 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnonymising Elderly and Pathological Speech: Voice Conversion Using DDSP and Query-by-Example
Oct 20, 2024



Speech anonymisation aims to protect speaker identity by changing personal identifiers in speech while retaining linguistic content. Current methods fail to retain prosody and unique speech patterns found in elderly and pathological speech domains, which is essential for remote health monitoring. To address this gap, we propose a voice conversion-based method (DDSP-QbE) using differentiable digital signal processing and query-by-example. The proposed method, trained with novel losses, aids in disentangling linguistic, prosodic, and domain representations, enabling the model to adapt to uncommon speech patterns. Objective and subjective evaluations show that DDSP-QbE significantly outperforms the voice conversion state-of-the-art concerning intelligibility, prosody, and domain preservation across diverse datasets, pathologies, and speakers while maintaining quality and speaker anonymity. Experts validate domain preservation by analysing twelve clinically pertinent domain attributes.
Improving Voice Conversion for Dissimilar Speakers Using Perceptual Losses
Sep 18, 2023The rising trend of using voice as a means of interacting with smart devices has sparked worries over the protection of users' privacy and data security. These concerns have become more pressing, especially after the European Union's adoption of the General Data Protection Regulation (GDPR). The information contained in an utterance encompasses critical personal details about the speaker, such as their age, gender, socio-cultural origins and more. If there is a security breach and the data is compromised, attackers may utilise the speech data to circumvent the speaker verification systems or imitate authorised users. Therefore, it is pertinent to anonymise the speech data before being shared across devices, such that the source speaker of the utterance cannot be traced. Voice conversion (VC) can be used to achieve speech anonymisation, which involves altering the speaker's characteristics while preserving the linguistic content.
Emo-StarGAN: A Semi-Supervised Any-to-Many Non-Parallel Emotion-Preserving Voice Conversion
Sep 14, 2023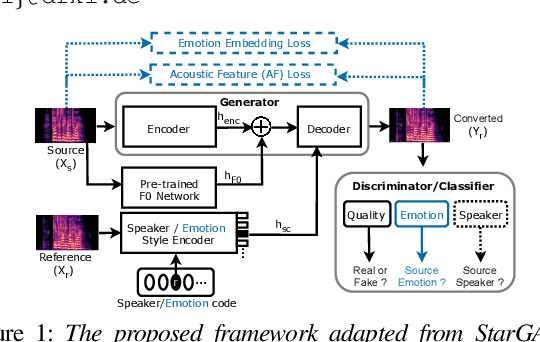
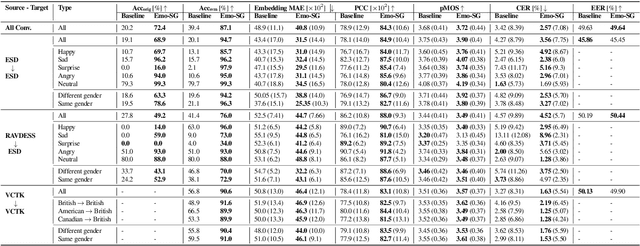
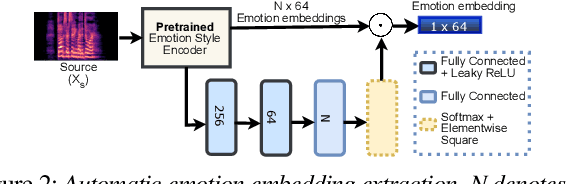
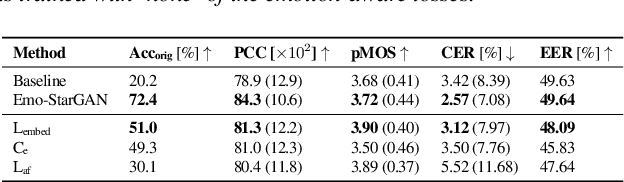
Speech anonymisation prevents misuse of spoken data by removing any personal identifier while preserving at least linguistic content. However, emotion preservation is crucial for natural human-computer interaction. The well-known voice conversion technique StarGANv2-VC achieves anonymisation but fails to preserve emotion. This work presents an any-to-many semi-supervised StarGANv2-VC variant trained on partially emotion-labelled non-parallel data. We propose emotion-aware losses computed on the emotion embeddings and acoustic features correlated to emotion. Additionally, we use an emotion classifier to provide direct emotion supervision. Objective and subjective evaluations show that the proposed approach significantly improves emotion preservation over the vanilla StarGANv2-VC. This considerable improvement is seen over diverse datasets, emotions, target speakers, and inter-group conversions without compromising intelligibility and anonymisation.