 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPA: Camera-pose-awareness Diffusion Transformer for Video Generation
Dec 02, 2024Despite the significant advancements made by Diffusion Transformer (DiT)-based methods in video generation, there remains a notable gap with controllable camera pose perspectives. Existing works such as OpenSora do NOT adhere precisely to anticipated trajectories and physical interactions, thereby limiting the flexibility in downstream applications. To alleviate this issue, we introduce CPA, a unified camera-pose-awareness text-to-video generation approach that elaborates the camera movement and integrates the textual, visual, and spatial conditions. Specifically, we deploy the Sparse Motion Encoding (SME) module to transform camera pose information into a spatial-temporal embedding and activate the Temporal Attention Injection (TAI) module to inject motion patches into each ST-DiT block. Our plug-in architecture accommodates the original DiT parameters, facilitating diverse types of camera poses and flexible object movement. Extensive qualitative and quantitative experiments demonstrate that our method outperforms LDM-based methods for long video generation while achieving optimal performance in trajectory consistency and object consistency.
RingMo-lite: A Remote Sensing Multi-task Lightweight Network with CNN-Transformer Hybrid Framework
Sep 16, 2023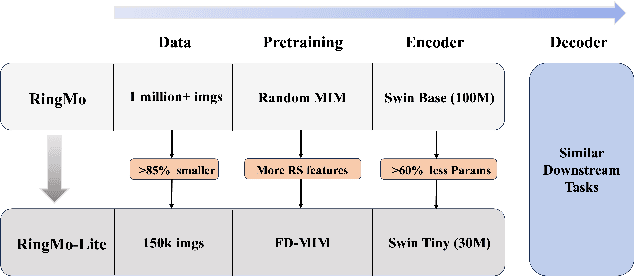
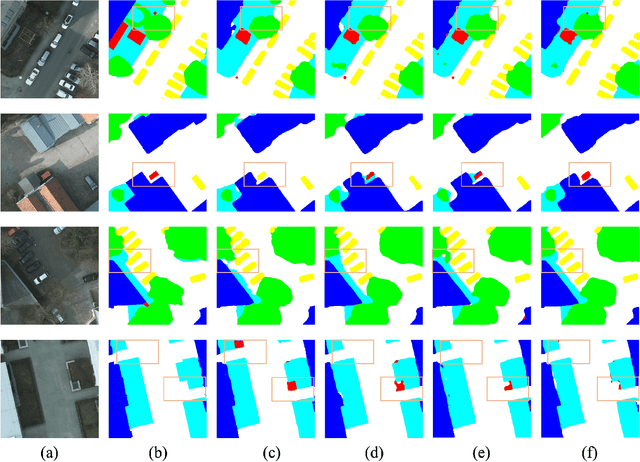
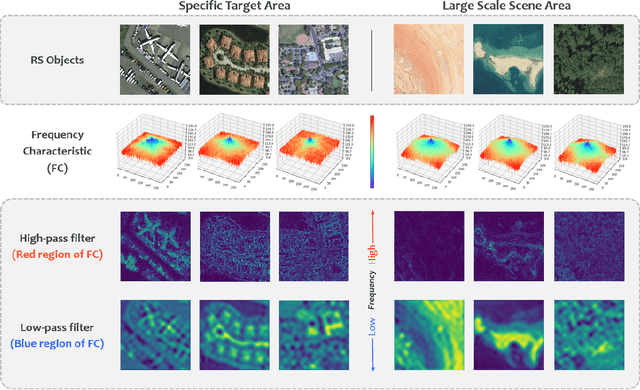
In recent years, remote sensing (RS) vision foundation models such as RingMo have emerged and achieved excellent performance in various downstream tasks. However, the high demand for computing resources limits the application of these models on edge devices. It is necessary to design a more lightweight foundation model to support on-orbit RS image interpretation. Existing methods face challenges in achieving lightweight solutions while retaining generalization in RS image interpretation. This is due to the complex high and low-frequency spectral components in RS images, which make traditional single CNN or Vision Transformer methods unsuitable for the task. Therefore, this paper proposes RingMo-lite, an RS multi-task lightweight network with a CNN-Transformer hybrid framework, which effectively exploits the frequency-domain properties of RS to optimize the interpretation process. It is combined by the Transformer module as a low-pass filter to extract global features of RS images through a dual-branch structure, and the CNN module as a stacked high-pass filter to extract fine-grained details effectively. Furthermore, in the pretraining stage, the designed frequency-domain masked image modeling (FD-MIM) combines each image patch's high-frequency and low-frequency characteristics, effectively capturing the latent feature representation in RS data. As shown in Fig. 1, compared with RingMo, the proposed RingMo-lite reduces the parameters over 60% in various RS image interpretation tasks, the average accuracy drops by less than 2% in most of the scenes and achieves SOTA performance compared to models of the similar size. In addition, our work will be integrated into the MindSpore computing platform in the near future.