 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTidyVoice 2026 Challenge Evaluation Plan
Jan 29, 2026The performance of speaker verification systems degrades significantly under language mismatch, a critical challenge exacerbated by the field's reliance on English-centric data. To address this, we propose the TidyVoice Challenge for cross-lingual speaker verification. The challenge leverages the TidyVoiceX dataset from the novel TidyVoice benchmark, a large-scale, multilingual corpus derived from Mozilla Common Voice, and specifically curated to isolate the effect of language switching across approximately 40 languages. Participants will be tasked with building systems robust to this mismatch, with performance primarily evaluated using the Equal Error Rate on cross-language trials. By providing standardized data, open-source baselines, and a rigorous evaluation protocol, this challenge aims to drive research towards fairer, more inclusive, and language-independent speaker recognition technologies, directly aligning with the Interspeech 2026 theme, "Speaking Together."
Defining bias in AI-systems: Biased models are fair models
Feb 25, 2025The debate around bias in AI systems is central to discussions on algorithmic fairness. However, the term bias often lacks a clear definition, despite frequently being contrasted with fairness, implying that an unbiased model is inherently fair. In this paper, we challenge this assumption and argue that a precise conceptualization of bias is necessary to effectively address fairness concerns. Rather than viewing bias as inherently negative or unfair, we highlight the importance of distinguishing between bias and discrimination. We further explore how this shift in focus can foster a more constructive discourse within academic debates on fairness in AI systems.
A Tutorial on Clinical Speech AI Development: From Data Collection to Model Validation
Oct 29, 2024There has been a surge of interest in leveraging speech as a marker of health for a wide spectrum of conditions. The underlying premise is that any neurological, mental, or physical deficits that impact speech production can be objectively assessed via automated analysis of speech. Recent advances in speech-based Artificial Intelligence (AI) models for diagnosing and tracking mental health, cognitive, and motor disorders often use supervised learning, similar to mainstream speech technologies like recognition and verification. However, clinical speech AI has distinct challenges, including the need for specific elicitation tasks, small available datasets, diverse speech representations, and uncertain diagnostic labels. As a result, application of the standard supervised learning paradigm may lead to models that perform well in controlled settings but fail to generalize in real-world clinical deployments. With translation into real-world clinical scenarios in mind, this tutorial paper provides an overview of the key components required for robust development of clinical speech AI. Specifically, this paper will cover the design of speech elicitation tasks and protocols most appropriate for different clinical conditions, collection of data and verification of hardware, development and validation of speech representations designed to measure clinical constructs of interest, development of reliable and robust clinical prediction models, and ethical and participant considerations for clinical speech AI. The goal is to provide comprehensive guidance on building models whose inputs and outputs link to the more interpretable and clinically meaningful aspects of speech, that can be interrogated and clinically validated on clinical datasets, and that adhere to ethical, privacy, and security considerations by design.
Anonymising Elderly and Pathological Speech: Voice Conversion Using DDSP and Query-by-Example
Oct 20, 2024



Speech anonymisation aims to protect speaker identity by changing personal identifiers in speech while retaining linguistic content. Current methods fail to retain prosody and unique speech patterns found in elderly and pathological speech domains, which is essential for remote health monitoring. To address this gap, we propose a voice conversion-based method (DDSP-QbE) using differentiable digital signal processing and query-by-example. The proposed method, trained with novel losses, aids in disentangling linguistic, prosodic, and domain representations, enabling the model to adapt to uncommon speech patterns. Objective and subjective evaluations show that DDSP-QbE significantly outperforms the voice conversion state-of-the-art concerning intelligibility, prosody, and domain preservation across diverse datasets, pathologies, and speakers while maintaining quality and speaker anonymity. Experts validate domain preservation by analysing twelve clinically pertinent domain attributes.
Improving Voice Conversion for Dissimilar Speakers Using Perceptual Losses
Sep 18, 2023The rising trend of using voice as a means of interacting with smart devices has sparked worries over the protection of users' privacy and data security. These concerns have become more pressing, especially after the European Union's adoption of the General Data Protection Regulation (GDPR). The information contained in an utterance encompasses critical personal details about the speaker, such as their age, gender, socio-cultural origins and more. If there is a security breach and the data is compromised, attackers may utilise the speech data to circumvent the speaker verification systems or imitate authorised users. Therefore, it is pertinent to anonymise the speech data before being shared across devices, such that the source speaker of the utterance cannot be traced. Voice conversion (VC) can be used to achieve speech anonymisation, which involves altering the speaker's characteristics while preserving the linguistic content.
Emo-StarGAN: A Semi-Supervised Any-to-Many Non-Parallel Emotion-Preserving Voice Conversion
Sep 14, 2023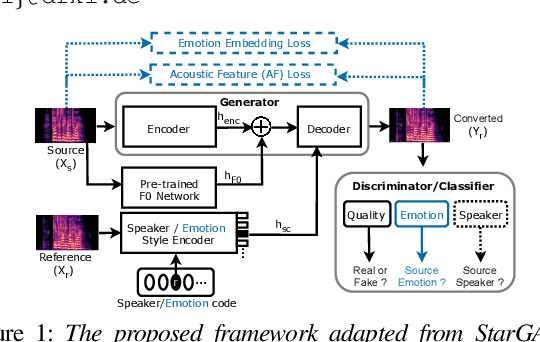
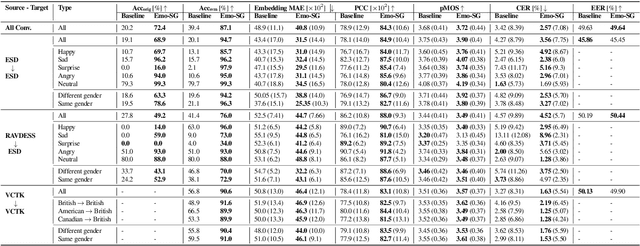
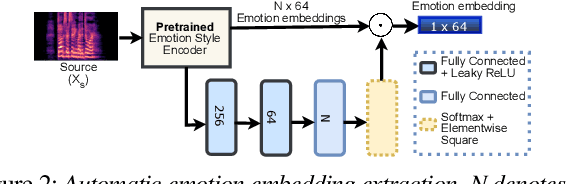
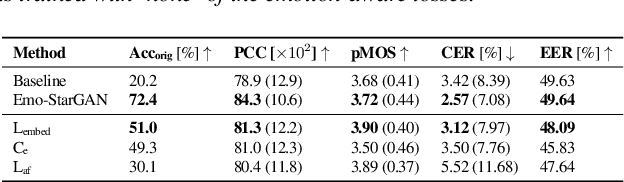
Speech anonymisation prevents misuse of spoken data by removing any personal identifier while preserving at least linguistic content. However, emotion preservation is crucial for natural human-computer interaction. The well-known voice conversion technique StarGANv2-VC achieves anonymisation but fails to preserve emotion. This work presents an any-to-many semi-supervised StarGANv2-VC variant trained on partially emotion-labelled non-parallel data. We propose emotion-aware losses computed on the emotion embeddings and acoustic features correlated to emotion. Additionally, we use an emotion classifier to provide direct emotion supervision. Objective and subjective evaluations show that the proposed approach significantly improves emotion preservation over the vanilla StarGANv2-VC. This considerable improvement is seen over diverse datasets, emotions, target speakers, and inter-group conversions without compromising intelligibility and anonymisation.