 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenSelect: Efficient Long-Context Inference and Length Extrapolation for LLMs via Dynamic Token-Level KV Cache Selection
Nov 05, 2024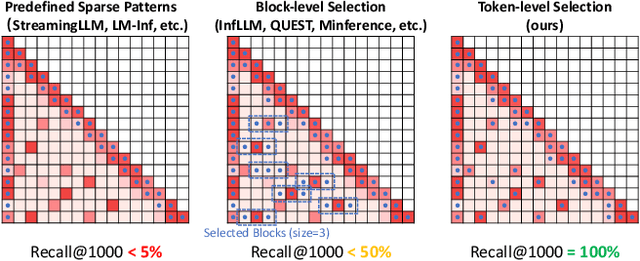
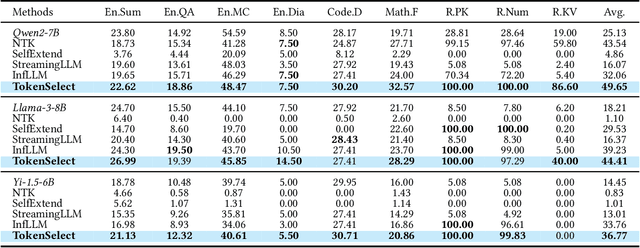
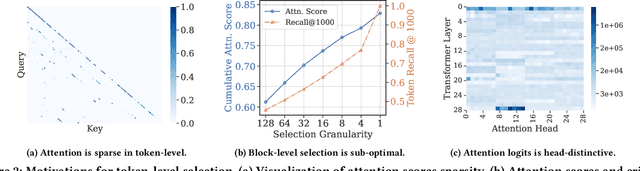
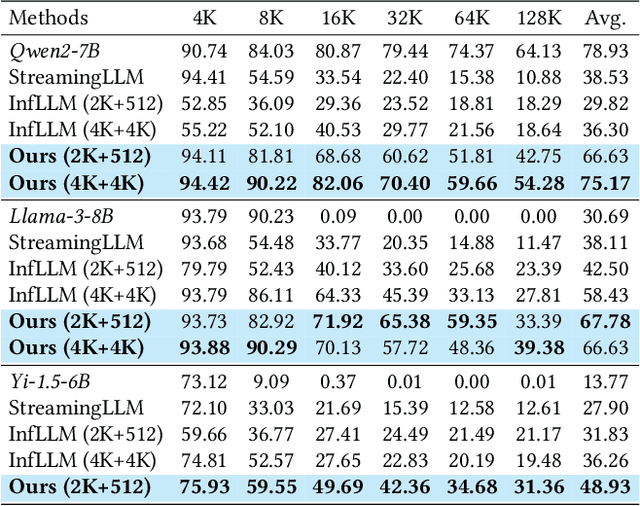
With the development of large language models (LLMs), the ability to handle longer contexts has become a key capability for Web applications such as cross-document understanding and LLM-powered search systems. However, this progress faces two major challenges: performance degradation due to sequence lengths out-of-distribution, and excessively long inference times caused by the quadratic computational complexity of attention. These issues hinder the application of LLMs in long-context scenarios. In this paper, we propose Dynamic Token-Level KV Cache Selection (TokenSelect), a model-agnostic, training-free method for efficient and accurate long-context inference. TokenSelect builds upon the observation of non-contiguous attention sparsity, using Query-Key dot products to measure per-head KV Cache criticality at token-level. By per-head soft voting mechanism, TokenSelect selectively involves a small number of critical KV cache tokens in the attention calculation without sacrificing accuracy. To further accelerate TokenSelect, we designed the Selection Cache based on observations of consecutive Query similarity and implemented efficient dot product kernel, significantly reducing the overhead of token selection. A comprehensive evaluation of TokenSelect demonstrates up to 23.84x speedup in attention computation and up to 2.28x acceleration in end-to-end latency, while providing superior performance compared to state-of-the-art long-context inference methods.