 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Detection of Speech Sound Disorder in Child Speech Using Posterior-based Speaker Representations
Mar 29, 2022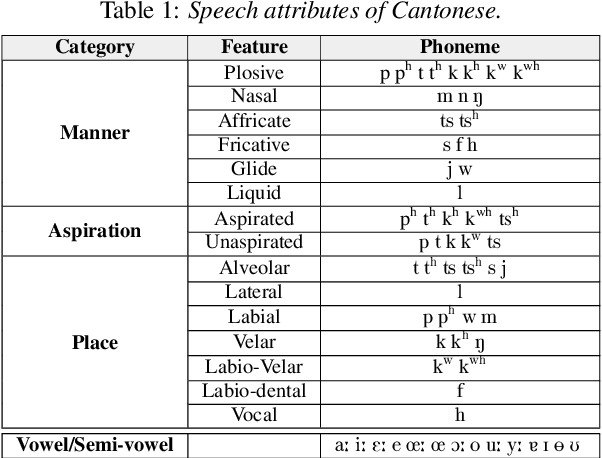
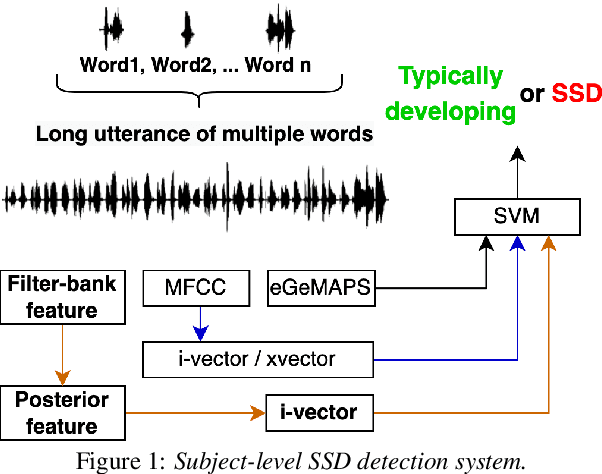


This paper presents a macroscopic approach to automatic detection of speech sound disorder (SSD) in child speech. Typically, SSD is manifested by persistent articulation and phonological errors on specific phonemes in the language. The disorder can be detected by focally analyzing the phonemes or the words elicited by the child subject. In the present study, instead of attempting to detect individual phone- and word-level errors, we propose to extract a subject-level representation from a long utterance that is constructed by concatenating multiple test words. The speaker verification approach, and posterior features generated by deep neural network models, are applied to derive various types of holistic representations. A linear classifier is trained to differentiate disordered speech in normal one. On the task of detecting SSD in Cantonese-speaking children, experimental results show that the proposed approach achieves improved detection performance over previous method that requires fusing phone-level detection results. Using articulatory posterior features to derive i-vectors from multiple-word utterances achieves an unweighted average recall of 78.2% and a macro F1 score of 78.0%.
Detection of Consonant Errors in Disordered Speech Based on Consonant-vowel Segment Embedding
Jun 16, 2021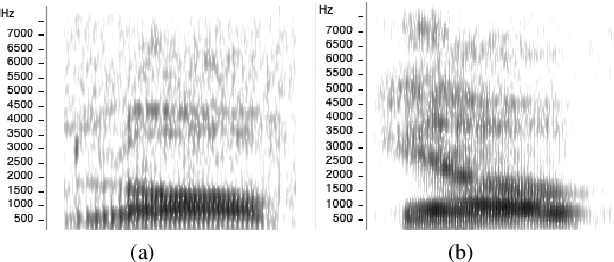
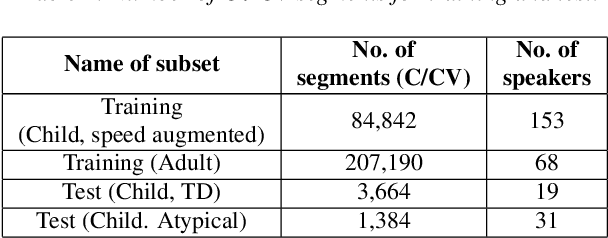

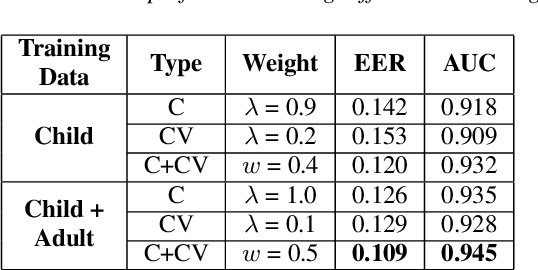
Speech sound disorder (SSD) refers to a type of developmental disorder in young children who encounter persistent difficulties in producing certain speech sounds at the expected age. Consonant errors are the major indicator of SSD in clinical assessment. Previous studies on automatic assessment of SSD revealed that detection of speech errors concerning short and transitory consonants is less satisfactory. This paper investigates a neural network based approach to detecting consonant errors in disordered speech using consonant-vowel (CV) diphone segment in comparison to using consonant monophone segment. The underlying assumption is that the vowel part of a CV segment carries important information of co-articulation from the consonant. Speech embeddings are extracted from CV segments by a recurrent neural network model. The similarity scores between the embeddings of the test segment and the reference segments are computed to determine if the test segment is the expected consonant or not. Experimental results show that using CV segments achieves improved performance on detecting speech errors concerning those "difficult" consonants reported in the previous studies.