 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Speech Production Model for Radar: Connecting Speech Acoustics with Radar-Measured Vibrations
Mar 19, 2025Millimeter Wave (mmWave) radar has emerged as a promising modality for speech sensing, offering advantages over traditional microphones. Prior works have demonstrated that radar captures motion signals related to vocal vibrations, but there is a gap in the understanding of the analytical connection between radar-measured vibrations and acoustic speech signals. We establish a mathematical framework linking radar-captured neck vibrations to speech acoustics. We derive an analytical relationship between neck surface displacements and speech. We use data from 66 human participants, and statistical spectral distance analysis to empirically assess the model. Our results show that the radar-measured signal aligns more closely with our model filtered vibration signal derived from speech than with raw speech itself. These findings provide a foundation for improved radar-based speech processing for applications in speech enhancement, coding, surveillance, and authentication.
Automated Extraction of Spatio-Semantic Graphs for Identifying Cognitive Impairment
Feb 02, 2025



Existing methods for analyzing linguistic content from picture descriptions for assessment of cognitive-linguistic impairment often overlook the participant's visual narrative path, which typically requires eye tracking to assess. Spatio-semantic graphs are a useful tool for analyzing this narrative path from transcripts alone, however they are limited by the need for manual tagging of content information units (CIUs). In this paper, we propose an automated approach for estimation of spatio-semantic graphs (via automated extraction of CIUs) from the Cookie Theft picture commonly used in cognitive-linguistic analyses. The method enables the automatic characterization of the visual semantic path during picture description. Experiments demonstrate that the automatic spatio-semantic graphs effectively differentiate between cognitively impaired and unimpaired speakers. Statistical analyses reveal that the features derived by the automated method produce comparable results to the manual method, with even greater group differences between clinical groups of interest. These results highlight the potential of the automated approach for extracting spatio-semantic features in developing clinical speech models for cognitive impairment assessment.
A Tutorial on Clinical Speech AI Development: From Data Collection to Model Validation
Oct 29, 2024There has been a surge of interest in leveraging speech as a marker of health for a wide spectrum of conditions. The underlying premise is that any neurological, mental, or physical deficits that impact speech production can be objectively assessed via automated analysis of speech. Recent advances in speech-based Artificial Intelligence (AI) models for diagnosing and tracking mental health, cognitive, and motor disorders often use supervised learning, similar to mainstream speech technologies like recognition and verification. However, clinical speech AI has distinct challenges, including the need for specific elicitation tasks, small available datasets, diverse speech representations, and uncertain diagnostic labels. As a result, application of the standard supervised learning paradigm may lead to models that perform well in controlled settings but fail to generalize in real-world clinical deployments. With translation into real-world clinical scenarios in mind, this tutorial paper provides an overview of the key components required for robust development of clinical speech AI. Specifically, this paper will cover the design of speech elicitation tasks and protocols most appropriate for different clinical conditions, collection of data and verification of hardware, development and validation of speech representations designed to measure clinical constructs of interest, development of reliable and robust clinical prediction models, and ethical and participant considerations for clinical speech AI. The goal is to provide comprehensive guidance on building models whose inputs and outputs link to the more interpretable and clinically meaningful aspects of speech, that can be interrogated and clinically validated on clinical datasets, and that adhere to ethical, privacy, and security considerations by design.
Requirements for Mass Adoption of Assistive Listening Technology by the General Public
Mar 04, 2023Assistive listening systems (ALSs) dramatically increase speech intelligibility and reduce listening effort. It is very likely that essentially everyone, not only individuals with hearing loss, would benefit from the increased signal-to-noise ratio an ALS provides in almost any listening scenario. However, ALSs are rarely used by anyone other than people with severe to profound hearing losses. To date, the reasons for this poor adoption have not been systematically investigated. The authors hypothesize that the reasons for poor adoption of assistive listening technology include (1) an inability to use personally owned receiving devices, (2) a lack of high-fidelity stereo sound, (3) receiving devices not providing an unoccluded listening experience, (4) distortion from alignment delay and (5) a lack of automatic connectivity to an available assistive listening audio signal. We propose solutions to each of these problems in an effort to pave the way for mass adoption of assistive listening technology.
Robust Vocal Quality Feature Embeddings for Dysphonic Voice Detection
Nov 17, 2022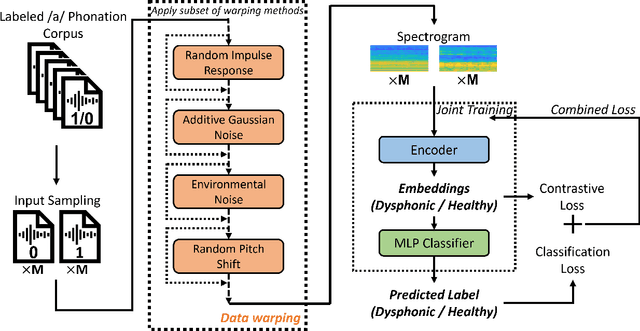
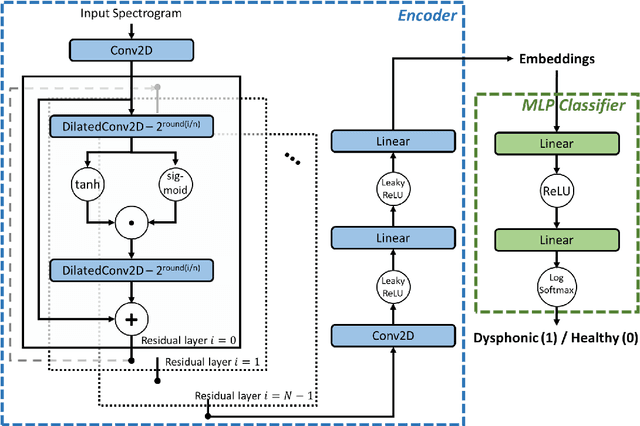
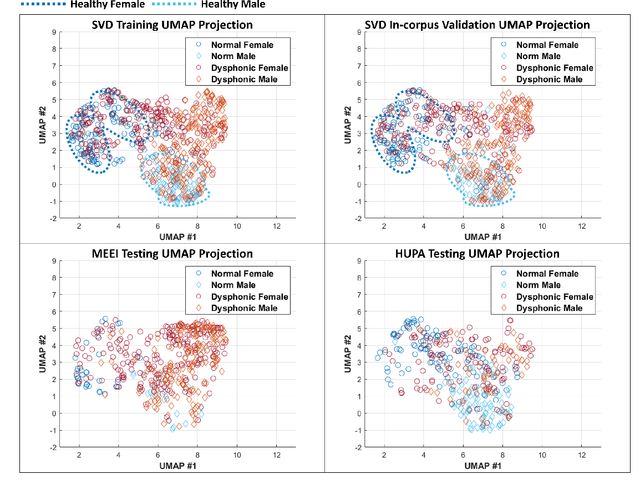
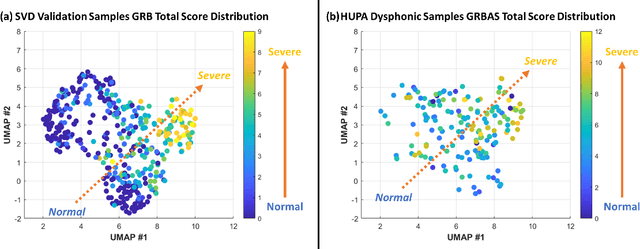
Approximately 1.2% of the world's population has impaired voice production. As a result, automatic dysphonic voice detection has attracted considerable academic and clinical interest. However, existing methods for automated voice assessment often fail to generalize outside the training conditions or to other related applications. In this paper, we propose a deep learning framework for generating acoustic feature embeddings sensitive to vocal quality and robust across different corpora. A contrastive loss is combined with a classification loss to train our deep learning model jointly. Data warping methods are used on input voice samples to improve the robustness of our method. Empirical results demonstrate that our method not only achieves high in-corpus and cross-corpus classification accuracy but also generates good embeddings sensitive to voice quality and robust across different corpora. We also compare our results against three baseline methods on clean and three variations of deteriorated in-corpus and cross-corpus datasets and demonstrate that the proposed model consistently outperforms the baseline methods.
TorchDIVA: An Extensible Computational Model of Speech Production built on an Open-Source Machine Learning Library
Oct 17, 2022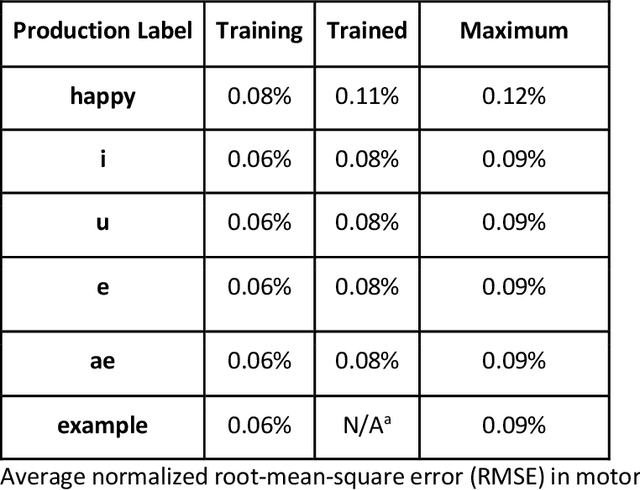
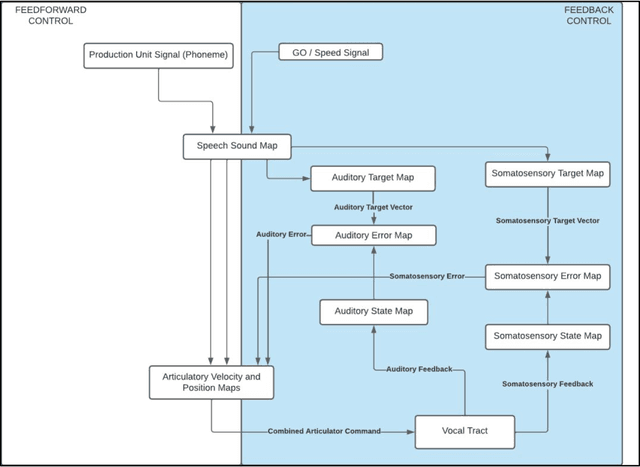
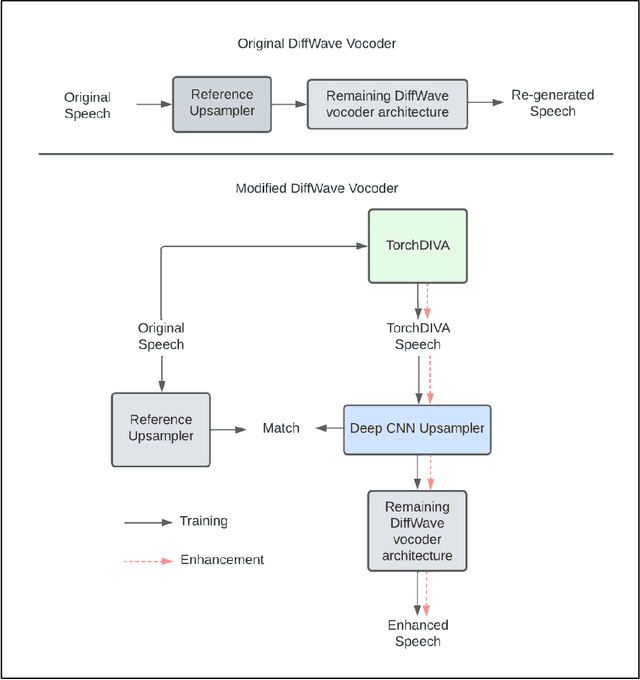
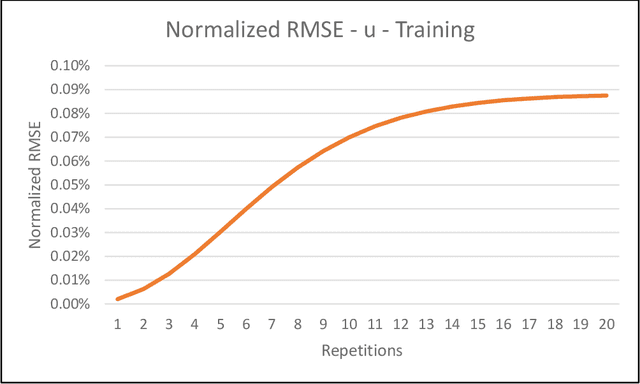
The DIVA model is a computational model of speech motor control that combines a simulation of the brain regions responsible for speech production with a model of the human vocal tract. The model is currently implemented in Matlab Simulink; however, this is less than ideal as most of the development in speech technology research is done in Python. This means there is a wealth of machine learning tools which are freely available in the Python ecosystem that cannot be easily integrated with DIVA. We present TorchDIVA, a full rebuild of DIVA in Python using PyTorch tensors. DIVA source code was directly translated from Matlab to Python, and built-in Simulink signal blocks were implemented from scratch. After implementation, the accuracy of each module was evaluated via systematic block-by-block validation. The TorchDIVA model is shown to produce outputs that closely match those of the original DIVA model, with a negligible difference between the two. We additionally present an example of the extensibility of TorchDIVA as a research platform. Speech quality enhancement in TorchDIVA is achieved through an integration with an existing PyTorch generative vocoder called DiffWave. A modified DiffWave mel-spectrum upsampler was trained on human speech waveforms and conditioned on the TorchDIVA speech production. The results indicate improved speech quality metrics in the DiffWave-enhanced output as compared to the baseline. This enhancement would have been difficult or impossible to accomplish in the original Matlab implementation. This proof-of-concept demonstrates the value TorchDIVA will bring to the research community. Researchers can download the new implementation at: https://github.com/skinahan/DIVA_PyTorch