 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRewrite: Prompt Rewriting with Reinforcement Learning
Jan 16, 2024



Prompt engineering is critical for the development of LLM-based applications. However, it is usually done manually in a "trial and error" fashion. This manual procedure can be time consuming, ineffective, and the generated prompts are, in a lot of cases, sub-optimal. Even for the prompts which seemingly work well, there is always a lingering question: can the prompts be made better with further modifications? To address these questions, in this paper, we investigate prompt engineering automation. We consider a specific use case scenario in which developers/users have drafted initial prompts, but lack the time/expertise to optimize them. We propose PRewrite, an automated tool to rewrite these drafts and to generate highly effective new prompts. PRewrite is based on the Reinforcement Learning (RL) framework which allows for end-to-end optimization and our design allows the RL search to happen in a large action space. The automated tool leverages manually crafted prompts as starting points which makes the rewriting procedure more guided and efficient. The generated prompts are human readable, and self-explanatory, unlike some of those in previous works. We conducted extensive experiments on diverse datasets and found that the prompts generated with this new method not only outperform professionally crafted prompts, but also prompts generated with other previously proposed methods.
Creator Context for Tweet Recommendation
Nov 29, 2023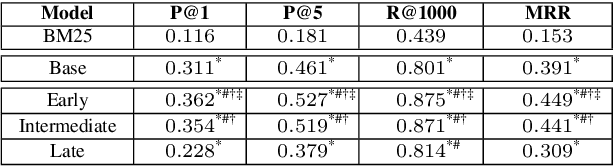

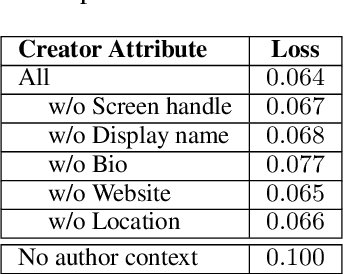
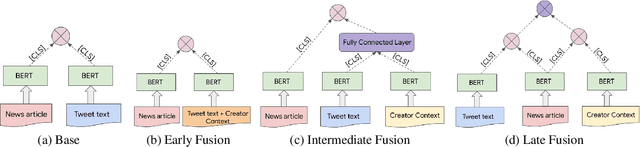
When discussing a tweet, people usually not only refer to the content it delivers, but also to the person behind the tweet. In other words, grounding the interpretation of the tweet in the context of its creator plays an important role in deciphering the true intent and the importance of the tweet. In this paper, we attempt to answer the question of how creator context should be used to advance tweet understanding. Specifically, we investigate the usefulness of different types of creator context, and examine different model structures for incorporating creator context in tweet modeling. We evaluate our tweet understanding models on a practical use case -- recommending relevant tweets to news articles. This use case already exists in popular news apps, and can also serve as a useful assistive tool for journalists. We discover that creator context is essential for tweet understanding, and can improve application metrics by a large margin. However, we also observe that not all creator contexts are equal. Creator context can be time sensitive and noisy. Careful creator context selection and deliberate model structure design play an important role in creator context effectiveness.
Teach LLMs to Personalize -- An Approach inspired by Writing Education
Aug 15, 2023



Personalized text generation is an emerging research area that has attracted much attention in recent years. Most studies in this direction focus on a particular domain by designing bespoke features or models. In this work, we propose a general approach for personalized text generation using large language models (LLMs). Inspired by the practice of writing education, we develop a multistage and multitask framework to teach LLMs for personalized generation. In writing instruction, the task of writing from sources is often decomposed into multiple steps that involve finding, evaluating, summarizing, synthesizing, and integrating information. Analogously, our approach to personalized text generation consists of multiple stages: retrieval, ranking, summarization, synthesis, and generation. In addition, we introduce a multitask setting that helps the model improve its generation ability further, which is inspired by the observation in education that a student's reading proficiency and writing ability are often correlated. We evaluate our approach on three public datasets, each of which covers a different and representative domain. Our results show significant improvements over a variety of baselines.
Dynamic Language Models for Continuously Evolving Content
Jun 11, 2021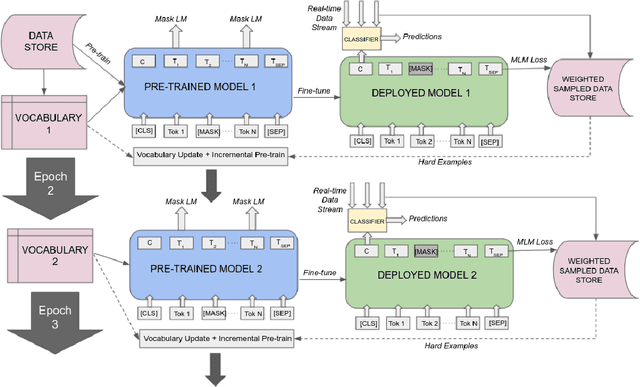
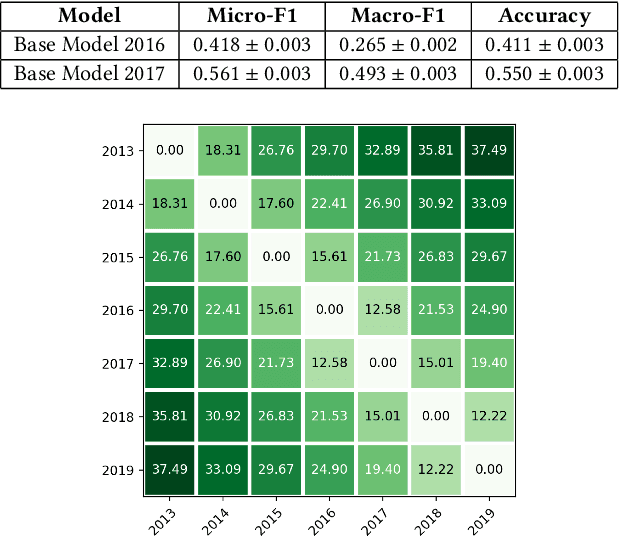


The content on the web is in a constant state of flux. New entities, issues, and ideas continuously emerge, while the semantics of the existing conversation topics gradually shift. In recent years, pre-trained language models like BERT greatly improved the state-of-the-art for a large spectrum of content understanding tasks. Therefore, in this paper, we aim to study how these language models can be adapted to better handle continuously evolving web content. In our study, we first analyze the evolution of 2013 - 2019 Twitter data, and unequivocally confirm that a BERT model trained on past tweets would heavily deteriorate when directly applied to data from later years. Then, we investigate two possible sources of the deterioration: the semantic shift of existing tokens and the sub-optimal or failed understanding of new tokens. To this end, we both explore two different vocabulary composition methods, as well as propose three sampling methods which help in efficient incremental training for BERT-like models. Compared to a new model trained from scratch offline, our incremental training (a) reduces the training costs, (b) achieves better performance on evolving content, and (c) is suitable for online deployment. The superiority of our methods is validated using two downstream tasks. We demonstrate significant improvements when incrementally evolving the model from a particular base year, on the task of Country Hashtag Prediction, as well as on the OffensEval 2019 task.
LAMPRET: Layout-Aware Multimodal PreTraining for Document Understanding
Apr 16, 2021

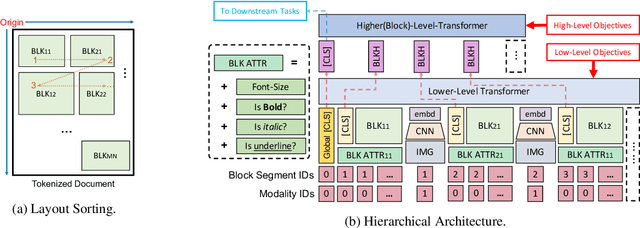

Document layout comprises both structural and visual (eg. font-sizes) information that is vital but often ignored by machine learning models. The few existing models which do use layout information only consider textual contents, and overlook the existence of contents in other modalities such as images. Additionally, spatial interactions of presented contents in a layout were never really fully exploited. To bridge this gap, we parse a document into content blocks (eg. text, table, image) and propose a novel layout-aware multimodal hierarchical framework, LAMPreT, to model the blocks and the whole document. Our LAMPreT encodes each block with a multimodal transformer in the lower-level and aggregates the block-level representations and connections utilizing a specifically designed transformer at the higher-level. We design hierarchical pretraining objectives where the lower-level model is trained similarly to multimodal grounding models, and the higher-level model is trained with our proposed novel layout-aware objectives. We evaluate the proposed model on two layout-aware tasks -- text block filling and image suggestion and show the effectiveness of our proposed hierarchical architecture as well as pretraining techniques.