 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Evolution Framework with Genetic Algorithm for Multi-Task Reinforcement Learning
Feb 19, 2025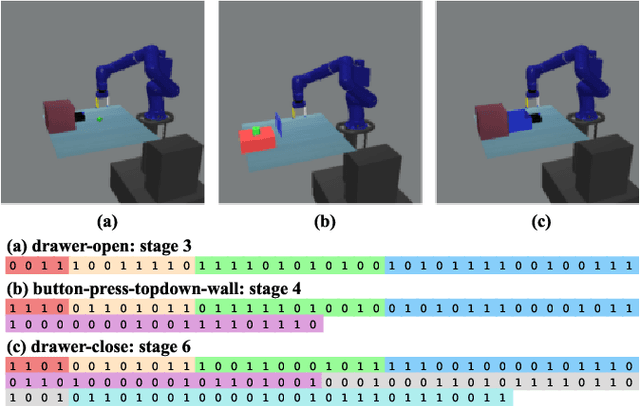



Multi-task reinforcement learning employs a single policy to complete various tasks, aiming to develop an agent with generalizability across different scenarios. Given the shared characteristics of tasks, the agent's learning efficiency can be enhanced through parameter sharing. Existing approaches typically use a routing network to generate specific routes for each task and reconstruct a set of modules into diverse models to complete multiple tasks simultaneously. However, due to the inherent difference between tasks, it is crucial to allocate resources based on task difficulty, which is constrained by the model's structure. To this end, we propose a Model Evolution framework with Genetic Algorithm (MEGA), which enables the model to evolve during training according to the difficulty of the tasks. When the current model is insufficient for certain tasks, the framework will automatically incorporate additional modules, enhancing the model's capabilities. Moreover, to adapt to our model evolution framework, we introduce a genotype module-level model, using binary sequences as genotype policies for model reconstruction, while leveraging a non-gradient genetic algorithm to optimize these genotype policies. Unlike routing networks with fixed output dimensions, our approach allows for the dynamic adjustment of the genotype policy length, enabling it to accommodate models with a varying number of modules. We conducted experiments on various robotics manipulation tasks in the Meta-World benchmark. Our state-of-the-art performance demonstrated the effectiveness of the MEGA framework. We will release our source code to the public.
Positive2Negative: Breaking the Information-Lossy Barrier in Self-Supervised Single Image Denoising
Dec 21, 2024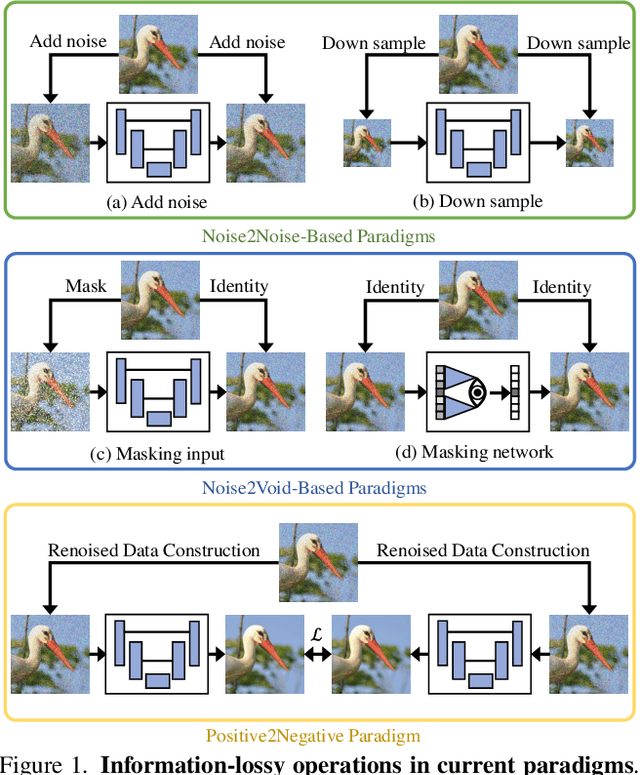
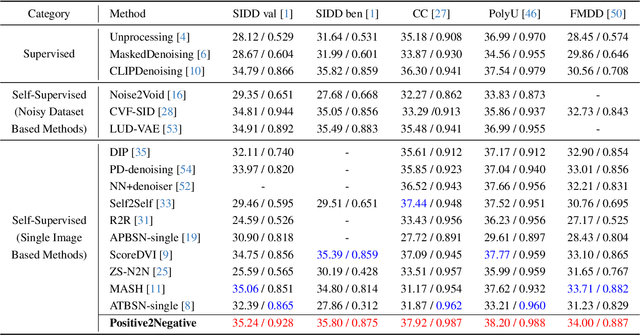


Image denoising enhances image quality, serving as a foundational technique across various computational photography applications. The obstacle to clean image acquisition in real scenarios necessitates the development of self-supervised image denoising methods only depending on noisy images, especially a single noisy image. Existing self-supervised image denoising paradigms (Noise2Noise and Noise2Void) rely heavily on information-lossy operations, such as downsampling and masking, culminating in low quality denoising performance. In this paper, we propose a novel self-supervised single image denoising paradigm, Positive2Negative, to break the information-lossy barrier. Our paradigm involves two key steps: Renoised Data Construction (RDC) and Denoised Consistency Supervision (DCS). RDC renoises the predicted denoised image by the predicted noise to construct multiple noisy images, preserving all the information of the original image. DCS ensures consistency across the multiple denoised images, supervising the network to learn robust denoising. Our Positive2Negative paradigm achieves state-of-the-art performance in self-supervised single image denoising with significant speed improvements. The code will be released to the public.
Rethinking Model Redundancy for Low-light Image Enhancement
Dec 21, 2024Low-light image enhancement (LLIE) is a fundamental task in computational photography, aiming to improve illumination, reduce noise, and enhance the image quality of low-light images. While recent advancements primarily focus on customizing complex neural network models, we have observed significant redundancy in these models, limiting further performance improvement. In this paper, we investigate and rethink the model redundancy for LLIE, identifying parameter harmfulness and parameter uselessness. Inspired by the rethinking, we propose two innovative techniques to mitigate model redundancy while improving the LLIE performance: Attention Dynamic Reallocation (ADR) and Parameter Orthogonal Generation (POG). ADR dynamically reallocates appropriate attention based on original attention, thereby mitigating parameter harmfulness. POG learns orthogonal basis embeddings of parameters and prevents degradation to static parameters, thereby mitigating parameter uselessness. Experiments validate the effectiveness of our techniques. We will release the code to the public.
Complementary Advantages: Exploiting Cross-Field Frequency Correlation for NIR-Assisted Image Denoising
Dec 21, 2024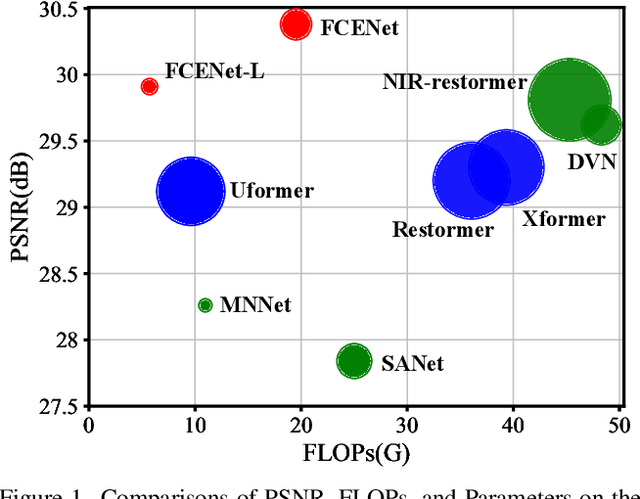
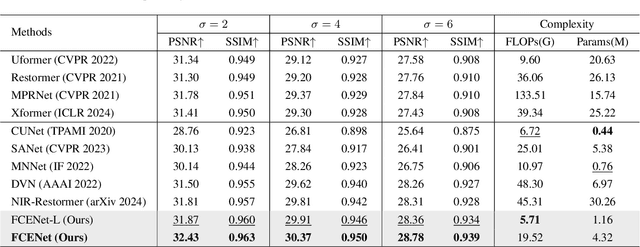

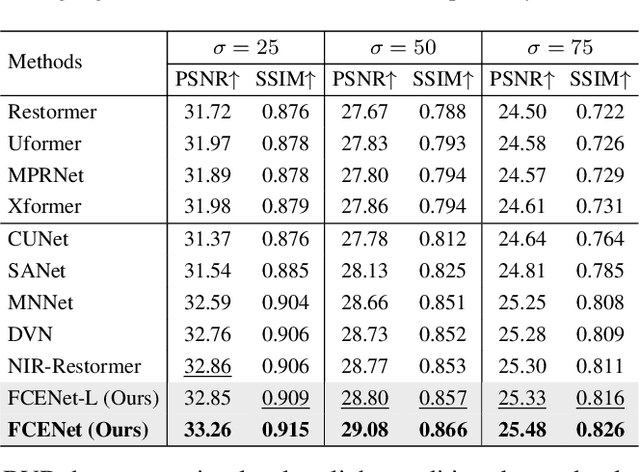
Existing single-image denoising algorithms often struggle to restore details when dealing with complex noisy images. The introduction of near-infrared (NIR) images offers new possibilities for RGB image denoising. However, due to the inconsistency between NIR and RGB images, the existing works still struggle to balance the contributions of two fields in the process of image fusion. In response to this, in this paper, we develop a cross-field Frequency Correlation Exploiting Network (FCENet) for NIR-assisted image denoising. We first propose the frequency correlation prior based on an in-depth statistical frequency analysis of NIR-RGB image pairs. The prior reveals the complementary correlation of NIR and RGB images in the frequency domain. Leveraging frequency correlation prior, we then establish a frequency learning framework composed of Frequency Dynamic Selection Mechanism (FDSM) and Frequency Exhaustive Fusion Mechanism (FEFM). FDSM dynamically selects complementary information from NIR and RGB images in the frequency domain, and FEFM strengthens the control of common and differential features during the fusion of NIR and RGB features. Extensive experiments on simulated and real data validate that our method outperforms various state-of-the-art methods in terms of image quality and computational efficiency. The code will be released to the public.
ReCon1M:A Large-scale Benchmark Dataset for Relation Comprehension in Remote Sensing Imagery
Jun 10, 2024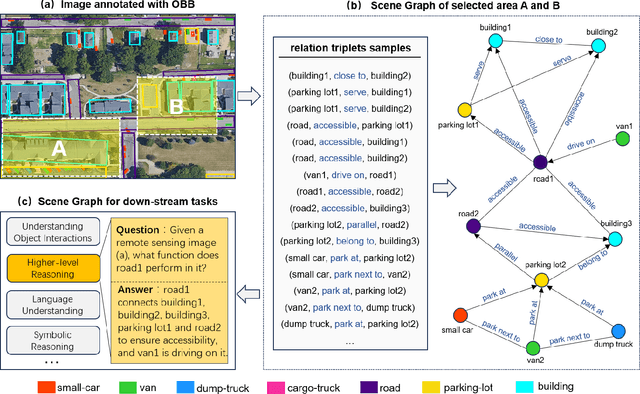
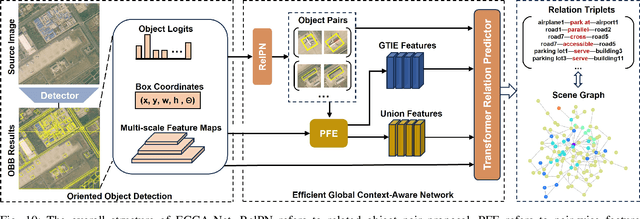
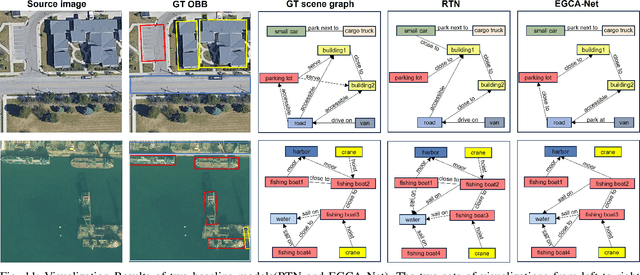
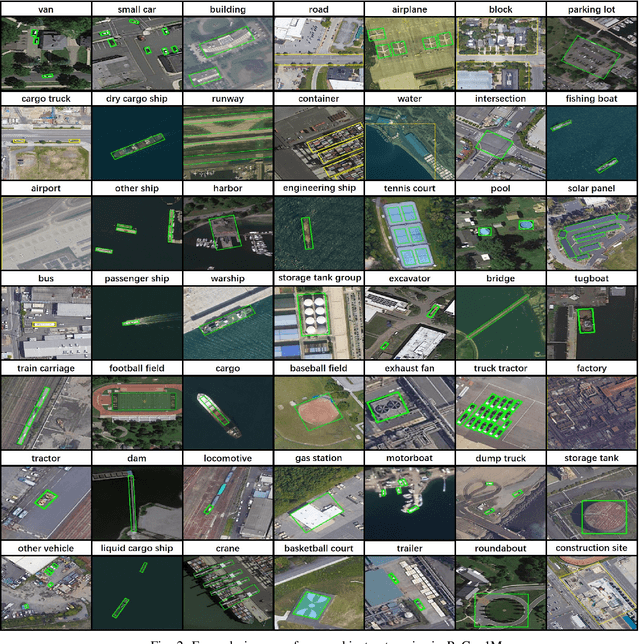
Scene Graph Generation (SGG) is a high-level visual understanding and reasoning task aimed at extracting entities (such as objects) and their interrelationships from images. Significant progress has been made in the study of SGG in natural images in recent years, but its exploration in the domain of remote sensing images remains very limited. The complex characteristics of remote sensing images necessitate higher time and manual interpretation costs for annotation compared to natural images. The lack of a large-scale public SGG benchmark is a major impediment to the advancement of SGG-related research in aerial imagery. In this paper, we introduce the first publicly available large-scale, million-level relation dataset in the field of remote sensing images which is named as ReCon1M. Specifically, our dataset is built upon Fair1M and comprises 21,392 images. It includes annotations for 859,751 object bounding boxes across 60 different categories, and 1,149,342 relation triplets across 64 categories based on these bounding boxes. We provide a detailed description of the dataset's characteristics and statistical information. We conducted two object detection tasks and three sub-tasks within SGG on this dataset, assessing the performance of mainstream methods on these tasks.
TAFormer: A Unified Target-Aware Transformer for Video and Motion Joint Prediction in Aerial Scenes
Mar 27, 2024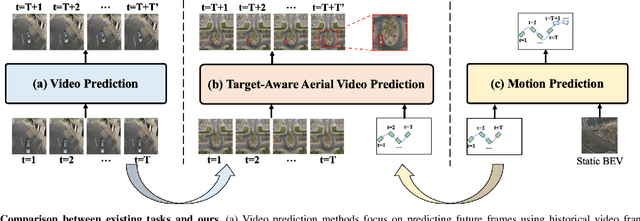
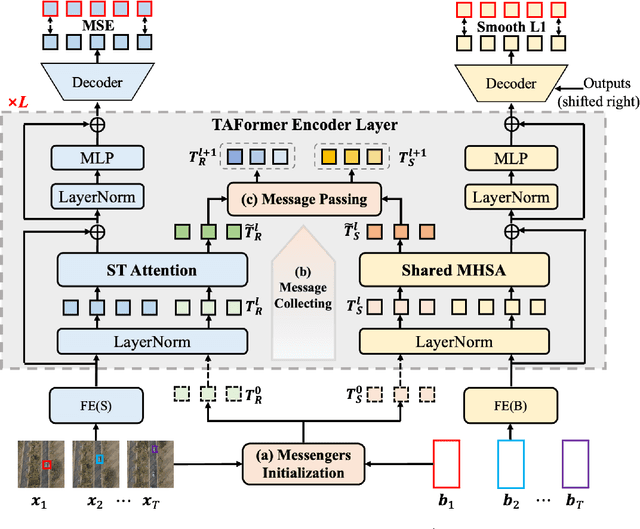
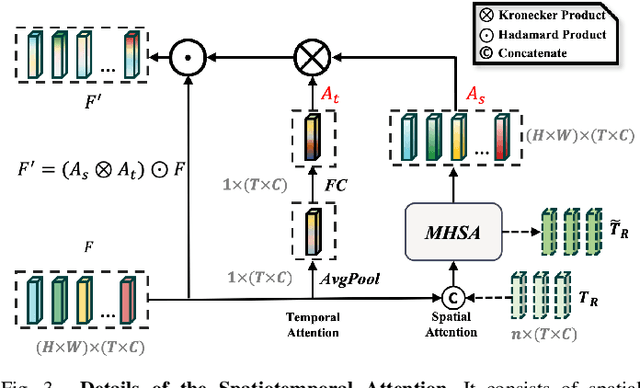
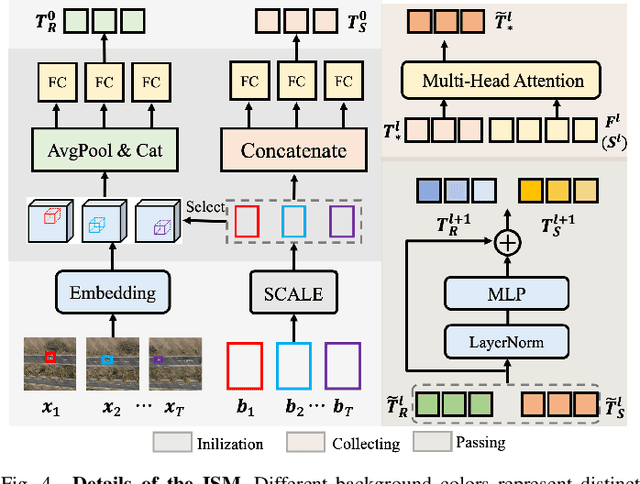
As drone technology advances, using unmanned aerial vehicles for aerial surveys has become the dominant trend in modern low-altitude remote sensing. The surge in aerial video data necessitates accurate prediction for future scenarios and motion states of the interested target, particularly in applications like traffic management and disaster response. Existing video prediction methods focus solely on predicting future scenes (video frames), suffering from the neglect of explicitly modeling target's motion states, which is crucial for aerial video interpretation. To address this issue, we introduce a novel task called Target-Aware Aerial Video Prediction, aiming to simultaneously predict future scenes and motion states of the target. Further, we design a model specifically for this task, named TAFormer, which provides a unified modeling approach for both video and target motion states. Specifically, we introduce Spatiotemporal Attention (STA), which decouples the learning of video dynamics into spatial static attention and temporal dynamic attention, effectively modeling the scene appearance and motion. Additionally, we design an Information Sharing Mechanism (ISM), which elegantly unifies the modeling of video and target motion by facilitating information interaction through two sets of messenger tokens. Moreover, to alleviate the difficulty of distinguishing targets in blurry predictions, we introduce Target-Sensitive Gaussian Loss (TSGL), enhancing the model's sensitivity to both target's position and content. Extensive experiments on UAV123VP and VisDroneVP (derived from single-object tracking datasets) demonstrate the exceptional performance of TAFormer in target-aware video prediction, showcasing its adaptability to the additional requirements of aerial video interpretation for target awareness.
SFTformer: A Spatial-Frequency-Temporal Correlation-Decoupling Transformer for Radar Echo Extrapolation
Feb 28, 2024
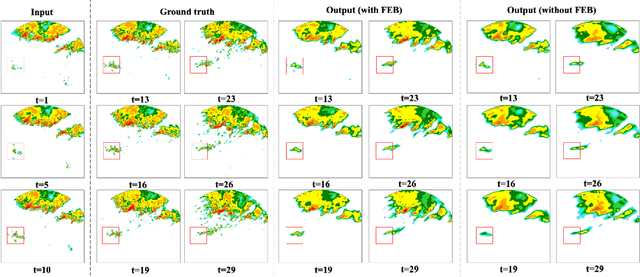
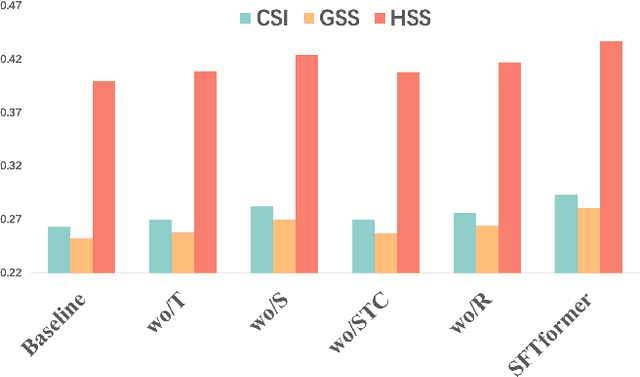
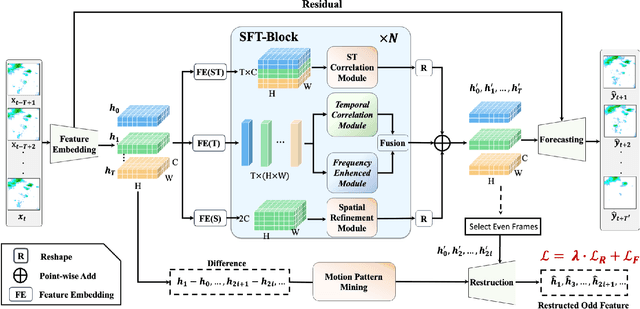
Extrapolating future weather radar echoes from past observations is a complex task vital for precipitation nowcasting. The spatial morphology and temporal evolution of radar echoes exhibit a certain degree of correlation, yet they also possess independent characteristics. {Existing methods learn unified spatial and temporal representations in a highly coupled feature space, emphasizing the correlation between spatial and temporal features but neglecting the explicit modeling of their independent characteristics, which may result in mutual interference between them.} To effectively model the spatiotemporal dynamics of radar echoes, we propose a Spatial-Frequency-Temporal correlation-decoupling Transformer (SFTformer). The model leverages stacked multiple SFT-Blocks to not only mine the correlation of the spatiotemporal dynamics of echo cells but also avoid the mutual interference between the temporal modeling and the spatial morphology refinement by decoupling them. Furthermore, inspired by the practice that weather forecast experts effectively review historical echo evolution to make accurate predictions, SFTfomer incorporates a joint training paradigm for historical echo sequence reconstruction and future echo sequence prediction. Experimental results on the HKO-7 dataset and ChinaNorth-2021 dataset demonstrate the superior performance of SFTfomer in short(1h), mid(2h), and long-term(3h) precipitation nowcasting.