 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation with Locally-time Reversed Speech for Automatic Speech Recognition
Paper and Code
Oct 09, 2021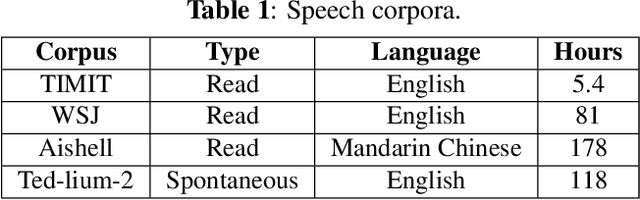



Psychoacoustic studies have shown that locally-time reversed (LTR) speech, i.e., signal samples time-reversed within a short segment, can be accurately recognised by human listeners. This study addresses the question of how well a state-of-the-art automatic speech recognition (ASR) system would perform on LTR speech. The underlying objective is to explore the feasibility of deploying LTR speech in the training of end-to-end (E2E) ASR models, as an attempt to data augmentation for improving the recognition performance. The investigation starts with experiments to understand the effect of LTR speech on general-purpose ASR. LTR speech with reversed segment duration of 5 ms - 50 ms is rendered and evaluated. For ASR training data augmentation with LTR speech, training sets are created by combining natural speech with different partitions of LTR speech. The efficacy of data augmentation is confirmed by ASR results on speech corpora in various languages and speaking styles. ASR on LTR speech with reversed segment duration of 15 ms - 30 ms is found to have lower error rate than with other segment duration. Data augmentation with these LTR speech achieves satisfactory and consistent improvement on ASR performance.