 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeelsGoodMan: Inferring Semantics of Twitch Neologisms
Aug 18, 2021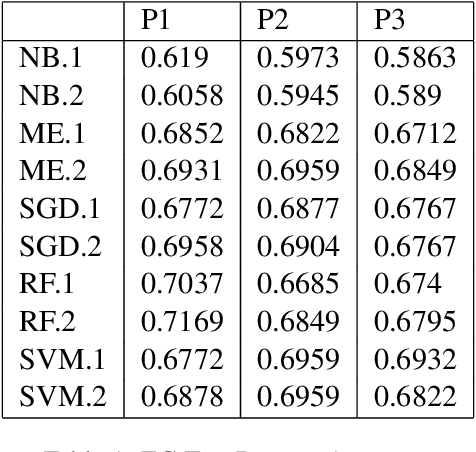
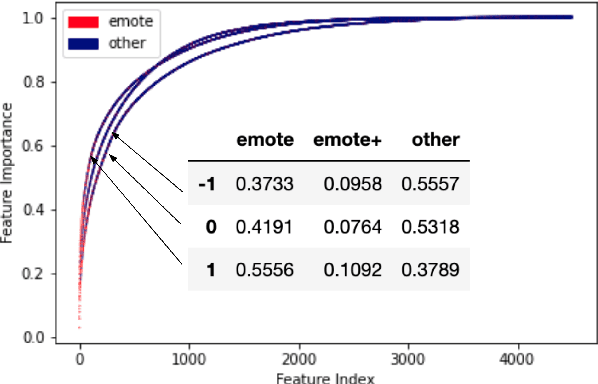
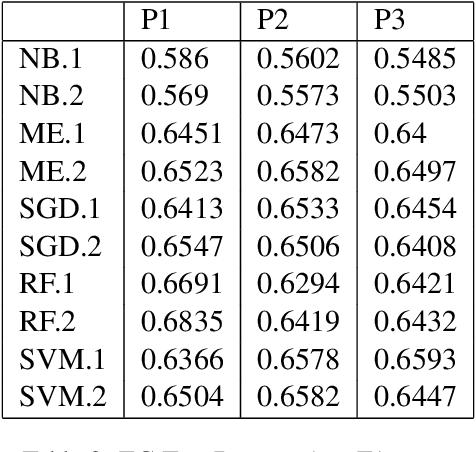
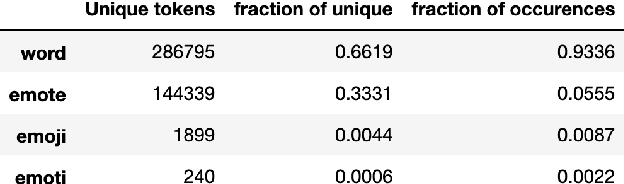
Twitch chats pose a unique problem in natural language understanding due to a large presence of neologisms, specifically emotes. There are a total of 8.06 million emotes, over 400k of which were used in the week studied. There is virtually no information on the meaning or sentiment of emotes, and with a constant influx of new emotes and drift in their frequencies, it becomes impossible to maintain an updated manually-labeled dataset. Our paper makes a two fold contribution. First we establish a new baseline for sentiment analysis on Twitch data, outperforming the previous supervised benchmark by 7.9% points. Secondly, we introduce a simple but powerful unsupervised framework based on word embeddings and k-NN to enrich existing models with out-of-vocabulary knowledge. This framework allows us to auto-generate a pseudo-dictionary of emotes and we show that we can nearly match the supervised benchmark above even when injecting such emote knowledge into sentiment classifiers trained on extraneous datasets such as movie reviews or Twitter.
Learning Mixtures of Gaussians using the k-means Algorithm
Dec 01, 2009
One of the most popular algorithms for clustering in Euclidean space is the $k$-means algorithm; $k$-means is difficult to analyze mathematically, and few theoretical guarantees are known about it, particularly when the data is {\em well-clustered}. In this paper, we attempt to fill this gap in the literature by analyzing the behavior of $k$-means on well-clustered data. In particular, we study the case when each cluster is distributed as a different Gaussian -- or, in other words, when the input comes from a mixture of Gaussians. We analyze three aspects of the $k$-means algorithm under this assumption. First, we show that when the input comes from a mixture of two spherical Gaussians, a variant of the 2-means algorithm successfully isolates the subspace containing the means of the mixture components. Second, we show an exact expression for the convergence of our variant of the 2-means algorithm, when the input is a very large number of samples from a mixture of spherical Gaussians. Our analysis does not require any lower bound on the separation between the mixture components. Finally, we study the sample requirement of $k$-means; for a mixture of 2 spherical Gaussians, we show an upper bound on the number of samples required by a variant of 2-means to get close to the true solution. The sample requirement grows with increasing dimensionality of the data, and decreasing separation between the means of the Gaussians. To match our upper bound, we show an information-theoretic lower bound on any algorithm that learns mixtures of two spherical Gaussians; our lower bound indicates that in the case when the overlap between the probability masses of the two distributions is small, the sample requirement of $k$-means is {\em near-optimal}.
k-means requires exponentially many iterations even in the plane
Dec 01, 2008



The k-means algorithm is a well-known method for partitioning n points that lie in the d-dimensional space into k clusters. Its main features are simplicity and speed in practice. Theoretically, however, the best known upper bound on its running time (i.e. O(n^{kd})) can be exponential in the number of points. Recently, Arthur and Vassilvitskii [3] showed a super-polynomial worst-case analysis, improving the best known lower bound from \Omega(n) to 2^{\Omega(\sqrt{n})} with a construction in d=\Omega(\sqrt{n}) dimensions. In [3] they also conjectured the existence of superpolynomial lower bounds for any d >= 2. Our contribution is twofold: we prove this conjecture and we improve the lower bound, by presenting a simple construction in the plane that leads to the exponential lower bound 2^{\Omega(n)}.