 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCon1M:A Large-scale Benchmark Dataset for Relation Comprehension in Remote Sensing Imagery
Jun 10, 2024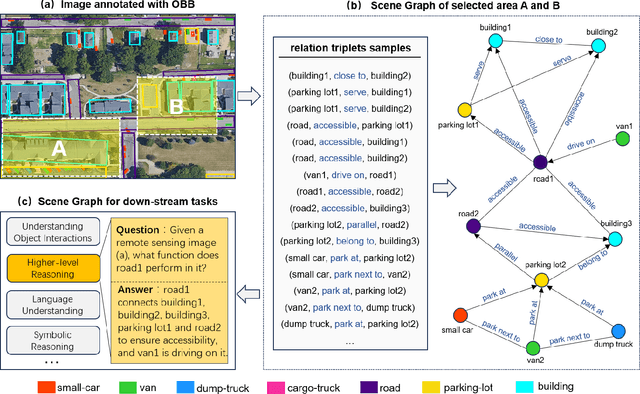
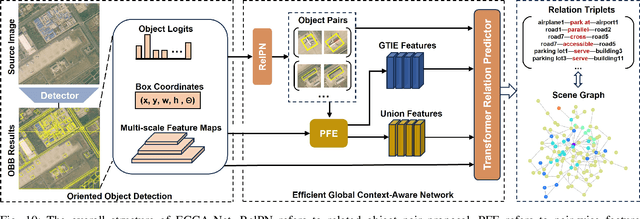
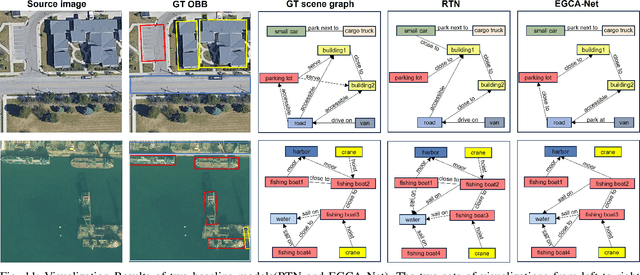
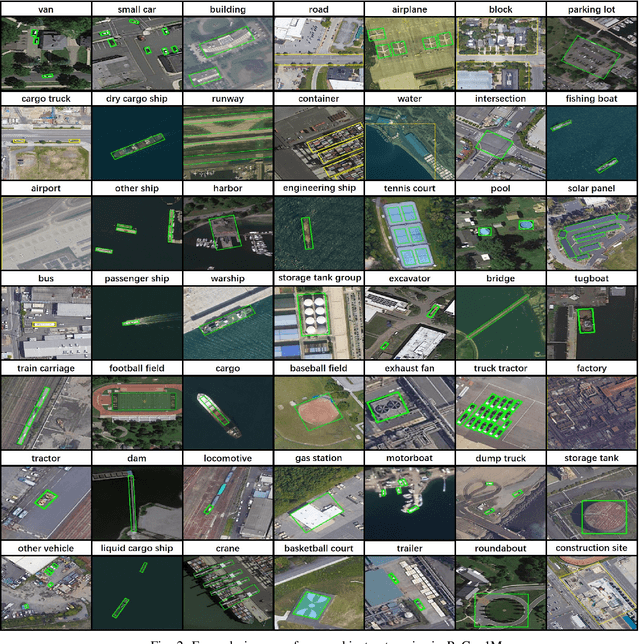
Scene Graph Generation (SGG) is a high-level visual understanding and reasoning task aimed at extracting entities (such as objects) and their interrelationships from images. Significant progress has been made in the study of SGG in natural images in recent years, but its exploration in the domain of remote sensing images remains very limited. The complex characteristics of remote sensing images necessitate higher time and manual interpretation costs for annotation compared to natural images. The lack of a large-scale public SGG benchmark is a major impediment to the advancement of SGG-related research in aerial imagery. In this paper, we introduce the first publicly available large-scale, million-level relation dataset in the field of remote sensing images which is named as ReCon1M. Specifically, our dataset is built upon Fair1M and comprises 21,392 images. It includes annotations for 859,751 object bounding boxes across 60 different categories, and 1,149,342 relation triplets across 64 categories based on these bounding boxes. We provide a detailed description of the dataset's characteristics and statistical information. We conducted two object detection tasks and three sub-tasks within SGG on this dataset, assessing the performance of mainstream methods on these tasks.
Exploring a Fine-Grained Multiscale Method for Cross-Modal Remote Sensing Image Retrieval
Apr 21, 2022
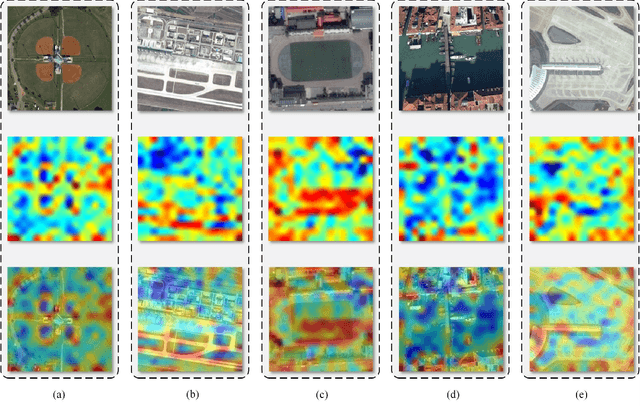
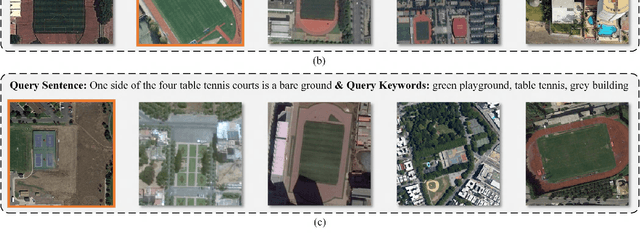
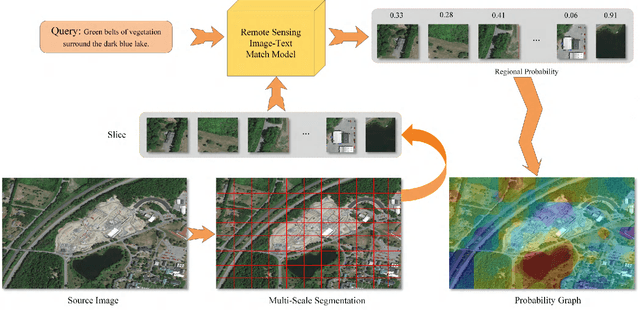
Remote sensing (RS) cross-modal text-image retrieval has attracted extensive attention for its advantages of flexible input and efficient query. However, traditional methods ignore the characteristics of multi-scale and redundant targets in RS image, leading to the degradation of retrieval accuracy. To cope with the problem of multi-scale scarcity and target redundancy in RS multimodal retrieval task, we come up with a novel asymmetric multimodal feature matching network (AMFMN). Our model adapts to multi-scale feature inputs, favors multi-source retrieval methods, and can dynamically filter redundant features. AMFMN employs the multi-scale visual self-attention (MVSA) module to extract the salient features of RS image and utilizes visual features to guide the text representation. Furthermore, to alleviate the positive samples ambiguity caused by the strong intraclass similarity in RS image, we propose a triplet loss function with dynamic variable margin based on prior similarity of sample pairs. Finally, unlike the traditional RS image-text dataset with coarse text and higher intraclass similarity, we construct a fine-grained and more challenging Remote sensing Image-Text Match dataset (RSITMD), which supports RS image retrieval through keywords and sentence separately and jointly. Experiments on four RS text-image datasets demonstrate that the proposed model can achieve state-of-the-art performance in cross-modal RS text-image retrieval task.