 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV.O.I.C.E (Voice, Ownership, Identity, Control, Expression): Risk Taxonomy of Synthetic Voice Generation From Empirical Data
Apr 25, 2026As generative voice models are rapidly advancing in both capabilities and public utilization, the unconsented collection, reuse, and synthesis of voice data are introducing new classes of privacy, security and governance risk that are poorly captured by existing, largely uniform threat models. To fill the gap, we present V.O.I.C.E, a taxonomy of voice generation risk grounded in a multi-source threat modeling effort with 569 incidents from major AI incident database, FTC and Internet Crime Complaint Center (IC3); 1067 direct incident reports from U.S. based participants across diverse groups (including voice actors, internet personalities, political personnel, and general public); and 2,221 Reddit discussions. Grounded in real-world data, our taxonomy explicitly models how risk emerges, interact with contextual factors such as degree of exposure, social visibility, and the availability of legal protections for various affected groups.
Multilingual Dysarthric Speech Assessment Using Universal Phone Recognition and Language-Specific Phonemic Contrast Modeling
Jan 29, 2026The growing prevalence of neurological disorders associated with dysarthria motivates the need for automated intelligibility assessment methods that are applicalbe across languages. However, most existing approaches are either limited to a single language or fail to capture language-specific factors shaping intelligibility. We present a multilingual phoneme-production assessment framework that integrates universal phone recognition with language-specific phoneme interpretation using contrastive phonological feature distances for phone-to-phoneme mapping and sequence alignment. The framework yields three metrics: phoneme error rate (PER), phonological feature error rate (PFER), and a newly proposed alignment-free measure, phoneme coverage (PhonCov). Analysis on English, Spanish, Italian, and Tamil show that PER benefits from the combination of mapping and alignment, PFER from alignment alone, and PhonCov from mapping. Further analyses demonstrate that the proposed framework captures clinically meaningful patterns of intelligibility degradation consistent with established observations of dysarthric speech.
Statistically Valid Post-Deployment Monitoring Should Be Standard for AI-Based Digital Health
Jun 06, 2025This position paper argues that post-deployment monitoring in clinical AI is underdeveloped and proposes statistically valid and label-efficient testing frameworks as a principled foundation for ensuring reliability and safety in real-world deployment. A recent review found that only 9% of FDA-registered AI-based healthcare tools include a post-deployment surveillance plan. Existing monitoring approaches are often manual, sporadic, and reactive, making them ill-suited for the dynamic environments in which clinical models operate. We contend that post-deployment monitoring should be grounded in label-efficient and statistically valid testing frameworks, offering a principled alternative to current practices. We use the term "statistically valid" to refer to methods that provide explicit guarantees on error rates (e.g., Type I/II error), enable formal inference under pre-defined assumptions, and support reproducibility--features that align with regulatory requirements. Specifically, we propose that the detection of changes in the data and model performance degradation should be framed as distinct statistical hypothesis testing problems. Grounding monitoring in statistical rigor ensures a reproducible and scientifically sound basis for maintaining the reliability of clinical AI systems. Importantly, it also opens new research directions for the technical community--spanning theory, methods, and tools for statistically principled detection, attribution, and mitigation of post-deployment model failures in real-world settings.
A Speech Production Model for Radar: Connecting Speech Acoustics with Radar-Measured Vibrations
Mar 19, 2025Millimeter Wave (mmWave) radar has emerged as a promising modality for speech sensing, offering advantages over traditional microphones. Prior works have demonstrated that radar captures motion signals related to vocal vibrations, but there is a gap in the understanding of the analytical connection between radar-measured vibrations and acoustic speech signals. We establish a mathematical framework linking radar-captured neck vibrations to speech acoustics. We derive an analytical relationship between neck surface displacements and speech. We use data from 66 human participants, and statistical spectral distance analysis to empirically assess the model. Our results show that the radar-measured signal aligns more closely with our model filtered vibration signal derived from speech than with raw speech itself. These findings provide a foundation for improved radar-based speech processing for applications in speech enhancement, coding, surveillance, and authentication.
Automated Extraction of Spatio-Semantic Graphs for Identifying Cognitive Impairment
Feb 02, 2025



Existing methods for analyzing linguistic content from picture descriptions for assessment of cognitive-linguistic impairment often overlook the participant's visual narrative path, which typically requires eye tracking to assess. Spatio-semantic graphs are a useful tool for analyzing this narrative path from transcripts alone, however they are limited by the need for manual tagging of content information units (CIUs). In this paper, we propose an automated approach for estimation of spatio-semantic graphs (via automated extraction of CIUs) from the Cookie Theft picture commonly used in cognitive-linguistic analyses. The method enables the automatic characterization of the visual semantic path during picture description. Experiments demonstrate that the automatic spatio-semantic graphs effectively differentiate between cognitively impaired and unimpaired speakers. Statistical analyses reveal that the features derived by the automated method produce comparable results to the manual method, with even greater group differences between clinical groups of interest. These results highlight the potential of the automated approach for extracting spatio-semantic features in developing clinical speech models for cognitive impairment assessment.
Advanced Tutorial: Label-Efficient Two-Sample Tests
Jan 07, 2025

Hypothesis testing is a statistical inference approach used to determine whether data supports a specific hypothesis. An important type is the two-sample test, which evaluates whether two sets of data points are from identical distributions. This test is widely used, such as by clinical researchers comparing treatment effectiveness. This tutorial explores two-sample testing in a context where an analyst has many features from two samples, but determining the sample membership (or labels) of these features is costly. In machine learning, a similar scenario is studied in active learning. This tutorial extends active learning concepts to two-sample testing within this \textit{label-costly} setting while maintaining statistical validity and high testing power. Additionally, the tutorial discusses practical applications of these label-efficient two-sample tests.
A Tutorial on Clinical Speech AI Development: From Data Collection to Model Validation
Oct 29, 2024There has been a surge of interest in leveraging speech as a marker of health for a wide spectrum of conditions. The underlying premise is that any neurological, mental, or physical deficits that impact speech production can be objectively assessed via automated analysis of speech. Recent advances in speech-based Artificial Intelligence (AI) models for diagnosing and tracking mental health, cognitive, and motor disorders often use supervised learning, similar to mainstream speech technologies like recognition and verification. However, clinical speech AI has distinct challenges, including the need for specific elicitation tasks, small available datasets, diverse speech representations, and uncertain diagnostic labels. As a result, application of the standard supervised learning paradigm may lead to models that perform well in controlled settings but fail to generalize in real-world clinical deployments. With translation into real-world clinical scenarios in mind, this tutorial paper provides an overview of the key components required for robust development of clinical speech AI. Specifically, this paper will cover the design of speech elicitation tasks and protocols most appropriate for different clinical conditions, collection of data and verification of hardware, development and validation of speech representations designed to measure clinical constructs of interest, development of reliable and robust clinical prediction models, and ethical and participant considerations for clinical speech AI. The goal is to provide comprehensive guidance on building models whose inputs and outputs link to the more interpretable and clinically meaningful aspects of speech, that can be interrogated and clinically validated on clinical datasets, and that adhere to ethical, privacy, and security considerations by design.
Unraveling overoptimism and publication bias in ML-driven science
May 23, 2024



Machine Learning (ML) is increasingly used across many disciplines with impressive reported results across many domain areas. However, recent studies suggest that the published performance of ML models are often overoptimistic and not reflective of true accuracy were these models to be deployed. Validity concerns are underscored by findings of a concerning inverse relationship between sample size and reported accuracy in published ML models across several domains. This is in contrast with the theory of learning curves in ML, where we expect accuracy to improve or stay the same with increasing sample size. This paper investigates the factors contributing to overoptimistic accuracy reports in ML-based science, focusing on data leakage and publication bias. Our study introduces a novel stochastic model for observed accuracy, integrating parametric learning curves and the above biases. We then construct an estimator based on this model that corrects for these biases in observed data. Theoretical and empirical results demonstrate that this framework can estimate the underlying learning curve that gives rise to the observed overoptimistic results, thereby providing more realistic performance assessments of ML performance from a collection of published results. We apply the model to various meta-analyses in the digital health literature, including neuroimaging-based and speech-based classifications of several neurological conditions. Our results indicate prevalent overoptimism across these fields and we estimate the inherent limits of ML-based prediction in each domain.
Learning Repeatable Speech Embeddings Using An Intra-class Correlation Regularizer
Oct 25, 2023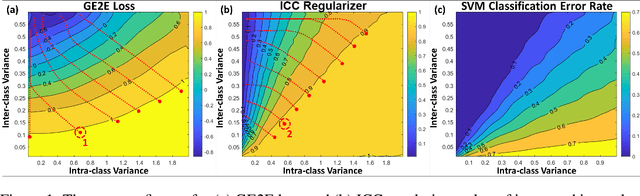
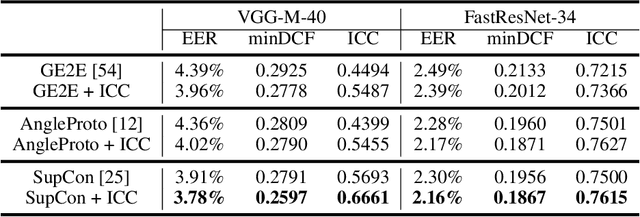


A good supervised embedding for a specific machine learning task is only sensitive to changes in the label of interest and is invariant to other confounding factors. We leverage the concept of repeatability from measurement theory to describe this property and propose to use the intra-class correlation coefficient (ICC) to evaluate the repeatability of embeddings. We then propose a novel regularizer, the ICC regularizer, as a complementary component for contrastive losses to guide deep neural networks to produce embeddings with higher repeatability. We use simulated data to explain why the ICC regularizer works better on minimizing the intra-class variance than the contrastive loss alone. We implement the ICC regularizer and apply it to three speech tasks: speaker verification, voice style conversion, and a clinical application for detecting dysphonic voice. The experimental results demonstrate that adding an ICC regularizer can improve the repeatability of learned embeddings compared to only using the contrastive loss; further, these embeddings lead to improved performance in these downstream tasks.
Requirements for Mass Adoption of Assistive Listening Technology by the General Public
Mar 04, 2023Assistive listening systems (ALSs) dramatically increase speech intelligibility and reduce listening effort. It is very likely that essentially everyone, not only individuals with hearing loss, would benefit from the increased signal-to-noise ratio an ALS provides in almost any listening scenario. However, ALSs are rarely used by anyone other than people with severe to profound hearing losses. To date, the reasons for this poor adoption have not been systematically investigated. The authors hypothesize that the reasons for poor adoption of assistive listening technology include (1) an inability to use personally owned receiving devices, (2) a lack of high-fidelity stereo sound, (3) receiving devices not providing an unoccluded listening experience, (4) distortion from alignment delay and (5) a lack of automatic connectivity to an available assistive listening audio signal. We propose solutions to each of these problems in an effort to pave the way for mass adoption of assistive listening technology.