 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Stronger Baselines for Learning to Optimize
Paper and Code
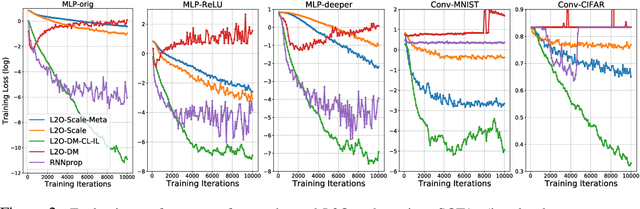
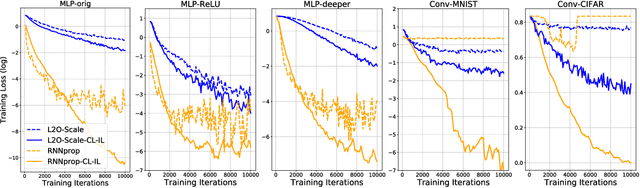
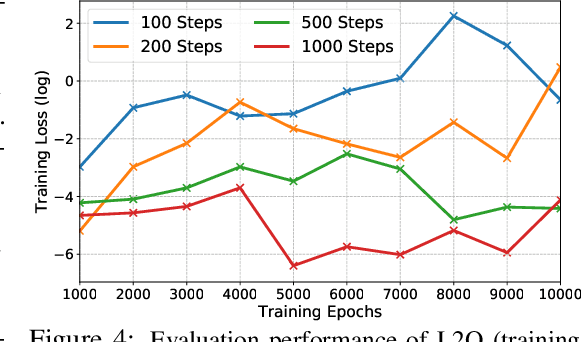
Learning to optimize (L2O) has gained increasing attention since classical optimizers require laborious problem-specific design and hyperparameter tuning. However, there is a gap between the practical demand and the achievable performance of existing L2O models. Specifically, those learned optimizers are applicable to only a limited class of problems, and often exhibit instability. With many efforts devoted to designing more sophisticated L2O models, we argue for another orthogonal, under-explored theme: the training techniques for those L2O models. We show that even the simplest L2O model could have been trained much better. We first present a progressive training scheme to gradually increase the optimizer unroll length, to mitigate a well-known L2O dilemma of truncation bias (shorter unrolling) versus gradient explosion (longer unrolling). We further leverage off-policy imitation learning to guide the L2O learning, by taking reference to the behavior of analytical optimizers. Our improved training techniques are plugged into a variety of state-of-the-art L2O models, and immediately boost their performance, without making any change to their model structures. Especially, by our proposed techniques, an earliest and simplest L2O model can be trained to outperform the latest complicated L2O models on a number of tasks. Our results demonstrate a greater potential of L2O yet to be unleashed, and urge to rethink the recent progress. Our codes are publicly available at: https://github.com/VITA-Group/L2O-Training-Techniques.