 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Mixtures of Gaussians using the k-means Algorithm
Paper and Code
Dec 01, 2009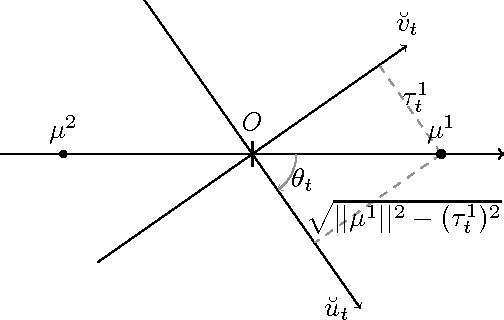
One of the most popular algorithms for clustering in Euclidean space is the $k$-means algorithm; $k$-means is difficult to analyze mathematically, and few theoretical guarantees are known about it, particularly when the data is {\em well-clustered}. In this paper, we attempt to fill this gap in the literature by analyzing the behavior of $k$-means on well-clustered data. In particular, we study the case when each cluster is distributed as a different Gaussian -- or, in other words, when the input comes from a mixture of Gaussians. We analyze three aspects of the $k$-means algorithm under this assumption. First, we show that when the input comes from a mixture of two spherical Gaussians, a variant of the 2-means algorithm successfully isolates the subspace containing the means of the mixture components. Second, we show an exact expression for the convergence of our variant of the 2-means algorithm, when the input is a very large number of samples from a mixture of spherical Gaussians. Our analysis does not require any lower bound on the separation between the mixture components. Finally, we study the sample requirement of $k$-means; for a mixture of 2 spherical Gaussians, we show an upper bound on the number of samples required by a variant of 2-means to get close to the true solution. The sample requirement grows with increasing dimensionality of the data, and decreasing separation between the means of the Gaussians. To match our upper bound, we show an information-theoretic lower bound on any algorithm that learns mixtures of two spherical Gaussians; our lower bound indicates that in the case when the overlap between the probability masses of the two distributions is small, the sample requirement of $k$-means is {\em near-optimal}.