 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
Reasoning-Enhanced Self-Training for Long-Form Personalized Text Generation
Jan 07, 2025Personalized text generation requires a unique ability of large language models (LLMs) to learn from context that they often do not encounter during their standard training. One way to encourage LLMs to better use personalized context for generating outputs that better align with the user's expectations is to instruct them to reason over the user's past preferences, background knowledge, or writing style. To achieve this, we propose Reasoning-Enhanced Self-Training for Personalized Text Generation (REST-PG), a framework that trains LLMs to reason over personal data during response generation. REST-PG first generates reasoning paths to train the LLM's reasoning abilities and then employs Expectation-Maximization Reinforced Self-Training to iteratively train the LLM based on its own high-reward outputs. We evaluate REST-PG on the LongLaMP benchmark, consisting of four diverse personalized long-form text generation tasks. Our experiments demonstrate that REST-PG achieves significant improvements over state-of-the-art baselines, with an average relative performance gain of 14.5% on the benchmark.
PRewrite: Prompt Rewriting with Reinforcement Learning
Jan 16, 2024



Prompt engineering is critical for the development of LLM-based applications. However, it is usually done manually in a "trial and error" fashion. This manual procedure can be time consuming, ineffective, and the generated prompts are, in a lot of cases, sub-optimal. Even for the prompts which seemingly work well, there is always a lingering question: can the prompts be made better with further modifications? To address these questions, in this paper, we investigate prompt engineering automation. We consider a specific use case scenario in which developers/users have drafted initial prompts, but lack the time/expertise to optimize them. We propose PRewrite, an automated tool to rewrite these drafts and to generate highly effective new prompts. PRewrite is based on the Reinforcement Learning (RL) framework which allows for end-to-end optimization and our design allows the RL search to happen in a large action space. The automated tool leverages manually crafted prompts as starting points which makes the rewriting procedure more guided and efficient. The generated prompts are human readable, and self-explanatory, unlike some of those in previous works. We conducted extensive experiments on diverse datasets and found that the prompts generated with this new method not only outperform professionally crafted prompts, but also prompts generated with other previously proposed methods.
Bridging the Preference Gap between Retrievers and LLMs
Jan 13, 2024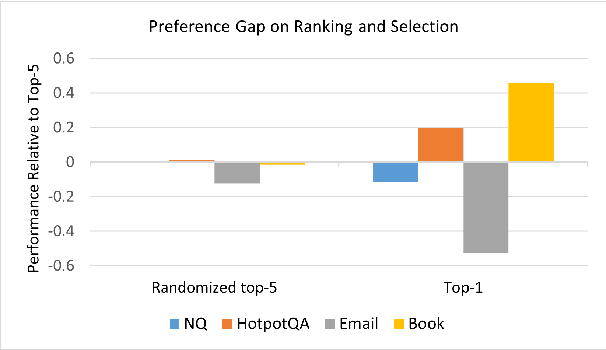
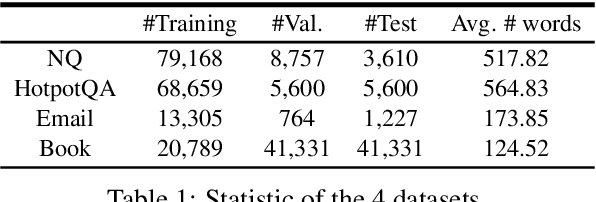
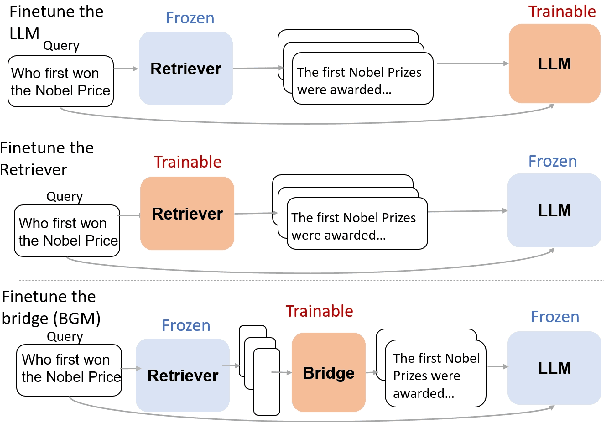
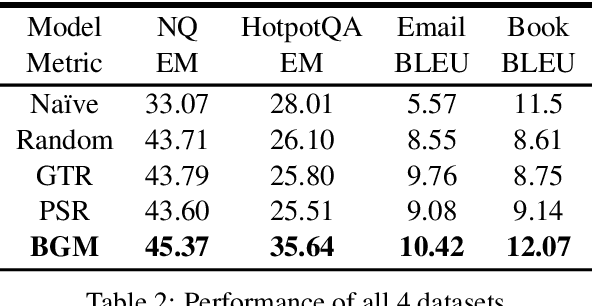
Large Language Models (LLMs) have demonstrated superior results across a wide range of tasks, while retrieval has long been established as an effective means of obtaining task-relevant information for humans. Retrieval-augmented Generation (RAG) are known for their effectiveness in knowledge-intensive tasks by locating relevant information and placing it within the context window of the LLM. However, the relationship between retrievers and LLMs is still under-investigated. Most existing work treats the retriever and the LLM as independent components and leaves a gap between retrieving human-friendly information and assembling a LLM-friendly context. In this work, we examine a novel bridge model, validate the ranking and selection assumptions in retrievers in the context of RAG, and propose a training framework that chains together supervised and reinforcement learning to learn a bridge model. Empirical results demonstrate the effectiveness of our method in both question-answering and personalized generation tasks.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Automatic Prompt Rewriting for Personalized Text Generation
Sep 29, 2023



Facilitated by large language models (LLMs), personalized text generation has become a rapidly growing research direction. Most existing studies focus on designing specialized models for a particular domain, or they require fine-tuning the LLMs to generate personalized text. We consider a typical scenario in which the large language model, which generates personalized output, is frozen and can only be accessed through APIs. Under this constraint, all one can do is to improve the input text (i.e., text prompts) sent to the LLM, a procedure that is usually done manually. In this paper, we propose a novel method to automatically revise prompts for personalized text generation. The proposed method takes the initial prompts generated by a state-of-the-art, multistage framework for personalized generation and rewrites a few critical components that summarize and synthesize the personal context. The prompt rewriter employs a training paradigm that chains together supervised learning (SL) and reinforcement learning (RL), where SL reduces the search space of RL and RL facilitates end-to-end training of the rewriter. Using datasets from three representative domains, we demonstrate that the rewritten prompts outperform both the original prompts and the prompts optimized via supervised learning or reinforcement learning alone. In-depth analysis of the rewritten prompts shows that they are not only human readable, but also able to guide manual revision of prompts when there is limited resource to employ reinforcement learning to train the prompt rewriter, or when it is costly to deploy an automatic prompt rewriter for inference.
Privacy-Adaptive BERT for Natural Language Understanding
Apr 15, 2021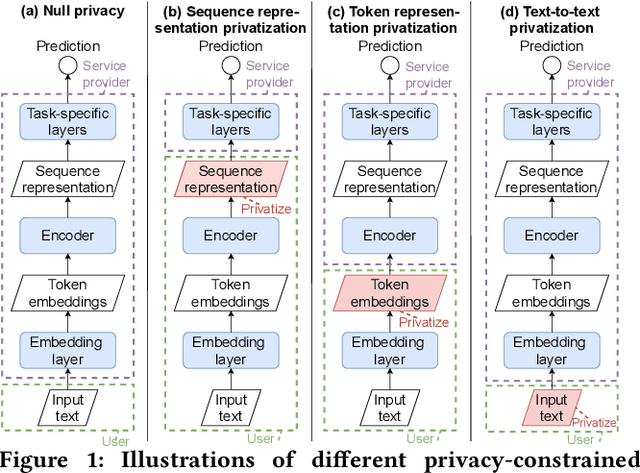
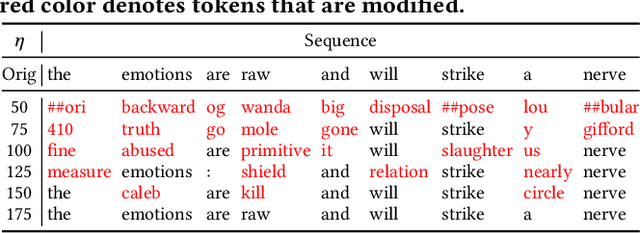
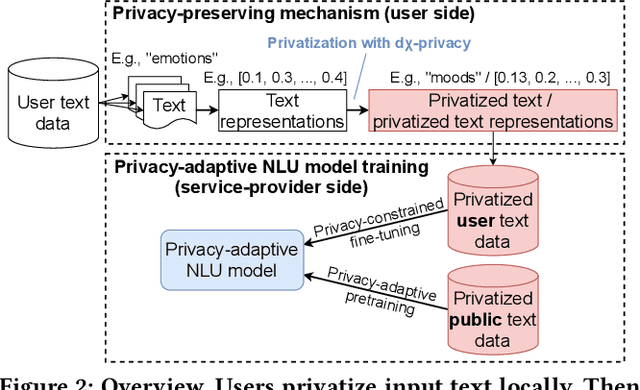
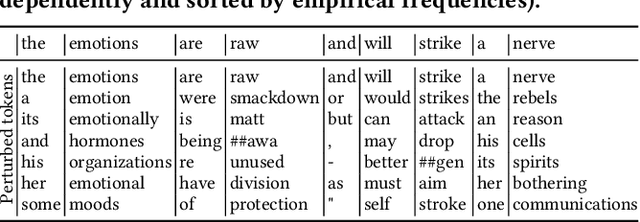
When trying to apply the recent advance of Natural Language Understanding (NLU) technologies to real-world applications, privacy preservation imposes a crucial challenge, which, unfortunately, has not been well resolved. To address this issue, we study how to improve the effectiveness of NLU models under a Local Privacy setting, using BERT, a widely-used pretrained Language Model (LM), as an example. We systematically study the strengths and weaknesses of imposing dx-privacy, a relaxed variant of Local Differential Privacy, at different stages of language modeling: input text, token embeddings, and sequence representations. We then focus on the former two with privacy-constrained fine-tuning experiments to reveal the utility of BERT under local privacy constraints. More importantly, to the best of our knowledge, we are the first to propose privacy-adaptive LM pretraining methods and demonstrate that they can significantly improve model performance on privatized text input. We also interpret the level of privacy preservation and provide our guidance on privacy parameter selections.