 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-based Cognitive-linguistic Features for Dementia Assessment in Picture Description
Jun 16, 2026Picture descriptions provide valuable insights into several clinical constructs related to cognitive-linguistic abilities. However, operationalizing these constructs into quantitative measures remains challenging, limiting interpretability and clinical utility. We introduced seven constructs tailored to the Cookie Theft picture description task and prompted large language models (LLMs) to evaluate them, generating severity scores and example-based explanations. Among the examined LLMs, Claude 3.5 Sonnet performed the best, producing severity scores that significantly distinguish cognitively impaired individuals from healthy controls. The model achieves a high accuracy of 85% on the ADReSS dataset. Expert evaluation of Claude's scores and explanations yields a 3.99/5 average agreement. The findings demonstrate the potential of LLMs to operationalize clinical constructs and generate interpretable evaluations, offering a promising approach for accessible cognitive screening tools.
Active Sequential Two-Sample Testing
Feb 02, 2023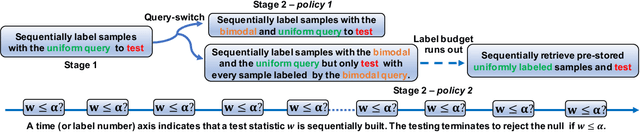
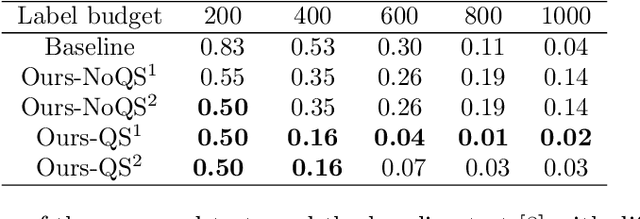
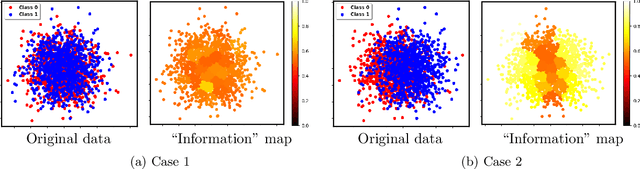

Two-sample testing tests whether the distributions generating two samples are identical. We pose the two-sample testing problem in a new scenario where the sample measurements (or sample features) are inexpensive to access, but their group memberships (or labels) are costly. We devise the first \emph{active sequential two-sample testing framework} that not only sequentially but also \emph{actively queries} sample labels to address the problem. Our test statistic is a likelihood ratio where one likelihood is found by maximization over all class priors, and the other is given by a classification model. The classification model is adaptively updated and then used to guide an active query scheme called bimodal query to label sample features in the regions with high dependency between the feature variables and the label variables. The theoretical contributions in the paper include proof that our framework produces an \emph{anytime-valid} $p$-value; and, under reachable conditions and a mild assumption, the framework asymptotically generates a minimum normalized log-likelihood ratio statistic that a passive query scheme can only achieve when the feature variable and the label variable have the highest dependence. Lastly, we provide a \emph{query-switching (QS)} algorithm to decide when to switch from passive query to active query and adapt bimodal query to increase the testing power of our test. Extensive experiments justify our theoretical contributions and the effectiveness of QS.
Noisy Machines: Understanding Noisy Neural Networks and Enhancing Robustness to Analog Hardware Errors Using Distillation
Jan 14, 2020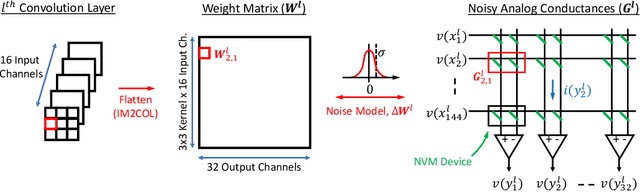
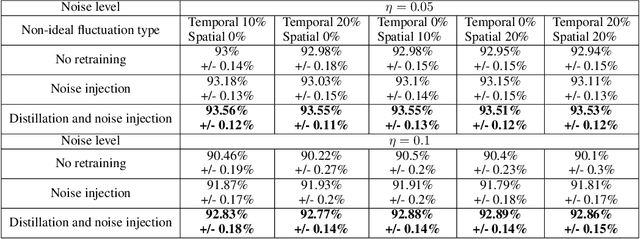
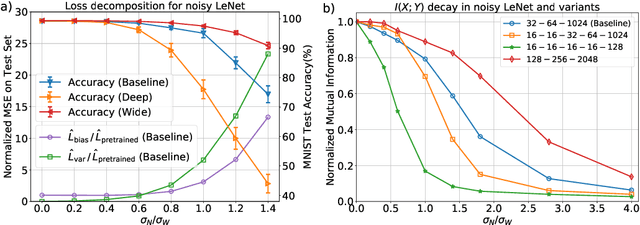
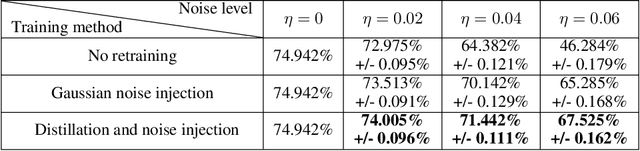
The success of deep learning has brought forth a wave of interest in computer hardware design to better meet the high demands of neural network inference. In particular, analog computing hardware has been heavily motivated specifically for accelerating neural networks, based on either electronic, optical or photonic devices, which may well achieve lower power consumption than conventional digital electronics. However, these proposed analog accelerators suffer from the intrinsic noise generated by their physical components, which makes it challenging to achieve high accuracy on deep neural networks. Hence, for successful deployment on analog accelerators, it is essential to be able to train deep neural networks to be robust to random continuous noise in the network weights, which is a somewhat new challenge in machine learning. In this paper, we advance the understanding of noisy neural networks. We outline how a noisy neural network has reduced learning capacity as a result of loss of mutual information between its input and output. To combat this, we propose using knowledge distillation combined with noise injection during training to achieve more noise robust networks, which is demonstrated experimentally across different networks and datasets, including ImageNet. Our method achieves models with as much as two times greater noise tolerance compared with the previous best attempts, which is a significant step towards making analog hardware practical for deep learning.