 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards GUI Agents: Vision-Language Diffusion Models for GUI Grounding
Mar 27, 2026Autoregressive (AR) vision-language models (VLMs) have long dominated multimodal understanding, reasoning, and graphical user interface (GUI) grounding. Recently, discrete diffusion vision-language models (DVLMs) have shown strong performance in multimodal reasoning, offering bidirectional attention, parallel token generation, and iterative refinement. However, their potential for GUI grounding remains unexplored. In this work, we evaluate whether discrete DVLMs can serve as a viable alternative to AR models for GUI grounding. We adapt LLaDA-V for single-turn action and bounding-box prediction, framing the task as text generation from multimodal input. To better capture the hierarchical structure of bounding-box geometry, we propose a hybrid masking schedule that combines linear and deterministic masking, improving grounding accuracy by up to 6.1 points in Step Success Rate (SSR) over the GUI-adapted LLaDA-V trained with linear masking. Evaluations on four datasets spanning web, desktop, and mobile interfaces show that the adapted diffusion model with hybrid masking consistently outperforms the linear-masked variant and performs competitively with autoregressive counterparts despite limited pretraining. Systematic ablations reveal that increasing diffusion steps, generation length, and block length improves accuracy but also increases latency, with accuracy plateauing beyond a certain number of diffusion steps. Expanding the training data with diverse GUI domains further reduces latency by about 1.3 seconds and improves grounding accuracy by an average of 20 points across benchmarks. These results demonstrate that discrete DVLMs are a promising modeling framework for GUI grounding and represent an important step toward diffusion-based GUI agents.
ActionReasoningBench: Reasoning about Actions with and without Ramification Constraints
Jun 06, 2024



Reasoning about actions and change (RAC) has historically driven the development of many early AI challenges, such as the frame problem, and many AI disciplines, including non-monotonic and commonsense reasoning. The role of RAC remains important even now, particularly for tasks involving dynamic environments, interactive scenarios, and commonsense reasoning. Despite the progress of Large Language Models (LLMs) in various AI domains, their performance on RAC is underexplored. To address this gap, we introduce a new benchmark, ActionReasoningBench, encompassing 13 domains and rigorously evaluating LLMs across eight different areas of RAC. These include - Object Tracking, Fluent Tracking, State Tracking, Action Executability, Effects of Actions, Numerical RAC, Hallucination Detection, and Composite Questions. Furthermore, we also investigate the indirect effect of actions due to ramification constraints for every domain. Finally, we evaluate our benchmark using open-sourced and commercial state-of-the-art LLMs, including GPT-4o, Gemini-1.0-Pro, Llama2-7b-chat, Llama2-13b-chat, Llama3-8b-instruct, Gemma-2b-instruct, and Gemma-7b-instruct. Our findings indicate that these models face significant challenges across all categories included in our benchmark.
Towards LogiGLUE: A Brief Survey and A Benchmark for Analyzing Logical Reasoning Capabilities of Language Models
Oct 02, 2023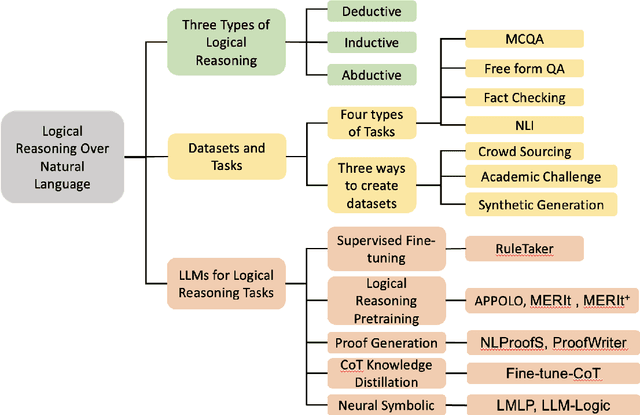
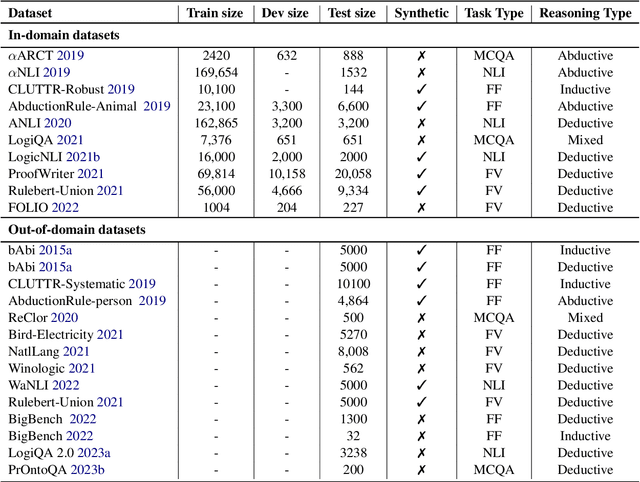
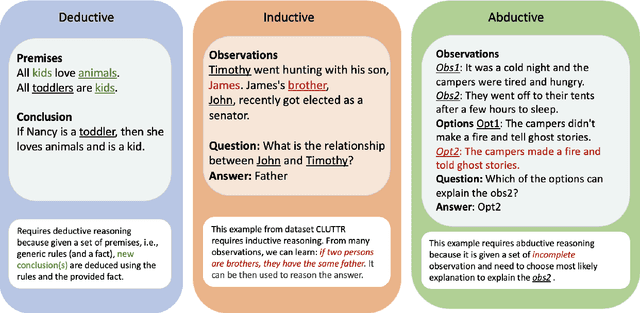
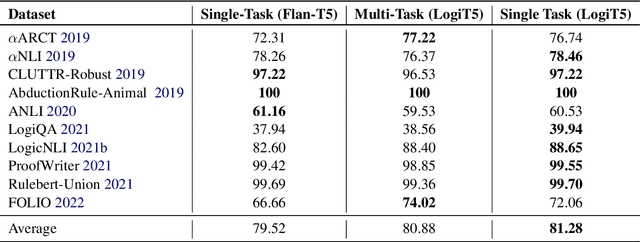
Logical reasoning is fundamental for humans yet presents a substantial challenge in the domain of Artificial Intelligence. Initially, researchers used Knowledge Representation and Reasoning (KR) systems that did not scale and required non trivial manual effort. Recently, the emergence of large language models (LLMs) has demonstrated the ability to overcome various limitations of formal Knowledge Representation (KR) systems. Consequently, there is a growing interest in using LLMs for logical reasoning via natural language. This work strives to understand the proficiency of LLMs in logical reasoning by offering a brief review of the latest progress in this area; with a focus on the logical reasoning datasets, tasks, and the methods adopted to utilize LLMs for reasoning. To offer a thorough analysis, we have compiled a benchmark titled LogiGLUE. This includes 24 varied datasets encompassing deductive, abductive, and inductive reasoning. We have standardized these datasets into Seq2Seq tasks to facilitate straightforward training and evaluation for future research. Utilizing LogiGLUE as a foundation, we have trained an instruction fine tuned language model, resulting in LogiT5. We study single task training, multi task training, and a chain of thought knowledge distillation fine tuning technique to assess the performance of model across the different logical reasoning categories. By this comprehensive process, we aim to shed light on the capabilities and potential pathways for enhancing logical reasoning proficiency in LLMs, paving the way for more advanced and nuanced developments in this critical field.