 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistically Valid Post-Deployment Monitoring Should Be Standard for AI-Based Digital Health
Jun 06, 2025This position paper argues that post-deployment monitoring in clinical AI is underdeveloped and proposes statistically valid and label-efficient testing frameworks as a principled foundation for ensuring reliability and safety in real-world deployment. A recent review found that only 9% of FDA-registered AI-based healthcare tools include a post-deployment surveillance plan. Existing monitoring approaches are often manual, sporadic, and reactive, making them ill-suited for the dynamic environments in which clinical models operate. We contend that post-deployment monitoring should be grounded in label-efficient and statistically valid testing frameworks, offering a principled alternative to current practices. We use the term "statistically valid" to refer to methods that provide explicit guarantees on error rates (e.g., Type I/II error), enable formal inference under pre-defined assumptions, and support reproducibility--features that align with regulatory requirements. Specifically, we propose that the detection of changes in the data and model performance degradation should be framed as distinct statistical hypothesis testing problems. Grounding monitoring in statistical rigor ensures a reproducible and scientifically sound basis for maintaining the reliability of clinical AI systems. Importantly, it also opens new research directions for the technical community--spanning theory, methods, and tools for statistically principled detection, attribution, and mitigation of post-deployment model failures in real-world settings.
ActionReasoningBench: Reasoning about Actions with and without Ramification Constraints
Jun 06, 2024



Reasoning about actions and change (RAC) has historically driven the development of many early AI challenges, such as the frame problem, and many AI disciplines, including non-monotonic and commonsense reasoning. The role of RAC remains important even now, particularly for tasks involving dynamic environments, interactive scenarios, and commonsense reasoning. Despite the progress of Large Language Models (LLMs) in various AI domains, their performance on RAC is underexplored. To address this gap, we introduce a new benchmark, ActionReasoningBench, encompassing 13 domains and rigorously evaluating LLMs across eight different areas of RAC. These include - Object Tracking, Fluent Tracking, State Tracking, Action Executability, Effects of Actions, Numerical RAC, Hallucination Detection, and Composite Questions. Furthermore, we also investigate the indirect effect of actions due to ramification constraints for every domain. Finally, we evaluate our benchmark using open-sourced and commercial state-of-the-art LLMs, including GPT-4o, Gemini-1.0-Pro, Llama2-7b-chat, Llama2-13b-chat, Llama3-8b-instruct, Gemma-2b-instruct, and Gemma-7b-instruct. Our findings indicate that these models face significant challenges across all categories included in our benchmark.
The Art of Defending: A Systematic Evaluation and Analysis of LLM Defense Strategies on Safety and Over-Defensiveness
Dec 30, 2023



As Large Language Models (LLMs) play an increasingly pivotal role in natural language processing applications, their safety concerns become critical areas of NLP research. This paper presents Safety and Over-Defensiveness Evaluation (SODE) benchmark: a collection of diverse safe and unsafe prompts with carefully designed evaluation methods that facilitate systematic evaluation, comparison, and analysis over 'safety' and 'over-defensiveness.' With SODE, we study a variety of LLM defense strategies over multiple state-of-the-art LLMs, which reveals several interesting and important findings, such as (a) the widely popular 'self-checking' techniques indeed improve the safety against unsafe inputs, but this comes at the cost of extreme over-defensiveness on the safe inputs, (b) providing a safety instruction along with in-context exemplars (of both safe and unsafe inputs) consistently improves safety and also mitigates undue over-defensiveness of the models, (c) providing contextual knowledge easily breaks the safety guardrails and makes the models more vulnerable to generating unsafe responses. Overall, our work reveals numerous such critical findings that we believe will pave the way and facilitate further research in improving the safety of LLMs.
FeelsGoodMan: Inferring Semantics of Twitch Neologisms
Aug 18, 2021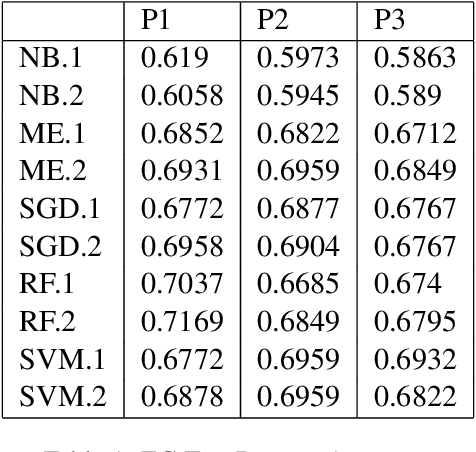
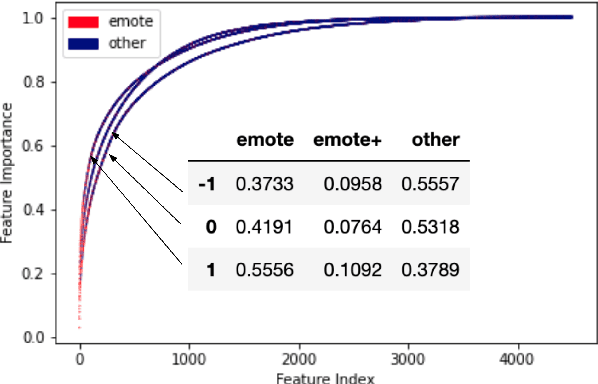
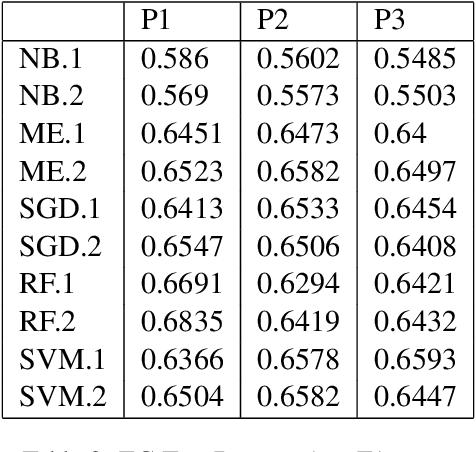
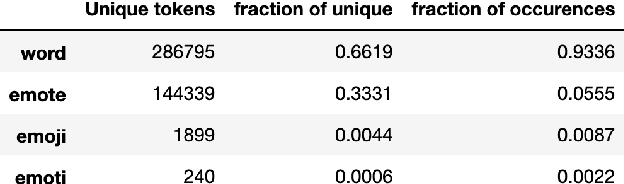
Twitch chats pose a unique problem in natural language understanding due to a large presence of neologisms, specifically emotes. There are a total of 8.06 million emotes, over 400k of which were used in the week studied. There is virtually no information on the meaning or sentiment of emotes, and with a constant influx of new emotes and drift in their frequencies, it becomes impossible to maintain an updated manually-labeled dataset. Our paper makes a two fold contribution. First we establish a new baseline for sentiment analysis on Twitch data, outperforming the previous supervised benchmark by 7.9% points. Secondly, we introduce a simple but powerful unsupervised framework based on word embeddings and k-NN to enrich existing models with out-of-vocabulary knowledge. This framework allows us to auto-generate a pseudo-dictionary of emotes and we show that we can nearly match the supervised benchmark above even when injecting such emote knowledge into sentiment classifiers trained on extraneous datasets such as movie reviews or Twitter.