 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaccadic Vision for Fine-Grained Visual Classification
Sep 19, 2025Fine-grained visual classification (FGVC) requires distinguishing between visually similar categories through subtle, localized features - a task that remains challenging due to high intra-class variability and limited inter-class differences. Existing part-based methods often rely on complex localization networks that learn mappings from pixel to sample space, requiring a deep understanding of image content while limiting feature utility for downstream tasks. In addition, sampled points frequently suffer from high spatial redundancy, making it difficult to quantify the optimal number of required parts. Inspired by human saccadic vision, we propose a two-stage process that first extracts peripheral features (coarse view) and generates a sample map, from which fixation patches are sampled and encoded in parallel using a weight-shared encoder. We employ contextualized selective attention to weigh the impact of each fixation patch before fusing peripheral and focus representations. To prevent spatial collapse - a common issue in part-based methods - we utilize non-maximum suppression during fixation sampling to eliminate redundancy. Comprehensive evaluation on standard FGVC benchmarks (CUB-200-2011, NABirds, Food-101 and Stanford-Dogs) and challenging insect datasets (EU-Moths, Ecuador-Moths and AMI-Moths) demonstrates that our method achieves comparable performance to state-of-the-art approaches while consistently outperforming our baseline encoder.
From Lines to Shapes: Geometric-Constrained Segmentation of X-Ray Collimators via Hough Transform
Sep 04, 2025Collimation in X-ray imaging restricts exposure to the region-of-interest (ROI) and minimizes the radiation dose applied to the patient. The detection of collimator shadows is an essential image-based preprocessing step in digital radiography posing a challenge when edges get obscured by scattered X-ray radiation. Regardless, the prior knowledge that collimation forms polygonal-shaped shadows is evident. For this reason, we introduce a deep learning-based segmentation that is inherently constrained to its geometry. We achieve this by incorporating a differentiable Hough transform-based network to detect the collimation borders and enhance its capability to extract the information about the ROI center. During inference, we combine the information of both tasks to enable the generation of refined, line-constrained segmentation masks. We demonstrate robust reconstruction of collimated regions achieving median Hausdorff distances of 4.3-5.0mm on diverse test sets of real Xray images. While this application involves at most four shadow borders, our method is not fundamentally limited by a specific number of edges.
Generative AI Training and Copyright Law
Feb 21, 2025Training generative AI models requires extensive amounts of data. A common practice is to collect such data through web scraping. Yet, much of what has been and is collected is copyright protected. Its use may be copyright infringement. In the USA, AI developers rely on "fair use" and in Europe, the prevailing view is that the exception for "Text and Data Mining" (TDM) applies. In a recent interdisciplinary tandem-study, we have argued in detail that this is actually not the case because generative AI training fundamentally differs from TDM. In this article, we share our main findings and the implications for both public and corporate research on generative models. We further discuss how the phenomenon of training data memorization leads to copyright issues independently from the "fair use" and TDM exceptions. Finally, we outline how the ISMIR could contribute to the ongoing discussion about fair practices with respect to generative AI that satisfy all stakeholders.
TransferLight: Zero-Shot Traffic Signal Control on any Road-Network
Dec 12, 2024
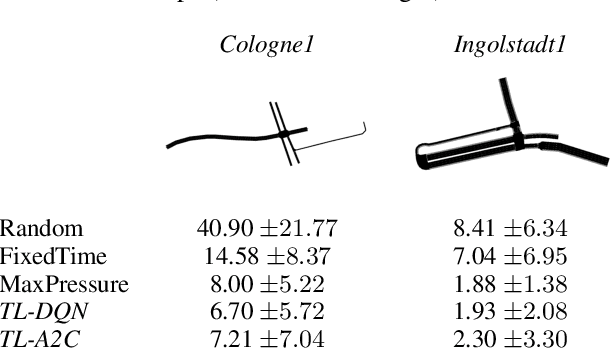

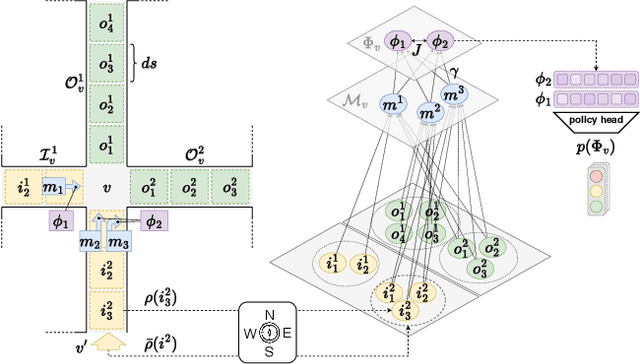
Traffic signal control plays a crucial role in urban mobility. However, existing methods often struggle to generalize beyond their training environments to unseen scenarios with varying traffic dynamics. We present TransferLight, a novel framework designed for robust generalization across road-networks, diverse traffic conditions and intersection geometries. At its core, we propose a log-distance reward function, offering spatially-aware signal prioritization while remaining adaptable to varied lane configurations - overcoming the limitations of traditional pressure-based rewards. Our hierarchical, heterogeneous, and directed graph neural network architecture effectively captures granular traffic dynamics, enabling transferability to arbitrary intersection layouts. Using a decentralized multi-agent approach, global rewards, and novel state transition priors, we develop a single, weight-tied policy that scales zero-shot to any road network without re-training. Through domain randomization during training, we additionally enhance generalization capabilities. Experimental results validate TransferLight's superior performance in unseen scenarios, advancing practical, generalizable intelligent transportation systems to meet evolving urban traffic demands.
An Interpretable X-ray Style Transfer via Trainable Local Laplacian Filter
Nov 11, 2024



Radiologists have preferred visual impressions or 'styles' of X-ray images that are manually adjusted to their needs to support their diagnostic performance. In this work, we propose an automatic and interpretable X-ray style transfer by introducing a trainable version of the Local Laplacian Filter (LLF). From the shape of the LLF's optimized remap function, the characteristics of the style transfer can be inferred and reliability of the algorithm can be ensured. Moreover, we enable the LLF to capture complex X-ray style features by replacing the remap function with a Multi-Layer Perceptron (MLP) and adding a trainable normalization layer. We demonstrate the effectiveness of the proposed method by transforming unprocessed mammographic X-ray images into images that match the style of target mammograms and achieve a Structural Similarity Index (SSIM) of 0.94 compared to 0.82 of the baseline LLF style transfer method from Aubry et al.
Anonymising Elderly and Pathological Speech: Voice Conversion Using DDSP and Query-by-Example
Oct 20, 2024



Speech anonymisation aims to protect speaker identity by changing personal identifiers in speech while retaining linguistic content. Current methods fail to retain prosody and unique speech patterns found in elderly and pathological speech domains, which is essential for remote health monitoring. To address this gap, we propose a voice conversion-based method (DDSP-QbE) using differentiable digital signal processing and query-by-example. The proposed method, trained with novel losses, aids in disentangling linguistic, prosodic, and domain representations, enabling the model to adapt to uncommon speech patterns. Objective and subjective evaluations show that DDSP-QbE significantly outperforms the voice conversion state-of-the-art concerning intelligibility, prosody, and domain preservation across diverse datasets, pathologies, and speakers while maintaining quality and speaker anonymity. Experts validate domain preservation by analysing twelve clinically pertinent domain attributes.
Improving Voice Quality in Speech Anonymization With Just Perception-Informed Losses
Oct 20, 2024


The increasing use of cloud-based speech assistants has heightened the need for effective speech anonymization, which aims to obscure a speaker's identity while retaining critical information for subsequent tasks. One approach to achieving this is through voice conversion. While existing methods often emphasize complex architectures and training techniques, our research underscores the importance of loss functions inspired by the human auditory system. Our proposed loss functions are model-agnostic, incorporating handcrafted and deep learning-based features to effectively capture quality representations. Through objective and subjective evaluations, we demonstrate that a VQVAE-based model, enhanced with our perception-driven losses, surpasses the vanilla model in terms of naturalness, intelligibility, and prosody while maintaining speaker anonymity. These improvements are consistently observed across various datasets, languages, target speakers, and genders.
StyleX: A Trainable Metric for X-ray Style Distances
May 23, 2024The progression of X-ray technology introduces diverse image styles that need to be adapted to the preferences of radiologists. To support this task, we introduce a novel deep learning-based metric that quantifies style differences of non-matching image pairs. At the heart of our metric is an encoder capable of generating X-ray image style representations. This encoder is trained without any explicit knowledge of style distances by exploiting Simple Siamese learning. During inference, the style representations produced by the encoder are used to calculate a distance metric for non-matching image pairs. Our experiments investigate the proposed concept for a disclosed reproducible and a proprietary image processing pipeline along two dimensions: First, we use a t-distributed stochastic neighbor embedding (t-SNE) analysis to illustrate that the encoder outputs provide meaningful and discriminative style representations. Second, the proposed metric calculated from the encoder outputs is shown to quantify style distances for non-matching pairs in good alignment with the human perception. These results confirm that our proposed method is a promising technique to quantify style differences, which can be used for guided style selection as well as automatic optimization of image pipeline parameters.
Tilt your Head: Activating the Hidden Spatial-Invariance of Classifiers
May 06, 2024



Deep neural networks are applied in more and more areas of everyday life. However, they still lack essential abilities, such as robustly dealing with spatially transformed input signals. Approaches to mitigate this severe robustness issue are limited to two pathways: Either models are implicitly regularised by increased sample variability (data augmentation) or explicitly constrained by hard-coded inductive biases. The limiting factor of the former is the size of the data space, which renders sufficient sample coverage intractable. The latter is limited by the engineering effort required to develop such inductive biases for every possible scenario. Instead, we take inspiration from human behaviour, where percepts are modified by mental or physical actions during inference. We propose a novel technique to emulate such an inference process for neural nets. This is achieved by traversing a sparsified inverse transformation tree during inference using parallel energy-based evaluations. Our proposed inference algorithm, called Inverse Transformation Search (ITS), is model-agnostic and equips the model with zero-shot pseudo-invariance to spatially transformed inputs. We evaluated our method on several benchmark datasets, including a synthesised ImageNet test set. ITS outperforms the utilised baselines on all zero-shot test scenarios.
PI-RADS v2 Compliant Automated Segmentation of Prostate Zones Using co-training Motivated Multi-task Dual-Path CNN
Sep 22, 2023



The detailed images produced by Magnetic Resonance Imaging (MRI) provide life-critical information for the diagnosis and treatment of prostate cancer. To provide standardized acquisition, interpretation and usage of the complex MRI images, the PI-RADS v2 guideline was proposed. An automated segmentation following the guideline facilitates consistent and precise lesion detection, staging and treatment. The guideline recommends a division of the prostate into four zones, PZ (peripheral zone), TZ (transition zone), DPU (distal prostatic urethra) and AFS (anterior fibromuscular stroma). Not every zone shares a boundary with the others and is present in every slice. Further, the representations captured by a single model might not suffice for all zones. This motivated us to design a dual-branch convolutional neural network (CNN), where each branch captures the representations of the connected zones separately. Further, the representations from different branches act complementary to each other at the second stage of training, where they are fine-tuned through an unsupervised loss. The loss penalises the difference in predictions from the two branches for the same class. We also incorporate multi-task learning in our framework to further improve the segmentation accuracy. The proposed approach improves the segmentation accuracy of the baseline (mean absolute symmetric distance) by 7.56%, 11.00%, 58.43% and 19.67% for PZ, TZ, DPU and AFS zones respectively.