 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Adaptive BERT for Natural Language Understanding
Paper and Code
Apr 15, 2021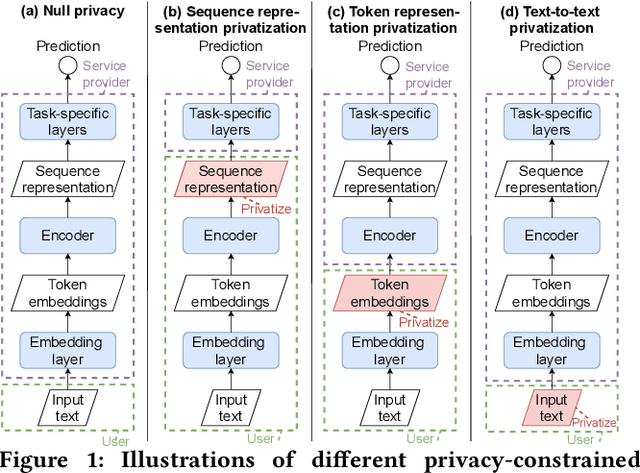
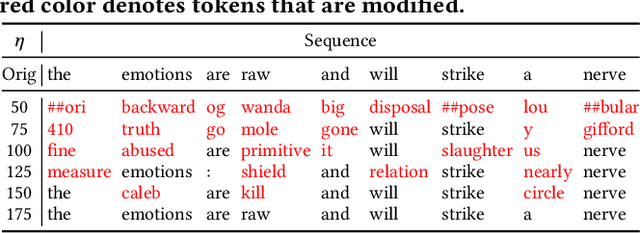
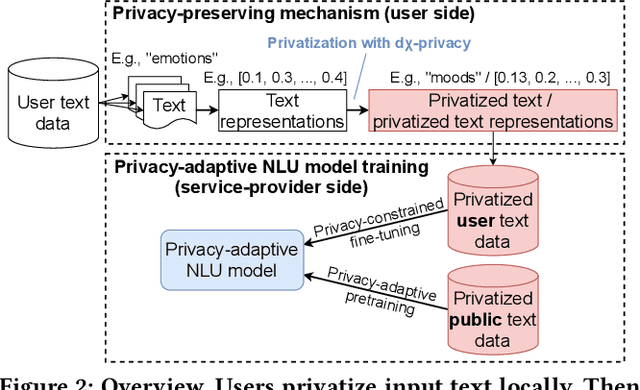
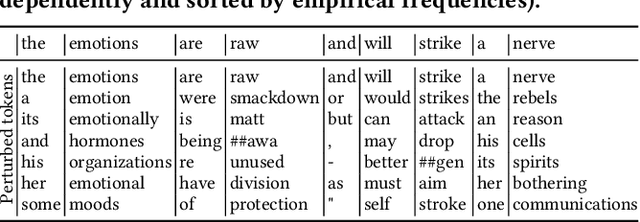
When trying to apply the recent advance of Natural Language Understanding (NLU) technologies to real-world applications, privacy preservation imposes a crucial challenge, which, unfortunately, has not been well resolved. To address this issue, we study how to improve the effectiveness of NLU models under a Local Privacy setting, using BERT, a widely-used pretrained Language Model (LM), as an example. We systematically study the strengths and weaknesses of imposing dx-privacy, a relaxed variant of Local Differential Privacy, at different stages of language modeling: input text, token embeddings, and sequence representations. We then focus on the former two with privacy-constrained fine-tuning experiments to reveal the utility of BERT under local privacy constraints. More importantly, to the best of our knowledge, we are the first to propose privacy-adaptive LM pretraining methods and demonstrate that they can significantly improve model performance on privatized text input. We also interpret the level of privacy preservation and provide our guidance on privacy parameter selections.