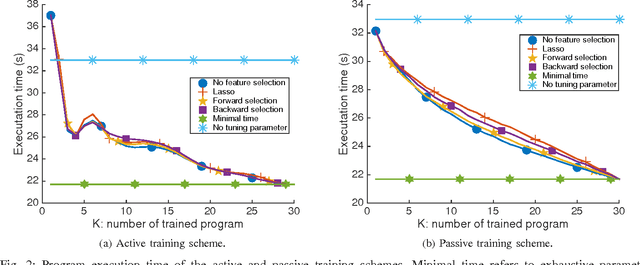
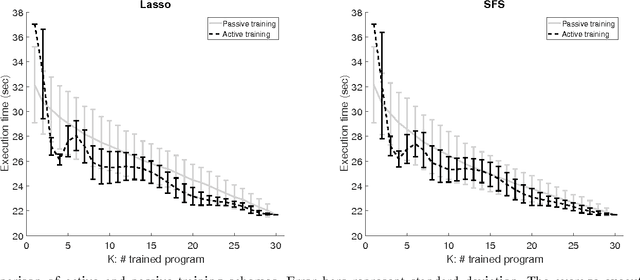
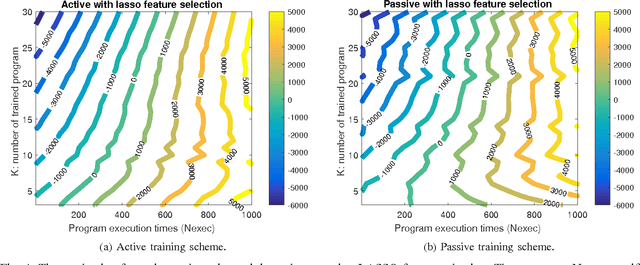
The success of the application of machine-learning techniques to compilation tasks can be largely attributed to the recent development and advancement of program characterization, a process that numerically or structurally quantifies a target program. While great achievements have been made in identifying key features to characterize programs, choosing a correct set of features for a specific compiler task remains an ad hoc procedure. In order to guarantee a comprehensive coverage of features, compiler engineers usually need to select excessive number of features. This, unfortunately, would potentially lead to a selection of multiple similar features, which in turn could create a new problem of bias that emphasizes certain aspects of a program's characteristics, hence reducing the accuracy and performance of the target compiler task. In this paper, we propose FEAture Selection for compilation Tasks (FEAST), an efficient and automated framework for determining the most relevant and representative features from a feature pool. Specifically, FEAST utilizes widely used statistics and machine-learning tools, including LASSO, sequential forward and backward selection, for automatic feature selection, and can in general be applied to any numerical feature set. This paper further proposes an automated approach to compiler parameter assignment for assessing the performance of FEAST. Intensive experimental results demonstrate that, under the compiler parameter assignment task, FEAST can achieve comparable results with about 18% of features that are automatically selected from the entire feature pool. We also inspect these selected features and discuss their roles in program execution.
Supervised Collective Classification for Crowdsourcing
Sep 08, 2015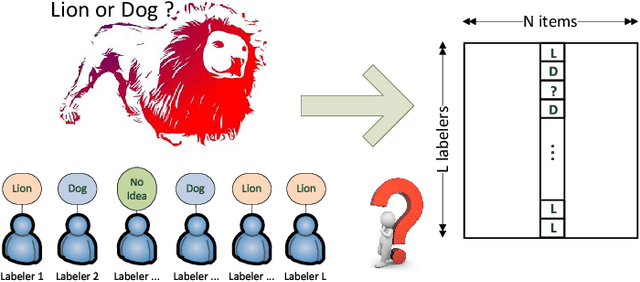
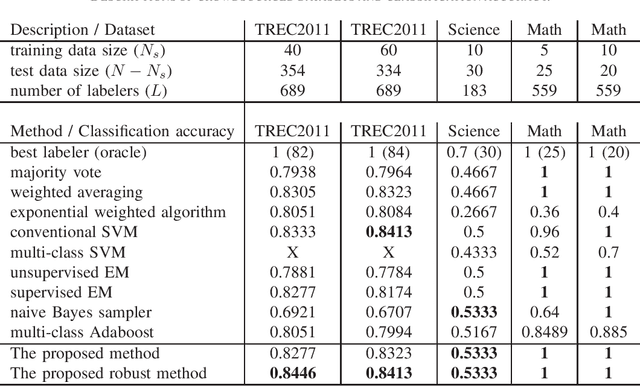
Crowdsourcing utilizes the wisdom of crowds for collective classification via information (e.g., labels of an item) provided by labelers. Current crowdsourcing algorithms are mainly unsupervised methods that are unaware of the quality of crowdsourced data. In this paper, we propose a supervised collective classification algorithm that aims to identify reliable labelers from the training data (e.g., items with known labels). The reliability (i.e., weighting factor) of each labeler is determined via a saddle point algorithm. The results on several crowdsourced data show that supervised methods can achieve better classification accuracy than unsupervised methods, and our proposed method outperforms other algorithms.
When Crowdsourcing Meets Mobile Sensing: A Social Network Perspective
Aug 03, 2015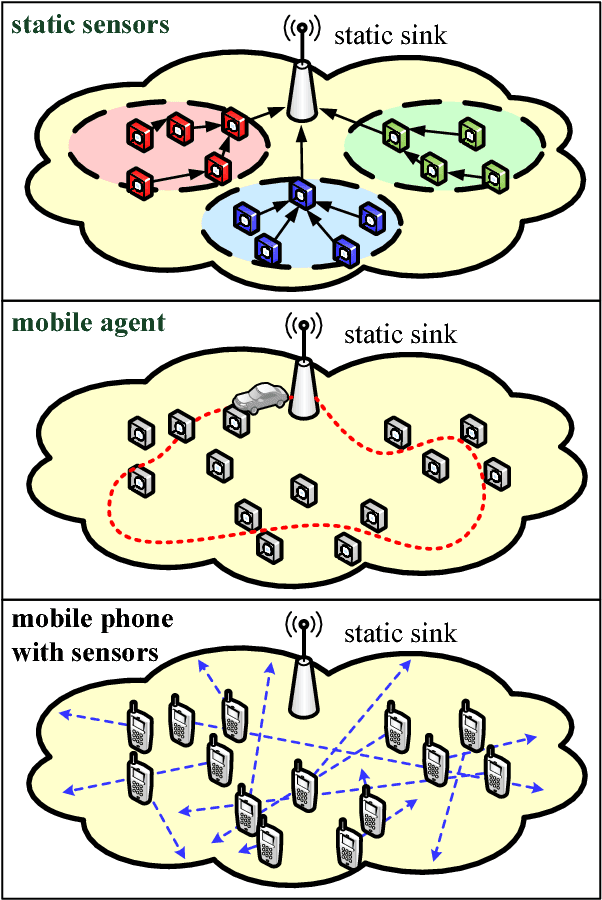
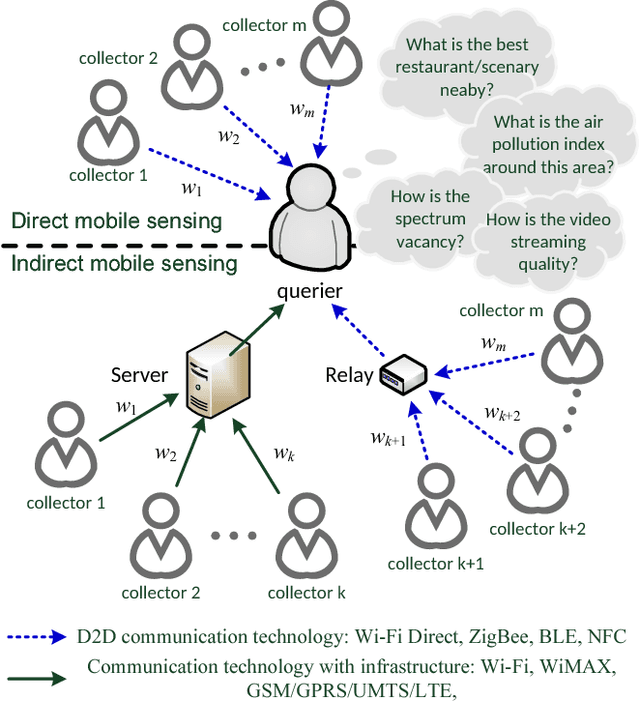

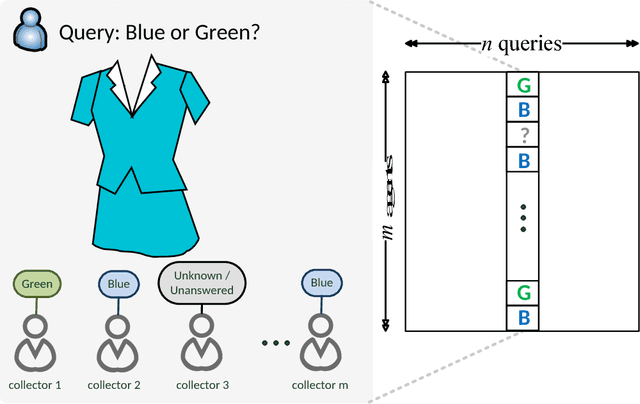
Mobile sensing is an emerging technology that utilizes agent-participatory data for decision making or state estimation, including multimedia applications. This article investigates the structure of mobile sensing schemes and introduces crowdsourcing methods for mobile sensing. Inspired by social network, one can establish trust among participatory agents to leverage the wisdom of crowds for mobile sensing. A prototype of social network inspired mobile multimedia and sensing application is presented for illustrative purpose. Numerical experiments on real-world datasets show improved performance of mobile sensing via crowdsourcing. Challenges for mobile sensing with respect to Internet layers are discussed.