 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaccadic Vision for Fine-Grained Visual Classification
Sep 19, 2025Fine-grained visual classification (FGVC) requires distinguishing between visually similar categories through subtle, localized features - a task that remains challenging due to high intra-class variability and limited inter-class differences. Existing part-based methods often rely on complex localization networks that learn mappings from pixel to sample space, requiring a deep understanding of image content while limiting feature utility for downstream tasks. In addition, sampled points frequently suffer from high spatial redundancy, making it difficult to quantify the optimal number of required parts. Inspired by human saccadic vision, we propose a two-stage process that first extracts peripheral features (coarse view) and generates a sample map, from which fixation patches are sampled and encoded in parallel using a weight-shared encoder. We employ contextualized selective attention to weigh the impact of each fixation patch before fusing peripheral and focus representations. To prevent spatial collapse - a common issue in part-based methods - we utilize non-maximum suppression during fixation sampling to eliminate redundancy. Comprehensive evaluation on standard FGVC benchmarks (CUB-200-2011, NABirds, Food-101 and Stanford-Dogs) and challenging insect datasets (EU-Moths, Ecuador-Moths and AMI-Moths) demonstrates that our method achieves comparable performance to state-of-the-art approaches while consistently outperforming our baseline encoder.
TransferLight: Zero-Shot Traffic Signal Control on any Road-Network
Dec 12, 2024
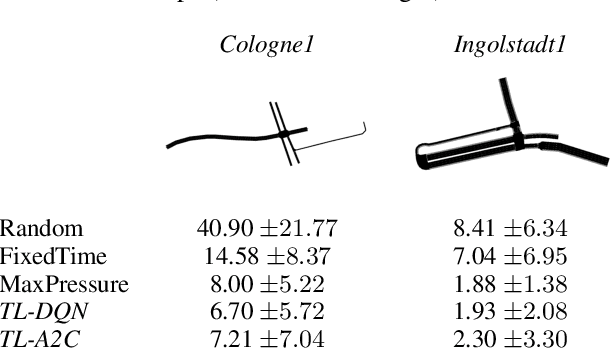

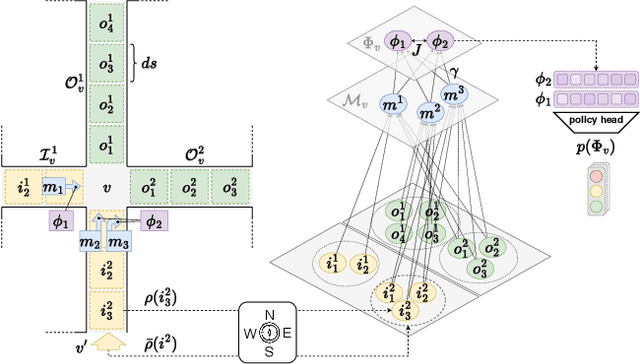
Traffic signal control plays a crucial role in urban mobility. However, existing methods often struggle to generalize beyond their training environments to unseen scenarios with varying traffic dynamics. We present TransferLight, a novel framework designed for robust generalization across road-networks, diverse traffic conditions and intersection geometries. At its core, we propose a log-distance reward function, offering spatially-aware signal prioritization while remaining adaptable to varied lane configurations - overcoming the limitations of traditional pressure-based rewards. Our hierarchical, heterogeneous, and directed graph neural network architecture effectively captures granular traffic dynamics, enabling transferability to arbitrary intersection layouts. Using a decentralized multi-agent approach, global rewards, and novel state transition priors, we develop a single, weight-tied policy that scales zero-shot to any road network without re-training. Through domain randomization during training, we additionally enhance generalization capabilities. Experimental results validate TransferLight's superior performance in unseen scenarios, advancing practical, generalizable intelligent transportation systems to meet evolving urban traffic demands.
Tilt your Head: Activating the Hidden Spatial-Invariance of Classifiers
May 06, 2024



Deep neural networks are applied in more and more areas of everyday life. However, they still lack essential abilities, such as robustly dealing with spatially transformed input signals. Approaches to mitigate this severe robustness issue are limited to two pathways: Either models are implicitly regularised by increased sample variability (data augmentation) or explicitly constrained by hard-coded inductive biases. The limiting factor of the former is the size of the data space, which renders sufficient sample coverage intractable. The latter is limited by the engineering effort required to develop such inductive biases for every possible scenario. Instead, we take inspiration from human behaviour, where percepts are modified by mental or physical actions during inference. We propose a novel technique to emulate such an inference process for neural nets. This is achieved by traversing a sparsified inverse transformation tree during inference using parallel energy-based evaluations. Our proposed inference algorithm, called Inverse Transformation Search (ITS), is model-agnostic and equips the model with zero-shot pseudo-invariance to spatially transformed inputs. We evaluated our method on several benchmark datasets, including a synthesised ImageNet test set. ITS outperforms the utilised baselines on all zero-shot test scenarios.
Learning Continuous Rotation Canonicalization with Radial Beam Sampling
Jun 21, 2022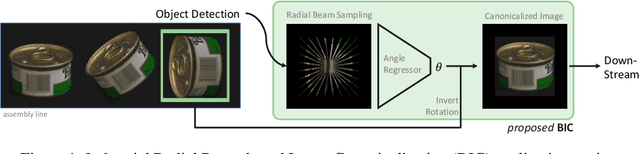

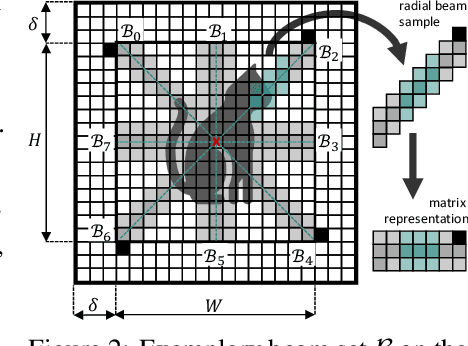

Nearly all state of the art vision models are sensitive to image rotations. Existing methods often compensate for missing inductive biases by using augmented training data to learn pseudo-invariances. Alongside the resource demanding data inflation process, predictions often poorly generalize. The inductive biases inherent to convolutional neural networks allow for translation equivariance through kernels acting parallely to the horizontal and vertical axes of the pixel grid. This inductive bias, however, does not allow for rotation equivariance. We propose a radial beam sampling strategy along with radial kernels operating on these beams to inherently incorporate center-rotation covariance. Together with an angle distance loss, we present a radial beam-based image canonicalization model, short BIC. Our model allows for maximal continuous angle regression and canonicalizes arbitrary center-rotated input images. As a pre-processing model, this enables rotation-invariant vision pipelines with model-agnostic rotation-sensitive downstream predictions. We show that our end-to-end trained angle regressor is able to predict continuous rotation angles on several vision datasets, i.e. FashionMNIST, CIFAR10, COIL100, and LFW.