Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Collective Classification for Crowdsourcing
Paper and Code
Sep 08, 2015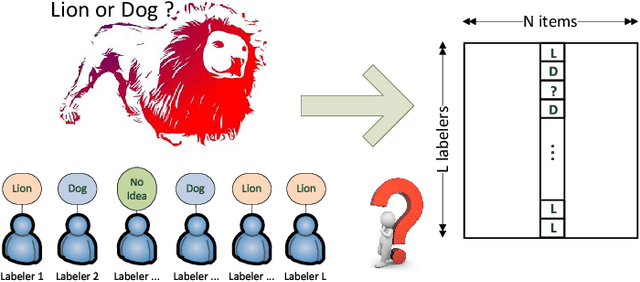
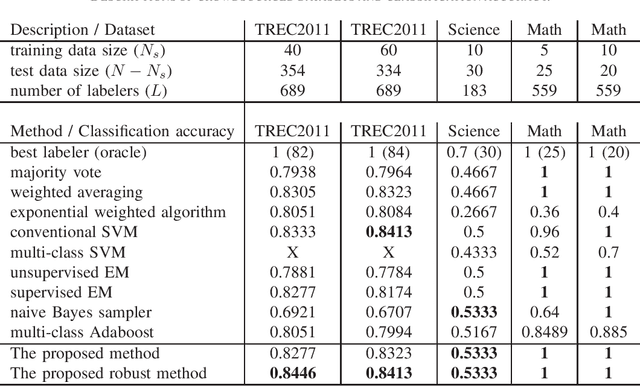
Crowdsourcing utilizes the wisdom of crowds for collective classification via information (e.g., labels of an item) provided by labelers. Current crowdsourcing algorithms are mainly unsupervised methods that are unaware of the quality of crowdsourced data. In this paper, we propose a supervised collective classification algorithm that aims to identify reliable labelers from the training data (e.g., items with known labels). The reliability (i.e., weighting factor) of each labeler is determined via a saddle point algorithm. The results on several crowdsourced data show that supervised methods can achieve better classification accuracy than unsupervised methods, and our proposed method outperforms other algorithms.
* to appear in IEEE Global Communications Conference (GLOBECOM)
Workshop on Networking and Collaboration Issues for the Internet of
Everything
View paper on