 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFKI-Speech System for WildSpoof Challenge: A robust framework for SASV In-the-Wild
Feb 02, 2026This paper presents the DFKI-Speech system developed for the WildSpoof Challenge under the Spoofing aware Automatic Speaker Verification (SASV) track. We propose a robust SASV framework in which a spoofing detector and a speaker verification (SV) network operate in tandem. The spoofing detector employs a self-supervised speech embedding extractor as the frontend, combined with a state-of-the-art graph neural network backend. In addition, a top-3 layer based mixture-of-experts (MoE) is used to fuse high-level and low-level features for effective spoofed utterance detection. For speaker verification, we adapt a low-complexity convolutional neural network that fuses 2D and 1D features at multiple scales, trained with the SphereFace loss. Additionally, contrastive circle loss is applied to adaptively weight positive and negative pairs within each training batch, enabling the network to better distinguish between hard and easy sample pairs. Finally, fixed imposter cohort based AS Norm score normalization and model ensembling are used to further enhance the discriminative capability of the speaker verification system.
Content Leakage in LibriSpeech and Its Impact on the Privacy Evaluation of Speaker Anonymization
Jan 19, 2026Speaker anonymization aims to conceal a speaker's identity, without considering the linguistic content. In this study, we reveal a weakness of Librispeech, the dataset that is commonly used to evaluate anonymizers: the books read by the Librispeech speakers are so distinct, that speakers can be identified by their vocabularies. Even perfect anonymizers cannot prevent this identity leakage. The EdAcc dataset is better in this regard: only a few speakers can be identified through their vocabularies, encouraging the attacker to look elsewhere for the identities of the anonymized speakers. EdAcc also comprises spontaneous speech and more diverse speakers, complementing Librispeech and giving more insights into how anonymizers work.
Two Views, One Truth: Spectral and Self-Supervised Features Fusion for Robust Speech Deepfake Detection
Jul 27, 2025Recent advances in synthetic speech have made audio deepfakes increasingly realistic, posing significant security risks. Existing detection methods that rely on a single modality, either raw waveform embeddings or spectral based features, are vulnerable to non spoof disturbances and often overfit to known forgery algorithms, resulting in poor generalization to unseen attacks. To address these shortcomings, we investigate hybrid fusion frameworks that integrate self supervised learning (SSL) based representations with handcrafted spectral descriptors (MFCC , LFCC, CQCC). By aligning and combining complementary information across modalities, these fusion approaches capture subtle artifacts that single feature approaches typically overlook. We explore several fusion strategies, including simple concatenation, cross attention, mutual cross attention, and a learnable gating mechanism, to optimally blend SSL features with fine grained spectral cues. We evaluate our approach on four challenging public benchmarks and report generalization performance. All fusion variants consistently outperform an SSL only baseline, with the cross attention strategy achieving the best generalization with a 38% relative reduction in equal error rate (EER). These results confirm that joint modeling of waveform and spectral views produces robust, domain agnostic representations for audio deepfake detection.
Machine Learning-Based Anomaly Detection of Correlated Sensor Data: An Integrated Principal Component Analysis-Autoencoder Approach
May 29, 2025The growing adoption of IoT systems in industries like transportation, banking, healthcare, and smart energy has increased reliance on sensor networks. However, anomalies in sensor readings can undermine system reliability, making real-time anomaly detection essential. While a large body of research addresses anomaly detection in IoT networks, few studies focus on correlated sensor data streams, such as temperature and pressure within a shared space, especially in resource-constrained environments. To address this, we propose a novel hybrid machine learning approach combining Principal Component Analysis (PCA) and Autoencoders. In this method, PCA continuously monitors sensor data and triggers the Autoencoder when significant variations are detected. This hybrid approach, validated with real-world and simulated data, shows faster response times and fewer false positives. The F1 score of the hybrid method is comparable to Autoencoder, with much faster response time which is driven by PCA.
Private kNN-VC: Interpretable Anonymization of Converted Speech
May 23, 2025Speaker anonymization seeks to conceal a speaker's identity while preserving the utility of their speech. The achieved privacy is commonly evaluated with a speaker recognition model trained on anonymized speech. Although this represents a strong attack, it is unclear which aspects of speech are exploited to identify the speakers. Our research sets out to unveil these aspects. It starts with kNN-VC, a powerful voice conversion model that performs poorly as an anonymization system, presumably because of prosody leakage. To test this hypothesis, we extend kNN-VC with two interpretable components that anonymize the duration and variation of phones. These components increase privacy significantly, proving that the studied prosodic factors encode speaker identity and are exploited by the privacy attack. Additionally, we show that changes in the target selection algorithm considerably influence the outcome of the privacy attack.
Anonymising Elderly and Pathological Speech: Voice Conversion Using DDSP and Query-by-Example
Oct 20, 2024



Speech anonymisation aims to protect speaker identity by changing personal identifiers in speech while retaining linguistic content. Current methods fail to retain prosody and unique speech patterns found in elderly and pathological speech domains, which is essential for remote health monitoring. To address this gap, we propose a voice conversion-based method (DDSP-QbE) using differentiable digital signal processing and query-by-example. The proposed method, trained with novel losses, aids in disentangling linguistic, prosodic, and domain representations, enabling the model to adapt to uncommon speech patterns. Objective and subjective evaluations show that DDSP-QbE significantly outperforms the voice conversion state-of-the-art concerning intelligibility, prosody, and domain preservation across diverse datasets, pathologies, and speakers while maintaining quality and speaker anonymity. Experts validate domain preservation by analysing twelve clinically pertinent domain attributes.
PI-RADS v2 Compliant Automated Segmentation of Prostate Zones Using co-training Motivated Multi-task Dual-Path CNN
Sep 22, 2023



The detailed images produced by Magnetic Resonance Imaging (MRI) provide life-critical information for the diagnosis and treatment of prostate cancer. To provide standardized acquisition, interpretation and usage of the complex MRI images, the PI-RADS v2 guideline was proposed. An automated segmentation following the guideline facilitates consistent and precise lesion detection, staging and treatment. The guideline recommends a division of the prostate into four zones, PZ (peripheral zone), TZ (transition zone), DPU (distal prostatic urethra) and AFS (anterior fibromuscular stroma). Not every zone shares a boundary with the others and is present in every slice. Further, the representations captured by a single model might not suffice for all zones. This motivated us to design a dual-branch convolutional neural network (CNN), where each branch captures the representations of the connected zones separately. Further, the representations from different branches act complementary to each other at the second stage of training, where they are fine-tuned through an unsupervised loss. The loss penalises the difference in predictions from the two branches for the same class. We also incorporate multi-task learning in our framework to further improve the segmentation accuracy. The proposed approach improves the segmentation accuracy of the baseline (mean absolute symmetric distance) by 7.56%, 11.00%, 58.43% and 19.67% for PZ, TZ, DPU and AFS zones respectively.
StarGAN-VC++: Towards Emotion Preserving Voice Conversion Using Deep Embeddings
Sep 14, 2023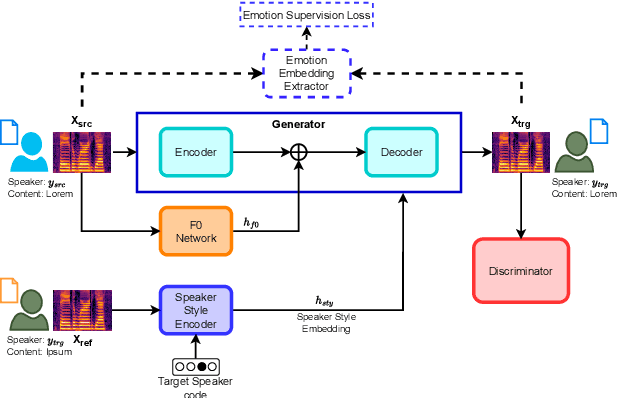

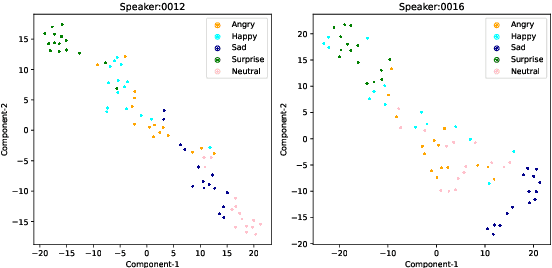
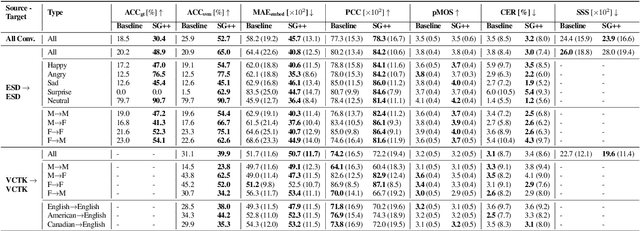
Voice conversion (VC) transforms an utterance to sound like another person without changing the linguistic content. A recently proposed generative adversarial network-based VC method, StarGANv2-VC is very successful in generating natural-sounding conversions. However, the method fails to preserve the emotion of the source speaker in the converted samples. Emotion preservation is necessary for natural human-computer interaction. In this paper, we show that StarGANv2-VC fails to disentangle the speaker and emotion representations, pertinent to preserve emotion. Specifically, there is an emotion leakage from the reference audio used to capture the speaker embeddings while training. To counter the problem, we propose novel emotion-aware losses and an unsupervised method which exploits emotion supervision through latent emotion representations. The objective and subjective evaluations prove the efficacy of the proposed strategy over diverse datasets, emotions, gender, etc.
Emo-StarGAN: A Semi-Supervised Any-to-Many Non-Parallel Emotion-Preserving Voice Conversion
Sep 14, 2023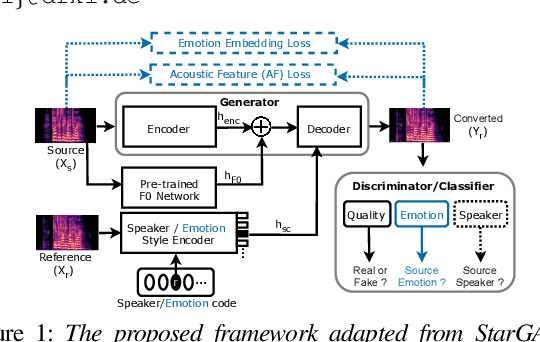
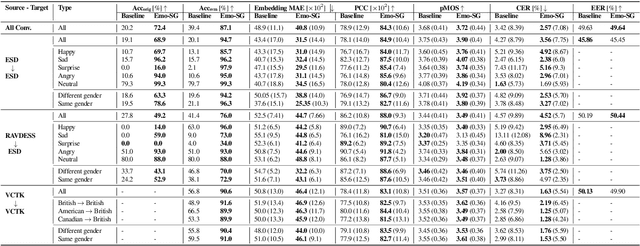
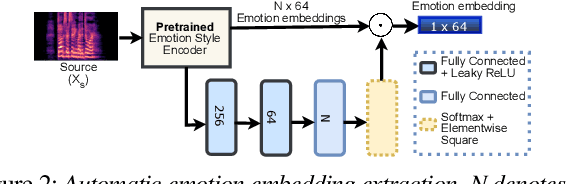
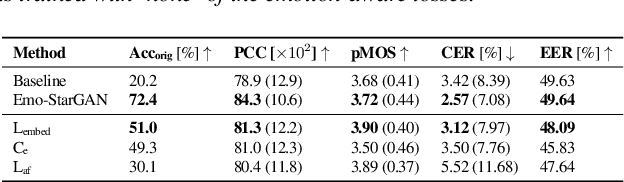
Speech anonymisation prevents misuse of spoken data by removing any personal identifier while preserving at least linguistic content. However, emotion preservation is crucial for natural human-computer interaction. The well-known voice conversion technique StarGANv2-VC achieves anonymisation but fails to preserve emotion. This work presents an any-to-many semi-supervised StarGANv2-VC variant trained on partially emotion-labelled non-parallel data. We propose emotion-aware losses computed on the emotion embeddings and acoustic features correlated to emotion. Additionally, we use an emotion classifier to provide direct emotion supervision. Objective and subjective evaluations show that the proposed approach significantly improves emotion preservation over the vanilla StarGANv2-VC. This considerable improvement is seen over diverse datasets, emotions, target speakers, and inter-group conversions without compromising intelligibility and anonymisation.
TorchEsegeta: Framework for Interpretability and Explainability of Image-based Deep Learning Models
Oct 16, 2021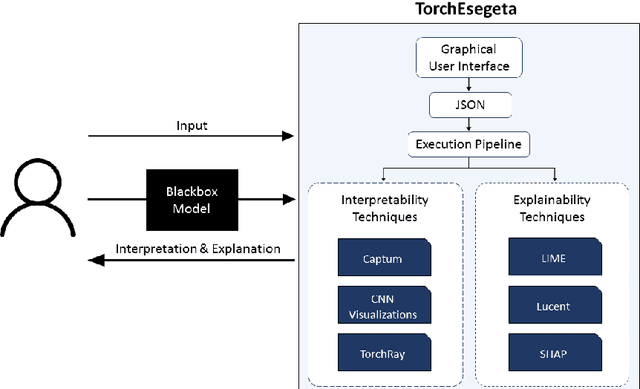
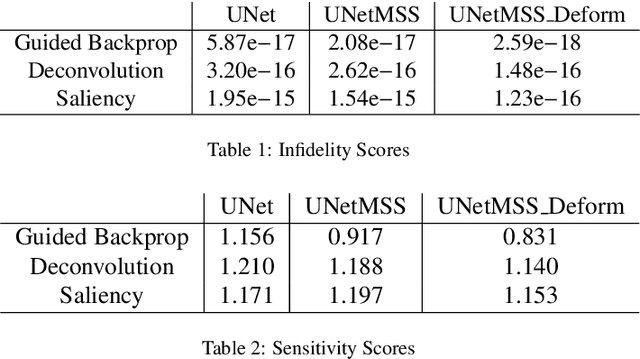
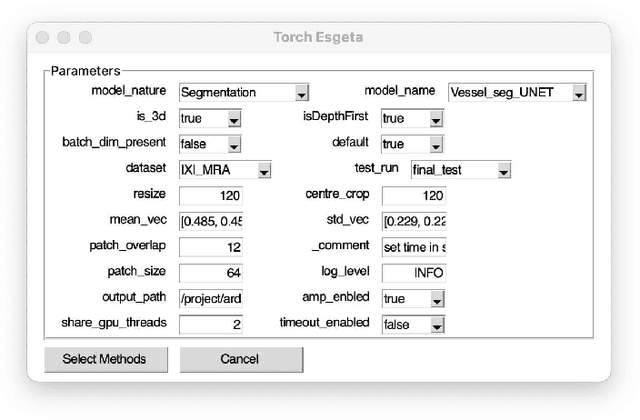
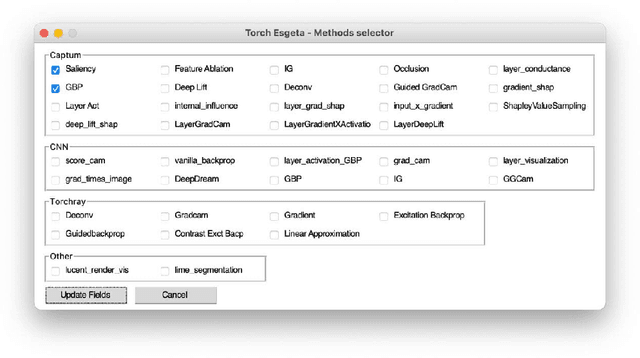
Clinicians are often very sceptical about applying automatic image processing approaches, especially deep learning based methods, in practice. One main reason for this is the black-box nature of these approaches and the inherent problem of missing insights of the automatically derived decisions. In order to increase trust in these methods, this paper presents approaches that help to interpret and explain the results of deep learning algorithms by depicting the anatomical areas which influence the decision of the algorithm most. Moreover, this research presents a unified framework, TorchEsegeta, for applying various interpretability and explainability techniques for deep learning models and generate visual interpretations and explanations for clinicians to corroborate their clinical findings. In addition, this will aid in gaining confidence in such methods. The framework builds on existing interpretability and explainability techniques that are currently focusing on classification models, extending them to segmentation tasks. In addition, these methods have been adapted to 3D models for volumetric analysis. The proposed framework provides methods to quantitatively compare visual explanations using infidelity and sensitivity metrics. This framework can be used by data scientists to perform post-hoc interpretations and explanations of their models, develop more explainable tools and present the findings to clinicians to increase their faith in such models. The proposed framework was evaluated based on a use case scenario of vessel segmentation models trained on Time-of-fight (TOF) Magnetic Resonance Angiogram (MRA) images of the human brain. Quantitative and qualitative results of a comparative study of different models and interpretability methods are presented. Furthermore, this paper provides an extensive overview of several existing interpretability and explainability methods.