 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Text-Independent Speaker Verification with Auxiliary Speakers Using Graph
Paper and Code
Sep 20, 2021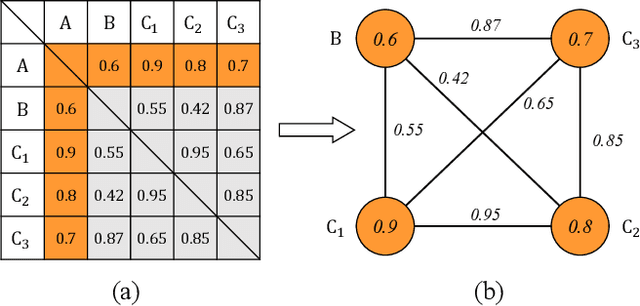
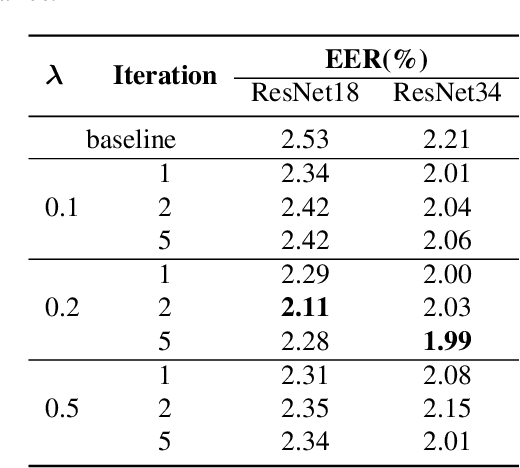

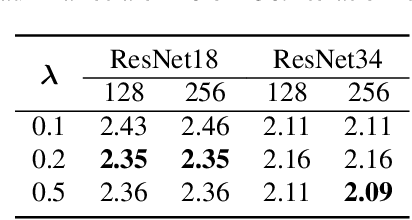
The paper presents a novel approach to refining similarity scores between input utterances for robust speaker verification. Given the embeddings from a pair of input utterances, a graph model is designed to incorporate additional information from a group of embeddings representing the so-called auxiliary speakers. The relations between the input utterances and the auxiliary speakers are represented by the edges and vertices in the graph. The similarity scores are refined by iteratively updating the values of the graph's vertices using an algorithm similar to the random walk algorithm on graphs. Through this updating process, the information of auxiliary speakers is involved in determining the relation between input utterances and hence contributing to the verification process. We propose to create a set of artificial embeddings through the model training process. Utilizing the generated embeddings as auxiliary speakers, no extra data are required for the graph model in the verification stage. The proposed model is trained in an end-to-end manner within the whole system. Experiments are carried out with the Voxceleb datasets. The results indicate that involving auxiliary speakers with graph is effective to improve speaker verification performance.