 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistically Valid Post-Deployment Monitoring Should Be Standard for AI-Based Digital Health
Jun 06, 2025This position paper argues that post-deployment monitoring in clinical AI is underdeveloped and proposes statistically valid and label-efficient testing frameworks as a principled foundation for ensuring reliability and safety in real-world deployment. A recent review found that only 9% of FDA-registered AI-based healthcare tools include a post-deployment surveillance plan. Existing monitoring approaches are often manual, sporadic, and reactive, making them ill-suited for the dynamic environments in which clinical models operate. We contend that post-deployment monitoring should be grounded in label-efficient and statistically valid testing frameworks, offering a principled alternative to current practices. We use the term "statistically valid" to refer to methods that provide explicit guarantees on error rates (e.g., Type I/II error), enable formal inference under pre-defined assumptions, and support reproducibility--features that align with regulatory requirements. Specifically, we propose that the detection of changes in the data and model performance degradation should be framed as distinct statistical hypothesis testing problems. Grounding monitoring in statistical rigor ensures a reproducible and scientifically sound basis for maintaining the reliability of clinical AI systems. Importantly, it also opens new research directions for the technical community--spanning theory, methods, and tools for statistically principled detection, attribution, and mitigation of post-deployment model failures in real-world settings.
Regularization via f-Divergence: An Application to Multi-Oxide Spectroscopic Analysis
Feb 06, 2025



In this paper, we address the task of characterizing the chemical composition of planetary surfaces using convolutional neural networks (CNNs). Specifically, we seek to predict the multi-oxide weights of rock samples based on spectroscopic data collected under Martian conditions. We frame this problem as a multi-target regression task and propose a novel regularization method based on f-divergence. The f-divergence regularization is designed to constrain the distributional discrepancy between predictions and noisy targets. This regularizer serves a dual purpose: on the one hand, it mitigates overfitting by enforcing a constraint on the distributional difference between predictions and noisy targets. On the other hand, it acts as an auxiliary loss function, penalizing the neural network when the divergence between the predicted and target distributions becomes too large. To enable backpropagation during neural network training, we develop a differentiable f-divergence and incorporate it into the f-divergence regularization, making the network training feasible. We conduct experiments using spectra collected in a Mars-like environment by the remote-sensing instruments aboard the Curiosity and Perseverance rovers. Experimental results on multi-oxide weight prediction demonstrate that the proposed $f$-divergence regularization performs better than or comparable to standard regularization methods including $L_1$, $L_2$, and dropout. Notably, combining the $f$-divergence regularization with these standard regularization further enhances performance, outperforming each regularization method used independently.
Adaptive Noise-Tolerant Network for Image Segmentation
Jan 15, 2025Unlike image classification and annotation, for which deep network models have achieved dominating superior performances compared to traditional computer vision algorithms, deep learning for automatic image segmentation still faces critical challenges. One of such hurdles is to obtain ground-truth segmentations as the training labels for deep network training. Especially when we study biomedical images, such as histopathological images (histo-images), it is unrealistic to ask for manual segmentation labels as the ground truth for training due to the fine image resolution as well as the large image size and complexity. In this paper, instead of relying on clean segmentation labels, we study whether and how integrating imperfect or noisy segmentation results from off-the-shelf segmentation algorithms may help achieve better segmentation results through a new Adaptive Noise-Tolerant Network (ANTN) model. We extend the noisy label deep learning to image segmentation with two novel aspects: (1) multiple noisy labels can be integrated into one deep learning model; (2) noisy segmentation modeling, including probabilistic parameters, is adaptive, depending on the given testing image appearance. Implementation of the new ANTN model on both the synthetic data and real-world histo-images demonstrates its effectiveness and superiority over off-the-shelf and other existing deep-learning-based image segmentation algorithms.
Advanced Tutorial: Label-Efficient Two-Sample Tests
Jan 07, 2025

Hypothesis testing is a statistical inference approach used to determine whether data supports a specific hypothesis. An important type is the two-sample test, which evaluates whether two sets of data points are from identical distributions. This test is widely used, such as by clinical researchers comparing treatment effectiveness. This tutorial explores two-sample testing in a context where an analyst has many features from two samples, but determining the sample membership (or labels) of these features is costly. In machine learning, a similar scenario is studied in active learning. This tutorial extends active learning concepts to two-sample testing within this \textit{label-costly} setting while maintaining statistical validity and high testing power. Additionally, the tutorial discusses practical applications of these label-efficient two-sample tests.
Non-orthogonal multiple access enhanced multi-user semantic communication
Mar 12, 2023



Semantic communication serves as a novel paradigm and attracts the broad interest of researchers. One critical aspect of it is the multi-user semantic communication theory, which can further promote its application to the practical network environment. While most existing works focused on the design of end-to-end single-user semantic transmission, a novel non-orthogonal multiple access (NOMA)-based multi-user semantic communication system named NOMASC is proposed in this paper. The proposed system can support semantic tranmission of multiple users with diverse modalities of source information. To avoid high demand for hardware, an asymmetric quantizer is employed at the end of the semantic encoder for discretizing the continuous full-resolution semantic feature. In addition, a neural network model is proposed for mapping the discrete feature into self-learned symbols and accomplishing intelligent multi-user detection (MUD) at the receiver. Simulation results demonstrate that the proposed system holds good performance in non-orthogonal transmission of multiple user signals and outperforms the other methods, especially at low-to-medium SNRs. Moreover, it has high robustness under various simulation settings and mismatched test scenarios.
Active Sequential Two-Sample Testing
Feb 02, 2023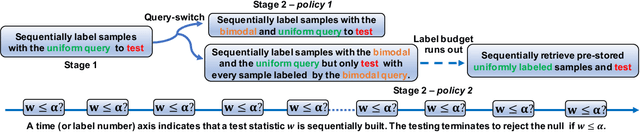
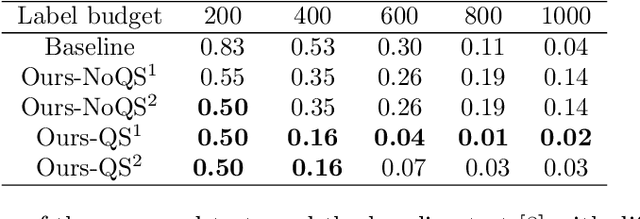
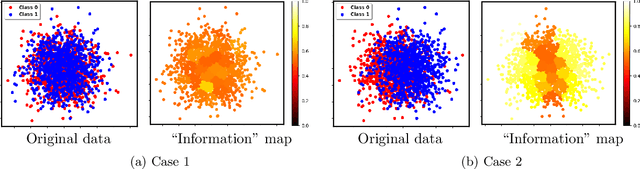

Two-sample testing tests whether the distributions generating two samples are identical. We pose the two-sample testing problem in a new scenario where the sample measurements (or sample features) are inexpensive to access, but their group memberships (or labels) are costly. We devise the first \emph{active sequential two-sample testing framework} that not only sequentially but also \emph{actively queries} sample labels to address the problem. Our test statistic is a likelihood ratio where one likelihood is found by maximization over all class priors, and the other is given by a classification model. The classification model is adaptively updated and then used to guide an active query scheme called bimodal query to label sample features in the regions with high dependency between the feature variables and the label variables. The theoretical contributions in the paper include proof that our framework produces an \emph{anytime-valid} $p$-value; and, under reachable conditions and a mild assumption, the framework asymptotically generates a minimum normalized log-likelihood ratio statistic that a passive query scheme can only achieve when the feature variable and the label variable have the highest dependence. Lastly, we provide a \emph{query-switching (QS)} algorithm to decide when to switch from passive query to active query and adapt bimodal query to increase the testing power of our test. Extensive experiments justify our theoretical contributions and the effectiveness of QS.
A label efficient two-sample test
Nov 29, 2021

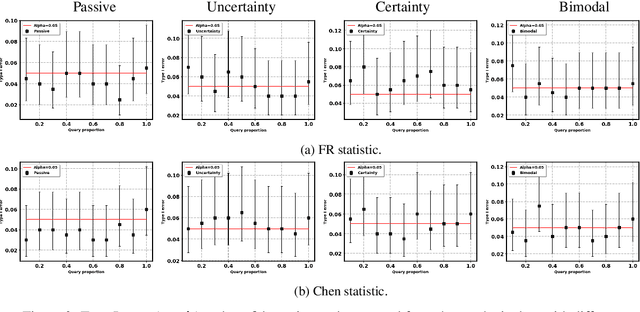

Two-sample tests evaluate whether two samples are realizations of the same distribution (the null hypothesis) or two different distributions (the alternative hypothesis). In the traditional formulation of this problem, the statistician has access to both the measurements (feature variables) and the group variable (label variable). However, in several important applications, feature variables can be easily measured but the binary label variable is unknown and costly to obtain. In this paper, we consider this important variation on the classical two-sample test problem and pose it as a problem of obtaining the labels of only a small number of samples in service of performing a two-sample test. We devise a label efficient three-stage framework: firstly, a classifier is trained with samples uniformly labeled to model the posterior probabilities of the labels; secondly, a novel query scheme dubbed \emph{bimodal query} is used to query labels of samples from both classes with maximum posterior probabilities, and lastly, the classical Friedman-Rafsky (FR) two-sample test is performed on the queried samples. Our theoretical analysis shows that bimodal query is optimal for two-sample testing using the FR statistic under reasonable conditions and that the three-stage framework controls the Type I error. Extensive experiments performed on synthetic, benchmark, and application-specific datasets demonstrate that the three-stage framework has decreased Type II error over uniform querying and certainty-based querying with same number of labels while controlling the Type I error. Source code for our algorithms and experimental results is available at https://github.com/wayne0908/Label-Efficient-Two-Sample.
Finding the Homology of Decision Boundaries with Active Learning
Nov 19, 2020



Accurately and efficiently characterizing the decision boundary of classifiers is important for problems related to model selection and meta-learning. Inspired by topological data analysis, the characterization of decision boundaries using their homology has recently emerged as a general and powerful tool. In this paper, we propose an active learning algorithm to recover the homology of decision boundaries. Our algorithm sequentially and adaptively selects which samples it requires the labels of. We theoretically analyze the proposed framework and show that the query complexity of our active learning algorithm depends naturally on the intrinsic complexity of the underlying manifold. We demonstrate the effectiveness of our framework in selecting best-performing machine learning models for datasets just using their respective homological summaries. Experiments on several standard datasets show the sample complexity improvement in recovering the homology and demonstrate the practical utility of the framework for model selection. Source code for our algorithms and experimental results is available at https://github.com/wayne0908/Active-Learning-Homology.
Regularization via Structural Label Smoothing
Jan 07, 2020
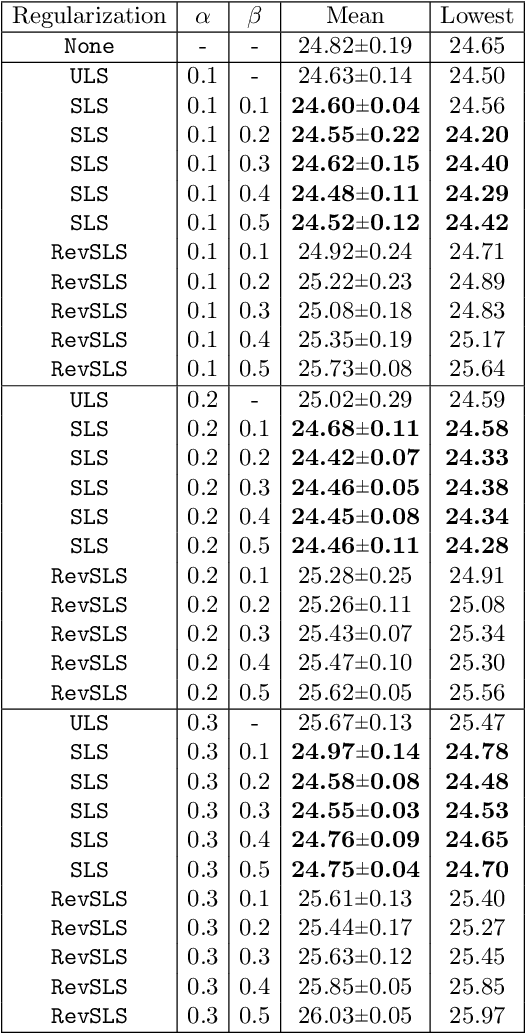
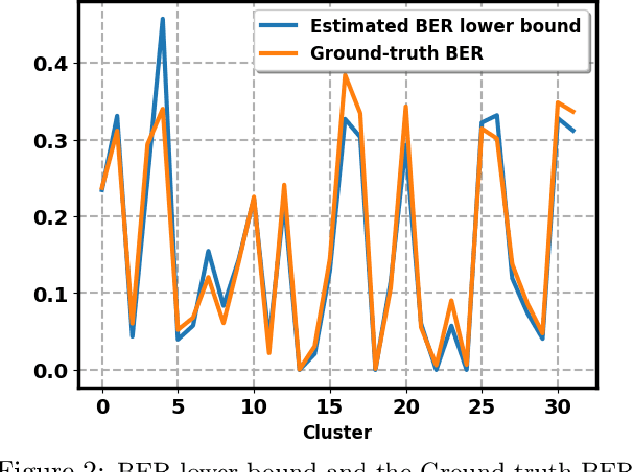
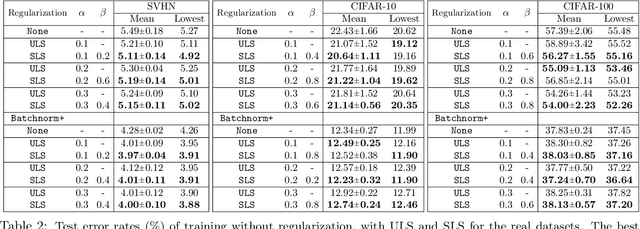
Regularization is an effective way to promote the generalization performance of machine learning models. In this paper, we focus on label smoothing, a form of output distribution regularization that prevents overfitting of a neural network by softening the ground-truth labels in the training data in an attempt to penalize overconfident outputs. Existing approaches typically use cross-validation to impose this smoothing, which is uniform across all training data. In this paper, we show that such label smoothing imposes a quantifiable bias in the Bayes error rate of the training data, with regions of the feature space with high overlap and low marginal likelihood having a lower bias and regions of low overlap and high marginal likelihood having a higher bias. These theoretical results motivate a simple objective function for data-dependent smoothing to mitigate the potential negative consequences of the operation while maintaining its desirable properties as a regularizer. We call this approach Structural Label Smoothing (SLS). We implement SLS and empirically validate on synthetic, Higgs, SVHN, CIFAR-10, and CIFAR-100 datasets. The results confirm our theoretical insights and demonstrate the effectiveness of the proposed method in comparison to traditional label smoothing.
Time-weighted Attentional Session-Aware Recommender System
Sep 12, 2019



Session-based Recurrent Neural Networks (RNNs) are gaining increasing popularity for recommendation task, due to the high autocorrelation of user's behavior on the latest session and the effectiveness of RNN to capture the sequence order information. However, most existing session-based RNN recommender systems still solely focus on the short-term interactions within a single session and completely discard all the other long-term data across different sessions. While traditional Collaborative Filtering (CF) methods have many advanced research works on exploring long-term dependency, which show great value to be explored and exploited in deep learning models. Therefore, in this paper, we propose ASARS, a novel framework that effectively imports the temporal dynamics methodology in CF into session-based RNN system in DL, such that the temporal info can act as scalable weights by a parallel attentional network. Specifically, we first conduct an extensive data analysis to show the distribution and importance of such temporal interactions data both within sessions and across sessions. And then, our ASARS framework promotes two novel models: (1) an inter-session temporal dynamic model that captures the long-term user interaction for RNN recommender system. We integrate the time changes in session RNN and add user preferences as model drifting; and (2) a novel triangle parallel attention network that enhances the original RNN model by incorporating time information. Such triangle parallel network is also specially designed for realizing data argumentation in sequence-to-scalar RNN architecture, and thus it can be trained very efficiently. Our extensive experiments on four real datasets from different domains demonstrate the effectiveness and large improvement of ASARS for personalized recommendation.