 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferLight: Zero-Shot Traffic Signal Control on any Road-Network
Dec 12, 2024
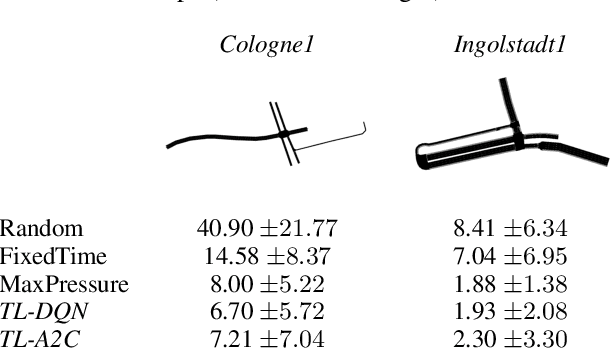

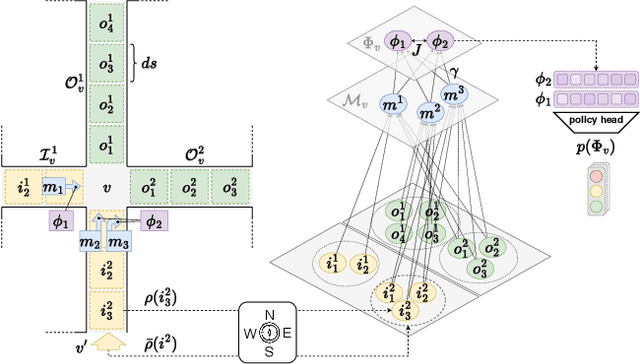
Traffic signal control plays a crucial role in urban mobility. However, existing methods often struggle to generalize beyond their training environments to unseen scenarios with varying traffic dynamics. We present TransferLight, a novel framework designed for robust generalization across road-networks, diverse traffic conditions and intersection geometries. At its core, we propose a log-distance reward function, offering spatially-aware signal prioritization while remaining adaptable to varied lane configurations - overcoming the limitations of traditional pressure-based rewards. Our hierarchical, heterogeneous, and directed graph neural network architecture effectively captures granular traffic dynamics, enabling transferability to arbitrary intersection layouts. Using a decentralized multi-agent approach, global rewards, and novel state transition priors, we develop a single, weight-tied policy that scales zero-shot to any road network without re-training. Through domain randomization during training, we additionally enhance generalization capabilities. Experimental results validate TransferLight's superior performance in unseen scenarios, advancing practical, generalizable intelligent transportation systems to meet evolving urban traffic demands.
Improving Voice Quality in Speech Anonymization With Just Perception-Informed Losses
Oct 20, 2024


The increasing use of cloud-based speech assistants has heightened the need for effective speech anonymization, which aims to obscure a speaker's identity while retaining critical information for subsequent tasks. One approach to achieving this is through voice conversion. While existing methods often emphasize complex architectures and training techniques, our research underscores the importance of loss functions inspired by the human auditory system. Our proposed loss functions are model-agnostic, incorporating handcrafted and deep learning-based features to effectively capture quality representations. Through objective and subjective evaluations, we demonstrate that a VQVAE-based model, enhanced with our perception-driven losses, surpasses the vanilla model in terms of naturalness, intelligibility, and prosody while maintaining speaker anonymity. These improvements are consistently observed across various datasets, languages, target speakers, and genders.