 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedViz: An Agent-based, Visual-guided Research Assistant for Navigating Biomedical Literature
Jan 28, 2026Biomedical researchers face increasing challenges in navigating millions of publications in diverse domains. Traditional search engines typically return articles as ranked text lists, offering little support for global exploration or in-depth analysis. Although recent advances in generative AI and large language models have shown promise in tasks such as summarization, extraction, and question answering, their dialog-based implementations are poorly integrated with literature search workflows. To address this gap, we introduce MedViz, a visual analytics system that integrates multiple AI agents with interactive visualization to support the exploration of the large-scale biomedical literature. MedViz combines a semantic map of millions of articles with agent-driven functions for querying, summarizing, and hypothesis generation, allowing researchers to iteratively refine questions, identify trends, and uncover hidden connections. By bridging intelligent agents with interactive visualization, MedViz transforms biomedical literature search into a dynamic, exploratory process that accelerates knowledge discovery.
Through the Judge's Eyes: Inferred Thinking Traces Improve Reliability of LLM Raters
Oct 29, 2025Large language models (LLMs) are increasingly used as raters for evaluation tasks. However, their reliability is often limited for subjective tasks, when human judgments involve subtle reasoning beyond annotation labels. Thinking traces, the reasoning behind a judgment, are highly informative but challenging to collect and curate. We present a human-LLM collaborative framework to infer thinking traces from label-only annotations. The proposed framework uses a simple and effective rejection sampling method to reconstruct these traces at scale. These inferred thinking traces are applied to two complementary tasks: (1) fine-tuning open LLM raters; and (2) synthesizing clearer annotation guidelines for proprietary LLM raters. Across multiple datasets, our methods lead to significantly improved LLM-human agreement. Additionally, the refined annotation guidelines increase agreement among different LLM models. These results suggest that LLMs can serve as practical proxies for otherwise unrevealed human thinking traces, enabling label-only corpora to be extended into thinking-trace-augmented resources that enhance the reliability of LLM raters.
Be.FM: Open Foundation Models for Human Behavior
May 29, 2025



Despite their success in numerous fields, the potential of foundation models for modeling and understanding human behavior remains largely unexplored. We introduce Be.FM, one of the first open foundation models designed for human behavior modeling. Built upon open-source large language models and fine-tuned on a diverse range of behavioral data, Be.FM can be used to understand and predict human decision-making. We construct a comprehensive set of benchmark tasks for testing the capabilities of behavioral foundation models. Our results demonstrate that Be.FM can predict behaviors, infer characteristics of individuals and populations, generate insights about contexts, and apply behavioral science knowledge.
ExAnte: A Benchmark for Ex-Ante Inference in Large Language Models
May 26, 2025



Large language models (LLMs) face significant challenges in ex-ante reasoning, where analysis, inference, or predictions must be made without access to information from future events. Even with explicit prompts enforcing temporal cutoffs, LLMs often generate outputs influenced by internalized knowledge of events beyond the specified cutoff. This paper introduces a novel task and benchmark designed to evaluate the ability of LLMs to reason while adhering to such temporal constraints. The benchmark includes a variety of tasks: stock prediction, Wikipedia event prediction, scientific publication prediction, and Question Answering (QA), designed to assess factual knowledge under temporal cutoff constraints. We use leakage rate to quantify models' reliance on future information beyond cutoff timestamps. Experimental results reveal that LLMs struggle to consistently adhere to temporal cutoffs across common prompting strategies and tasks, demonstrating persistent challenges in ex-ante reasoning. This benchmark provides a potential evaluation framework to advance the development of LLMs' temporal reasoning ability for time-sensitive applications.
Using Language Models to Decipher the Motivation Behind Human Behaviors
Mar 20, 2025AI presents a novel tool for deciphering the motivations behind human behaviors. We show that by varying prompts to a large language model, we can elicit a full range of human behaviors in a variety of different scenarios in terms of classic economic games. Then by analyzing which prompts are needed to elicit which behaviors, we can infer (decipher) the motivations behind the human behaviors. We also show how one can analyze the prompts to reveal relationships between the classic economic games, providing new insight into what different economic scenarios induce people to think about. We also show how this deciphering process can be used to understand differences in the behavioral tendencies of different populations.
Efficient Estimation of Shortest-Path Distance Distributions to Samples in Graphs
Feb 21, 2025
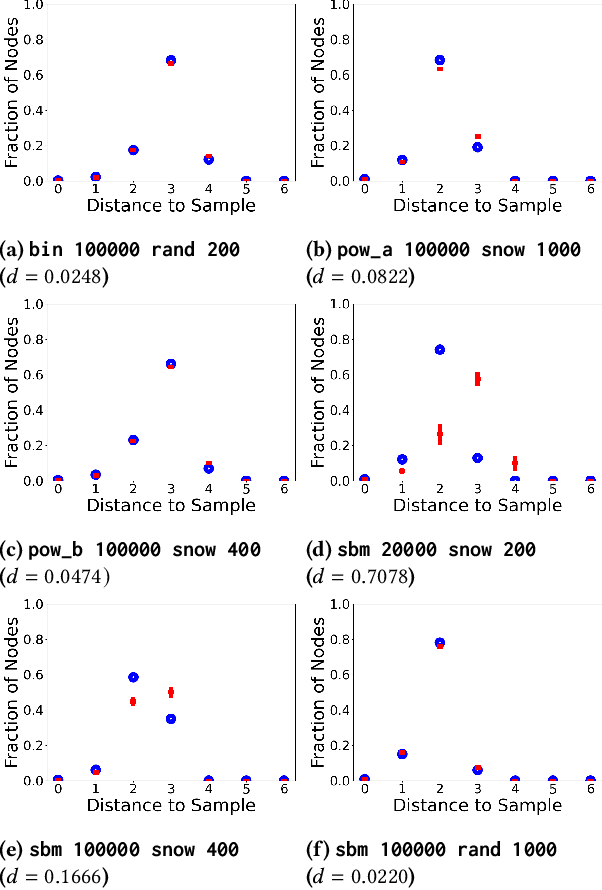
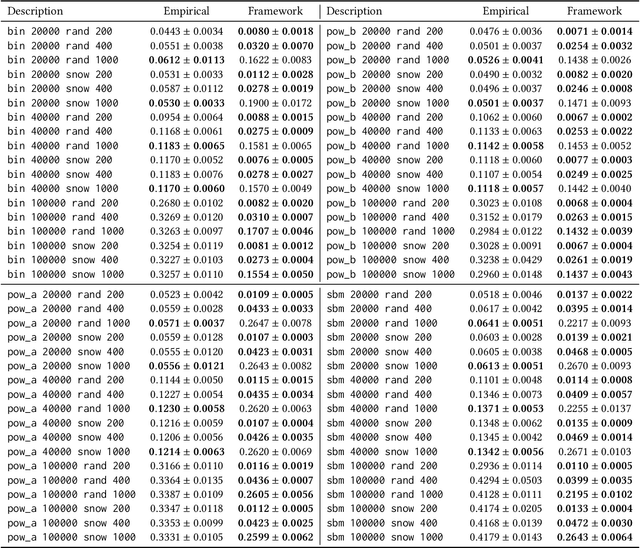
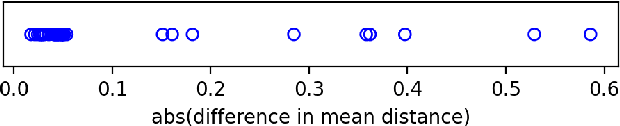
As large graph datasets become increasingly common across many fields, sampling is often needed to reduce the graphs into manageable sizes. This procedure raises critical questions about representativeness as no sample can capture the properties of the original graph perfectly, and different parts of the graph are not evenly affected by the loss. Recent work has shown that the distances from the non-sampled nodes to the sampled nodes can be a quantitative indicator of bias and fairness in graph machine learning. However, to our knowledge, there is no method for evaluating how a sampling method affects the distribution of shortest-path distances without actually performing the sampling and shortest-path calculation. In this paper, we present an accurate and efficient framework for estimating the distribution of shortest-path distances to the sample, applicable to a wide range of sampling methods and graph structures. Our framework is faster than empirical methods and only requires the specification of degree distributions. We also extend our framework to handle graphs with community structures. While this introduces a decrease in accuracy, we demonstrate that our framework remains highly accurate on downstream comparison-based tasks. Code is publicly available at https://github.com/az1326/shortest_paths.
Reasoning-Enhanced Self-Training for Long-Form Personalized Text Generation
Jan 07, 2025Personalized text generation requires a unique ability of large language models (LLMs) to learn from context that they often do not encounter during their standard training. One way to encourage LLMs to better use personalized context for generating outputs that better align with the user's expectations is to instruct them to reason over the user's past preferences, background knowledge, or writing style. To achieve this, we propose Reasoning-Enhanced Self-Training for Personalized Text Generation (REST-PG), a framework that trains LLMs to reason over personal data during response generation. REST-PG first generates reasoning paths to train the LLM's reasoning abilities and then employs Expectation-Maximization Reinforced Self-Training to iteratively train the LLM based on its own high-reward outputs. We evaluate REST-PG on the LongLaMP benchmark, consisting of four diverse personalized long-form text generation tasks. Our experiments demonstrate that REST-PG achieves significant improvements over state-of-the-art baselines, with an average relative performance gain of 14.5% on the benchmark.
How Different AI Chatbots Behave? Benchmarking Large Language Models in Behavioral Economics Games
Dec 16, 2024The deployment of large language models (LLMs) in diverse applications requires a thorough understanding of their decision-making strategies and behavioral patterns. As a supplement to a recent study on the behavioral Turing test, this paper presents a comprehensive analysis of five leading LLM-based chatbot families as they navigate a series of behavioral economics games. By benchmarking these AI chatbots, we aim to uncover and document both common and distinct behavioral patterns across a range of scenarios. The findings provide valuable insights into the strategic preferences of each LLM, highlighting potential implications for their deployment in critical decision-making roles.
Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach
Jul 23, 2024Retrieval Augmented Generation (RAG) has been a powerful tool for Large Language Models (LLMs) to efficiently process overly lengthy contexts. However, recent LLMs like Gemini-1.5 and GPT-4 show exceptional capabilities to understand long contexts directly. We conduct a comprehensive comparison between RAG and long-context (LC) LLMs, aiming to leverage the strengths of both. We benchmark RAG and LC across various public datasets using three latest LLMs. Results reveal that when resourced sufficiently, LC consistently outperforms RAG in terms of average performance. However, RAG's significantly lower cost remains a distinct advantage. Based on this observation, we propose Self-Route, a simple yet effective method that routes queries to RAG or LC based on model self-reflection. Self-Route significantly reduces the computation cost while maintaining a comparable performance to LC. Our findings provide a guideline for long-context applications of LLMs using RAG and LC.
Towards Bidirectional Human-AI Alignment: A Systematic Review for Clarifications, Framework, and Future Directions
Jun 17, 2024Recent advancements in general-purpose AI have highlighted the importance of guiding AI systems towards the intended goals, ethical principles, and values of individuals and groups, a concept broadly recognized as alignment. However, the lack of clarified definitions and scopes of human-AI alignment poses a significant obstacle, hampering collaborative efforts across research domains to achieve this alignment. In particular, ML- and philosophy-oriented alignment research often views AI alignment as a static, unidirectional process (i.e., aiming to ensure that AI systems' objectives match humans) rather than an ongoing, mutual alignment problem [429]. This perspective largely neglects the long-term interaction and dynamic changes of alignment. To understand these gaps, we introduce a systematic review of over 400 papers published between 2019 and January 2024, spanning multiple domains such as Human-Computer Interaction (HCI), Natural Language Processing (NLP), Machine Learning (ML), and others. We characterize, define and scope human-AI alignment. From this, we present a conceptual framework of "Bidirectional Human-AI Alignment" to organize the literature from a human-centered perspective. This framework encompasses both 1) conventional studies of aligning AI to humans that ensures AI produces the intended outcomes determined by humans, and 2) a proposed concept of aligning humans to AI, which aims to help individuals and society adjust to AI advancements both cognitively and behaviorally. Additionally, we articulate the key findings derived from literature analysis, including discussions about human values, interaction techniques, and evaluations. To pave the way for future studies, we envision three key challenges for future directions and propose examples of potential future solutions.