 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Extraction of Spatio-Semantic Graphs for Identifying Cognitive Impairment
Feb 02, 2025



Existing methods for analyzing linguistic content from picture descriptions for assessment of cognitive-linguistic impairment often overlook the participant's visual narrative path, which typically requires eye tracking to assess. Spatio-semantic graphs are a useful tool for analyzing this narrative path from transcripts alone, however they are limited by the need for manual tagging of content information units (CIUs). In this paper, we propose an automated approach for estimation of spatio-semantic graphs (via automated extraction of CIUs) from the Cookie Theft picture commonly used in cognitive-linguistic analyses. The method enables the automatic characterization of the visual semantic path during picture description. Experiments demonstrate that the automatic spatio-semantic graphs effectively differentiate between cognitively impaired and unimpaired speakers. Statistical analyses reveal that the features derived by the automated method produce comparable results to the manual method, with even greater group differences between clinical groups of interest. These results highlight the potential of the automated approach for extracting spatio-semantic features in developing clinical speech models for cognitive impairment assessment.
A Tutorial on Clinical Speech AI Development: From Data Collection to Model Validation
Oct 29, 2024There has been a surge of interest in leveraging speech as a marker of health for a wide spectrum of conditions. The underlying premise is that any neurological, mental, or physical deficits that impact speech production can be objectively assessed via automated analysis of speech. Recent advances in speech-based Artificial Intelligence (AI) models for diagnosing and tracking mental health, cognitive, and motor disorders often use supervised learning, similar to mainstream speech technologies like recognition and verification. However, clinical speech AI has distinct challenges, including the need for specific elicitation tasks, small available datasets, diverse speech representations, and uncertain diagnostic labels. As a result, application of the standard supervised learning paradigm may lead to models that perform well in controlled settings but fail to generalize in real-world clinical deployments. With translation into real-world clinical scenarios in mind, this tutorial paper provides an overview of the key components required for robust development of clinical speech AI. Specifically, this paper will cover the design of speech elicitation tasks and protocols most appropriate for different clinical conditions, collection of data and verification of hardware, development and validation of speech representations designed to measure clinical constructs of interest, development of reliable and robust clinical prediction models, and ethical and participant considerations for clinical speech AI. The goal is to provide comprehensive guidance on building models whose inputs and outputs link to the more interpretable and clinically meaningful aspects of speech, that can be interrogated and clinically validated on clinical datasets, and that adhere to ethical, privacy, and security considerations by design.
Automatic Detection of Speech Sound Disorder in Child Speech Using Posterior-based Speaker Representations
Mar 29, 2022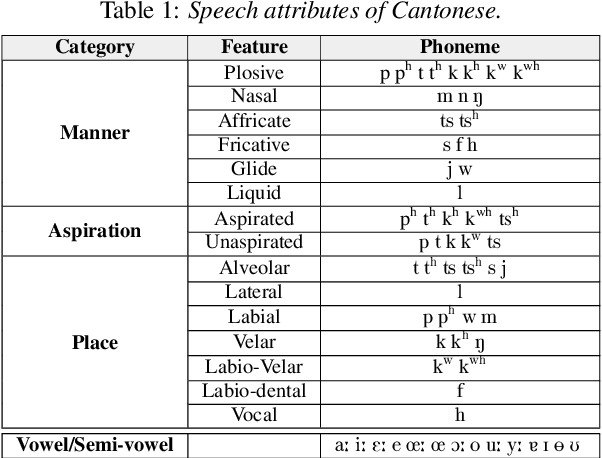
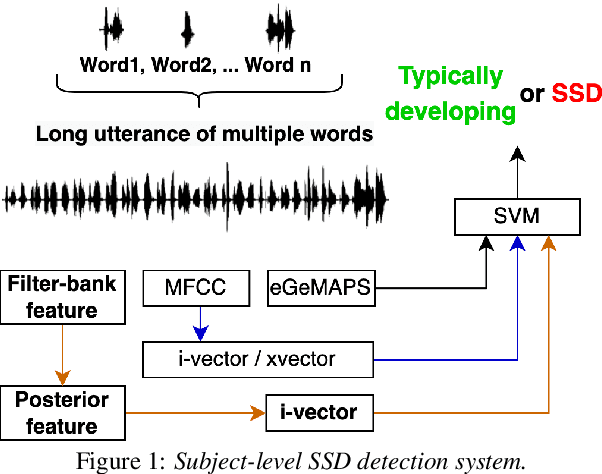


This paper presents a macroscopic approach to automatic detection of speech sound disorder (SSD) in child speech. Typically, SSD is manifested by persistent articulation and phonological errors on specific phonemes in the language. The disorder can be detected by focally analyzing the phonemes or the words elicited by the child subject. In the present study, instead of attempting to detect individual phone- and word-level errors, we propose to extract a subject-level representation from a long utterance that is constructed by concatenating multiple test words. The speaker verification approach, and posterior features generated by deep neural network models, are applied to derive various types of holistic representations. A linear classifier is trained to differentiate disordered speech in normal one. On the task of detecting SSD in Cantonese-speaking children, experimental results show that the proposed approach achieves improved detection performance over previous method that requires fusing phone-level detection results. Using articulatory posterior features to derive i-vectors from multiple-word utterances achieves an unweighted average recall of 78.2% and a macro F1 score of 78.0%.
Acoustical Analysis of Speech Under Physical Stress in Relation to Physical Activities and Physical Literacy
Nov 20, 2021
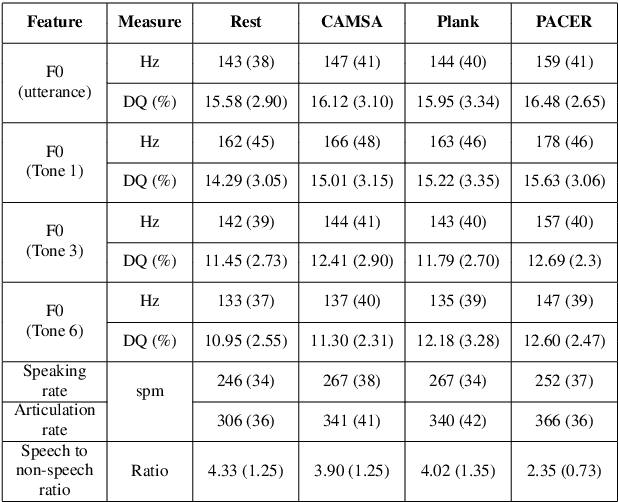
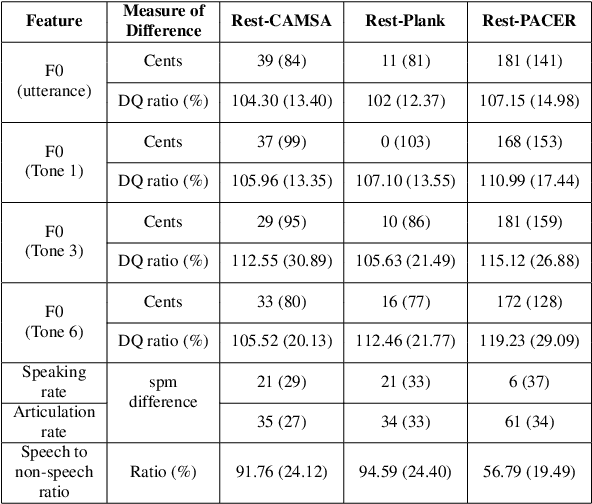
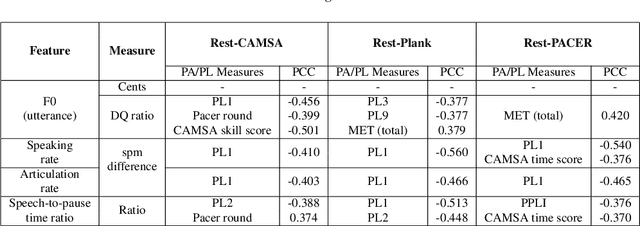
Human speech production encompasses physiological processes that naturally react to physic stress. Stress caused by physical activity (PA), e.g., running, may lead to significant changes in a person's speech. The major changes are related to the aspects of pitch level, speaking rate, pause pattern, and breathiness. The extent of change depends presumably on physical fitness and well-being of the person, as well as intensity of PA. The general wellness of a person is further related to his/her physical literacy (PL), which refers to a holistic description of engagement in PA. This paper presents the development of a Cantonese speech database that contains audio recordings of speech before and after physical exercises of different intensity levels. The corpus design and data collection process are described. Preliminary results of acoustical analysis are presented to illustrate the impact of PA on pitch level, pitch range, speaking and articulation rate, and time duration of pauses. It is also noted that the effect of PA is correlated to some of the PA and PL measures.
Data Augmentation with Locally-time Reversed Speech for Automatic Speech Recognition
Oct 09, 2021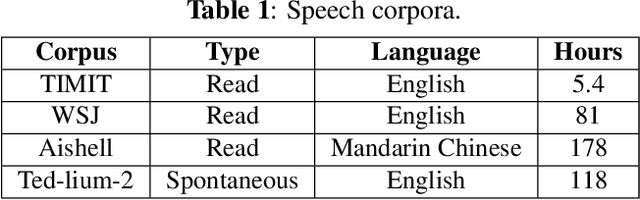



Psychoacoustic studies have shown that locally-time reversed (LTR) speech, i.e., signal samples time-reversed within a short segment, can be accurately recognised by human listeners. This study addresses the question of how well a state-of-the-art automatic speech recognition (ASR) system would perform on LTR speech. The underlying objective is to explore the feasibility of deploying LTR speech in the training of end-to-end (E2E) ASR models, as an attempt to data augmentation for improving the recognition performance. The investigation starts with experiments to understand the effect of LTR speech on general-purpose ASR. LTR speech with reversed segment duration of 5 ms - 50 ms is rendered and evaluated. For ASR training data augmentation with LTR speech, training sets are created by combining natural speech with different partitions of LTR speech. The efficacy of data augmentation is confirmed by ASR results on speech corpora in various languages and speaking styles. ASR on LTR speech with reversed segment duration of 15 ms - 30 ms is found to have lower error rate than with other segment duration. Data augmentation with these LTR speech achieves satisfactory and consistent improvement on ASR performance.
Exploiting Pre-Trained ASR Models for Alzheimer's Disease Recognition Through Spontaneous Speech
Oct 04, 2021
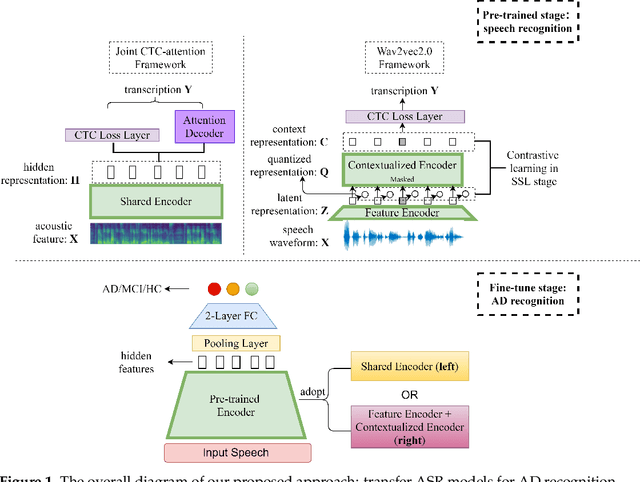
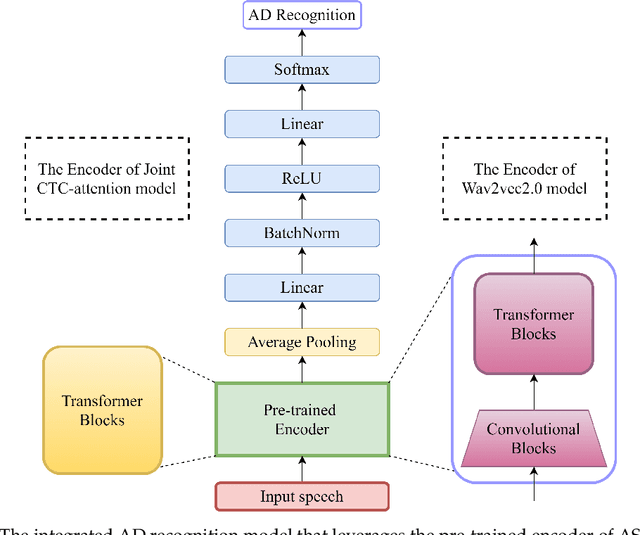
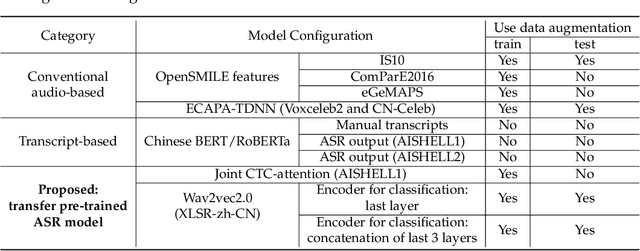
Alzheimer's disease (AD) is a progressive neurodegenerative disease and recently attracts extensive attention worldwide. Speech technology is considered a promising solution for the early diagnosis of AD and has been enthusiastically studied. Most recent works concentrate on the use of advanced BERT-like classifiers for AD detection. Input to these classifiers are speech transcripts produced by automatic speech recognition (ASR) models. The major challenge is that the quality of transcription could degrade significantly under complex acoustic conditions in the real world. The detection performance, in consequence, is largely limited. This paper tackles the problem via tailoring and adapting pre-trained neural-network based ASR model for the downstream AD recognition task. Only bottom layers of the ASR model are retained. A simple fully-connected neural network is added on top of the tailored ASR model for classification. The heavy BERT classifier is discarded. The resulting model is light-weight and can be fine-tuned in an end-to-end manner for AD recognition. Our proposed approach takes only raw speech as input, and no extra transcription process is required. The linguistic information of speech is implicitly encoded in the tailored ASR model and contributes to boosting the performance. Experiments show that our proposed approach outperforms the best manual transcript-based RoBERTa by an absolute margin of 4.6% in terms of accuracy. Our best-performing models achieve the accuracy of 83.2% and 78.0% in the long-audio and short-audio competition tracks of the 2021 NCMMSC Alzheimer's Disease Recognition Challenge, respectively.
Improving Text-Independent Speaker Verification with Auxiliary Speakers Using Graph
Sep 20, 2021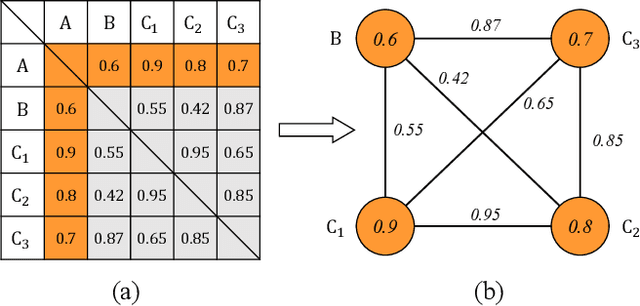
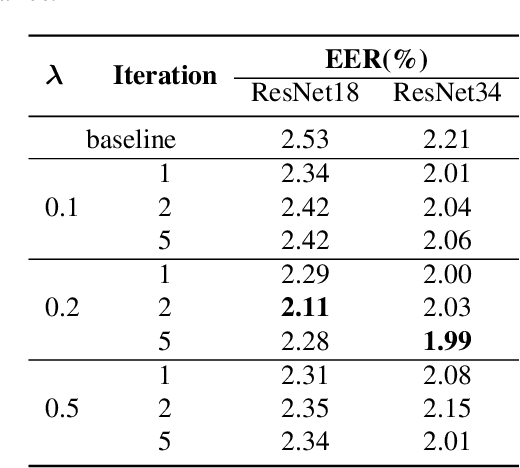

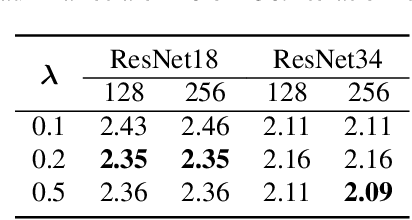
The paper presents a novel approach to refining similarity scores between input utterances for robust speaker verification. Given the embeddings from a pair of input utterances, a graph model is designed to incorporate additional information from a group of embeddings representing the so-called auxiliary speakers. The relations between the input utterances and the auxiliary speakers are represented by the edges and vertices in the graph. The similarity scores are refined by iteratively updating the values of the graph's vertices using an algorithm similar to the random walk algorithm on graphs. Through this updating process, the information of auxiliary speakers is involved in determining the relation between input utterances and hence contributing to the verification process. We propose to create a set of artificial embeddings through the model training process. Utilizing the generated embeddings as auxiliary speakers, no extra data are required for the graph model in the verification stage. The proposed model is trained in an end-to-end manner within the whole system. Experiments are carried out with the Voxceleb datasets. The results indicate that involving auxiliary speakers with graph is effective to improve speaker verification performance.
Detection of Consonant Errors in Disordered Speech Based on Consonant-vowel Segment Embedding
Jun 16, 2021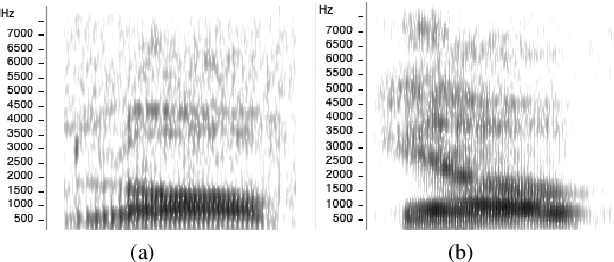
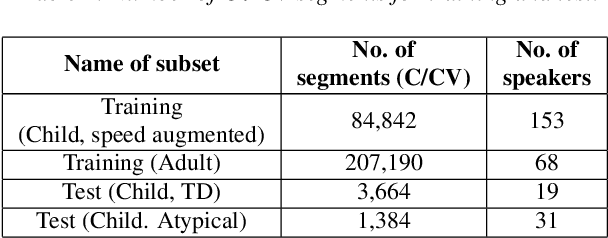

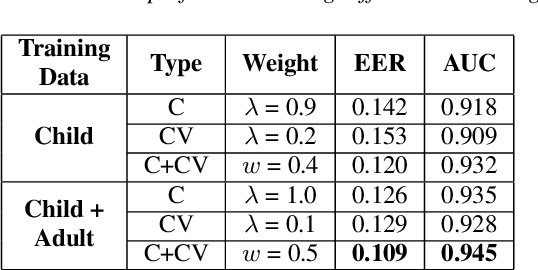
Speech sound disorder (SSD) refers to a type of developmental disorder in young children who encounter persistent difficulties in producing certain speech sounds at the expected age. Consonant errors are the major indicator of SSD in clinical assessment. Previous studies on automatic assessment of SSD revealed that detection of speech errors concerning short and transitory consonants is less satisfactory. This paper investigates a neural network based approach to detecting consonant errors in disordered speech using consonant-vowel (CV) diphone segment in comparison to using consonant monophone segment. The underlying assumption is that the vowel part of a CV segment carries important information of co-articulation from the consonant. Speech embeddings are extracted from CV segments by a recurrent neural network model. The similarity scores between the embeddings of the test segment and the reference segments are computed to determine if the test segment is the expected consonant or not. Experimental results show that using CV segments achieves improved performance on detecting speech errors concerning those "difficult" consonants reported in the previous studies.