 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTART: A Generalized State Space Model with Saliency-Driven Token-Aware Transformation
Paper and Code
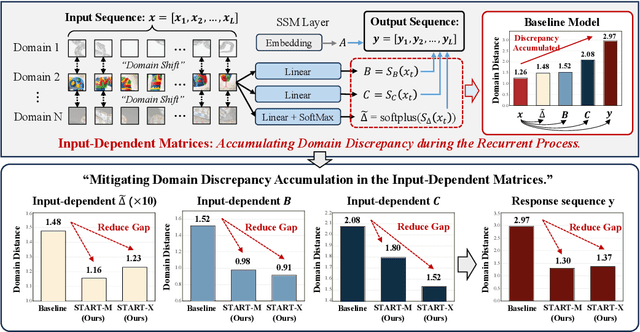
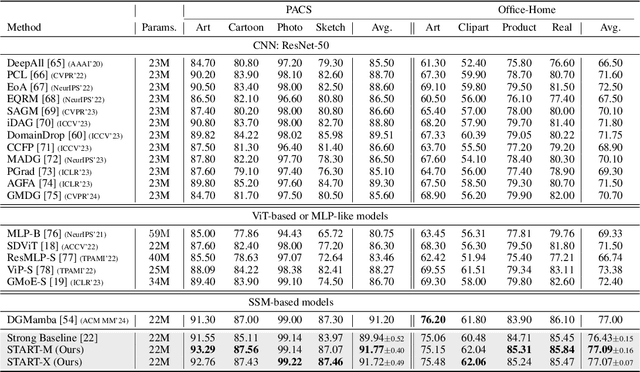
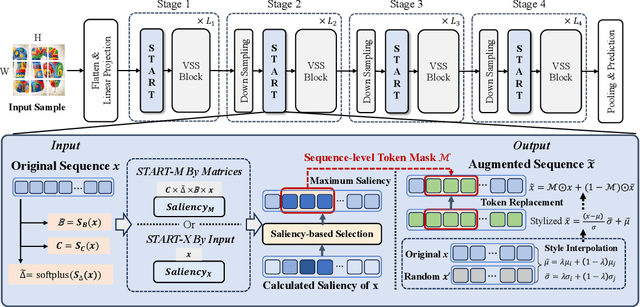
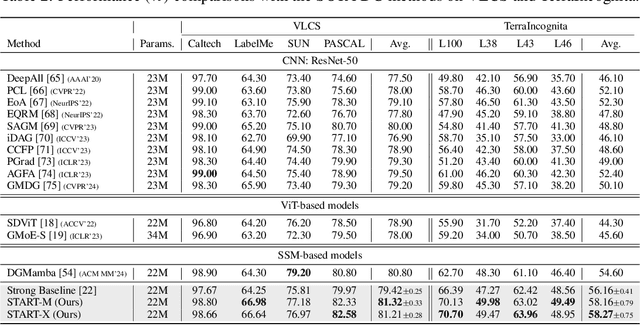
Domain Generalization (DG) aims to enable models to generalize to unseen target domains by learning from multiple source domains. Existing DG methods primarily rely on convolutional neural networks (CNNs), which inherently learn texture biases due to their limited receptive fields, making them prone to overfitting source domains. While some works have introduced transformer-based methods (ViTs) for DG to leverage the global receptive field, these methods incur high computational costs due to the quadratic complexity of self-attention. Recently, advanced state space models (SSMs), represented by Mamba, have shown promising results in supervised learning tasks by achieving linear complexity in sequence length during training and fast RNN-like computation during inference. Inspired by this, we investigate the generalization ability of the Mamba model under domain shifts and find that input-dependent matrices within SSMs could accumulate and amplify domain-specific features, thus hindering model generalization. To address this issue, we propose a novel SSM-based architecture with saliency-based token-aware transformation (namely START), which achieves state-of-the-art (SOTA) performances and offers a competitive alternative to CNNs and ViTs. Our START can selectively perturb and suppress domain-specific features in salient tokens within the input-dependent matrices of SSMs, thus effectively reducing the discrepancy between different domains. Extensive experiments on five benchmarks demonstrate that START outperforms existing SOTA DG methods with efficient linear complexity. Our code is available at https://github.com/lingeringlight/START.