 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveil: Unified Visual-Textual Integration and Distillation for Multi-modal Document Retrieval
May 23, 2026Document retrieval in real-world scenarios faces significant challenges due to diverse document formats and modalities. Traditional text-based approaches rely on tailored parsing techniques that disregard layout information and are prone to errors, while recent parsing-free visual methods often struggle to capture fine-grained textual semantics in text-rich scenarios. To address these limitations, we propose \textbf{Unveil}, a novel visual-textual embedding framework that effectively integrates textual and visual features for robust document representation. Through knowledge distillation, we transfer the semantic understanding capabilities from the visual-textual embedding model to a purely visual model, enabling efficient parsing-free retrieval while preserving semantic fidelity. Experimental results demonstrate that our visual-textual embedding method surpasses existing approaches, while knowledge distillation successfully bridges the performance gap between visual-textual and visual-only methods, improving both retrieval accuracy and efficiency.
ZeroSearch: Incentivize the Search Capability of LLMs without Searching
May 07, 2025Effective information searching is essential for enhancing the reasoning and generation capabilities of large language models (LLMs). Recent research has explored using reinforcement learning (RL) to improve LLMs' search capabilities by interacting with live search engines in real-world environments. While these approaches show promising results, they face two major challenges: (1) Uncontrolled Document Quality: The quality of documents returned by search engines is often unpredictable, introducing noise and instability into the training process. (2) Prohibitively High API Costs: RL training requires frequent rollouts, potentially involving hundreds of thousands of search requests, which incur substantial API expenses and severely constrain scalability. To address these challenges, we introduce ZeroSearch, a reinforcement learning framework that incentivizes the search capabilities of LLMs without interacting with real search engines. Our approach begins with lightweight supervised fine-tuning to transform the LLM into a retrieval module capable of generating both relevant and noisy documents in response to a query. During RL training, we employ a curriculum-based rollout strategy that incrementally degrades the quality of generated documents, progressively eliciting the model's reasoning ability by exposing it to increasingly challenging retrieval scenarios. Extensive experiments demonstrate that ZeroSearch effectively incentivizes the search capabilities of LLMs using a 3B LLM as the retrieval module. Remarkably, a 7B retrieval module achieves comparable performance to the real search engine, while a 14B retrieval module even surpasses it. Furthermore, it generalizes well across both base and instruction-tuned models of various parameter sizes and is compatible with a wide range of RL algorithms.
Model Evolution Framework with Genetic Algorithm for Multi-Task Reinforcement Learning
Feb 19, 2025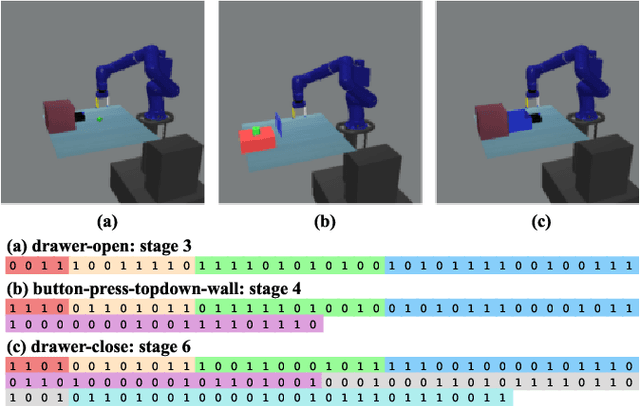



Multi-task reinforcement learning employs a single policy to complete various tasks, aiming to develop an agent with generalizability across different scenarios. Given the shared characteristics of tasks, the agent's learning efficiency can be enhanced through parameter sharing. Existing approaches typically use a routing network to generate specific routes for each task and reconstruct a set of modules into diverse models to complete multiple tasks simultaneously. However, due to the inherent difference between tasks, it is crucial to allocate resources based on task difficulty, which is constrained by the model's structure. To this end, we propose a Model Evolution framework with Genetic Algorithm (MEGA), which enables the model to evolve during training according to the difficulty of the tasks. When the current model is insufficient for certain tasks, the framework will automatically incorporate additional modules, enhancing the model's capabilities. Moreover, to adapt to our model evolution framework, we introduce a genotype module-level model, using binary sequences as genotype policies for model reconstruction, while leveraging a non-gradient genetic algorithm to optimize these genotype policies. Unlike routing networks with fixed output dimensions, our approach allows for the dynamic adjustment of the genotype policy length, enabling it to accommodate models with a varying number of modules. We conducted experiments on various robotics manipulation tasks in the Meta-World benchmark. Our state-of-the-art performance demonstrated the effectiveness of the MEGA framework. We will release our source code to the public.
C$^{2}$INet: Realizing Incremental Trajectory Prediction with Prior-Aware Continual Causal Intervention
Nov 19, 2024Trajectory prediction for multi-agents in complex scenarios is crucial for applications like autonomous driving. However, existing methods often overlook environmental biases, which leads to poor generalization. Additionally, hardware constraints limit the use of large-scale data across environments, and continual learning settings exacerbate the challenge of catastrophic forgetting. To address these issues, we propose the Continual Causal Intervention (C$^{2}$INet) method for generalizable multi-agent trajectory prediction within a continual learning framework. Using variational inference, we align environment-related prior with posterior estimator of confounding factors in the latent space, thereby intervening in causal correlations that affect trajectory representation. Furthermore, we store optimal variational priors across various scenarios using a memory queue, ensuring continuous debiasing during incremental task training. The proposed C$^{2}$INet enhances adaptability to diverse tasks while preserving previous task information to prevent catastrophic forgetting. It also incorporates pruning strategies to mitigate overfitting. Comparative evaluations on three real and synthetic complex datasets against state-of-the-art methods demonstrate that our proposed method consistently achieves reliable prediction performance, effectively mitigating confounding factors unique to different scenarios. This highlights the practical value of our method for real-world applications.
Retrieved In-Context Principles from Previous Mistakes
Jul 08, 2024



In-context learning (ICL) has been instrumental in adapting Large Language Models (LLMs) to downstream tasks using correct input-output examples. Recent advances have attempted to improve model performance through principles derived from mistakes, yet these approaches suffer from lack of customization and inadequate error coverage. To address these limitations, we propose Retrieved In-Context Principles (RICP), a novel teacher-student framework. In RICP, the teacher model analyzes mistakes from the student model to generate reasons and insights for preventing similar mistakes. These mistakes are clustered based on their underlying reasons for developing task-level principles, enhancing the error coverage of principles. During inference, the most relevant mistakes for each question are retrieved to create question-level principles, improving the customization of the provided guidance. RICP is orthogonal to existing prompting methods and does not require intervention from the teacher model during inference. Experimental results across seven reasoning benchmarks reveal that RICP effectively enhances performance when applied to various prompting strategies.
MetaTra: Meta-Learning for Generalized Trajectory Prediction in Unseen Domain
Feb 13, 2024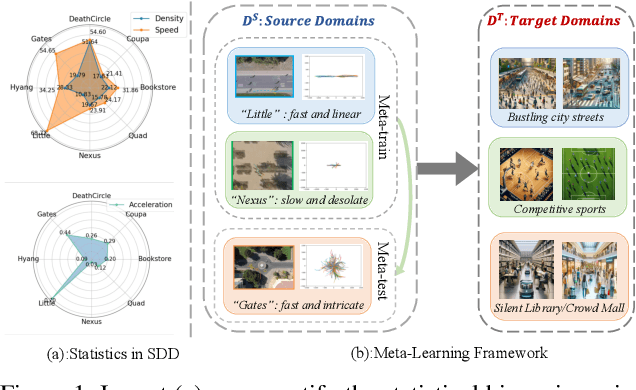
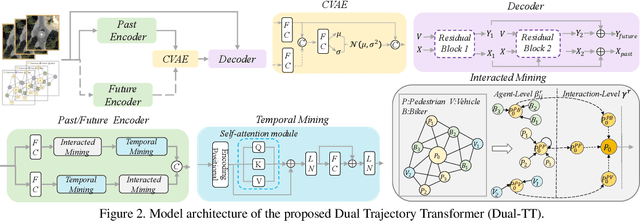

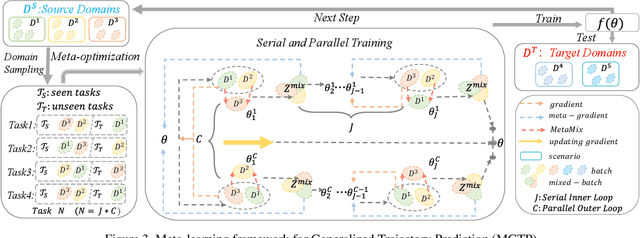
Trajectory prediction has garnered widespread attention in different fields, such as autonomous driving and robotic navigation. However, due to the significant variations in trajectory patterns across different scenarios, models trained in known environments often falter in unseen ones. To learn a generalized model that can directly handle unseen domains without requiring any model updating, we propose a novel meta-learning-based trajectory prediction method called MetaTra. This approach incorporates a Dual Trajectory Transformer (Dual-TT), which enables a thorough exploration of the individual intention and the interactions within group motion patterns in diverse scenarios. Building on this, we propose a meta-learning framework to simulate the generalization process between source and target domains. Furthermore, to enhance the stability of our prediction outcomes, we propose a Serial and Parallel Training (SPT) strategy along with a feature augmentation method named MetaMix. Experimental results on several real-world datasets confirm that MetaTra not only surpasses other state-of-the-art methods but also exhibits plug-and-play capabilities, particularly in the realm of domain generalization.
Quartet Logic: A Four-Step Reasoning framework for advancing Short Text Classification
Jan 06, 2024



Short Text Classification (STC) is crucial for processing and comprehending the brief but substantial content prevalent on contemporary digital platforms. The STC encounters difficulties in grasping semantic and syntactic intricacies, an issue that is apparent in traditional pre-trained language models. Although Graph Convolutional Networks enhance performance by integrating external knowledge bases, these methods are limited by the quality and extent of the knowledge applied. Recently, the emergence of Large Language Models (LLMs) and Chain-of-Thought (CoT) has significantly improved the performance of complex reasoning tasks. However, some studies have highlighted the limitations of their application in fundamental NLP tasks. Consequently, this study sought to employ CoT to investigate the capabilities of LLMs in STC tasks. This study introduces Quartet Logic: A Four-Step Reasoning (QLFR) framework. This framework primarily incorporates Syntactic and Semantic Enrichment CoT, effectively decomposing the STC task into four distinct steps: (i) essential concept identification, (ii) common-sense knowledge retrieval, (iii) text rewriting, and (iv) classification. This elicits the inherent knowledge and abilities of LLMs to address the challenges in STC. Surprisingly, we found that QLFR can also improve the performance of smaller models. Therefore, we developed a CoT-Driven Multi-task learning (QLFR-CML) method to facilitate the knowledge transfer from LLMs to smaller models. Extensive experimentation across six short-text benchmarks validated the efficacy of the proposed methods. Notably, QLFR achieved state-of-the-art performance on all datasets, with significant improvements, particularly on the Ohsumed and TagMyNews datasets.
Towards Verifiable Text Generation with Evolving Memory and Self-Reflection
Dec 14, 2023
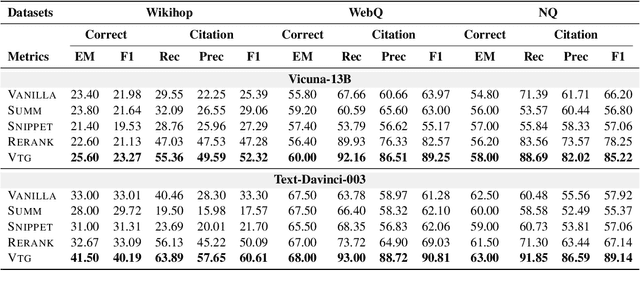
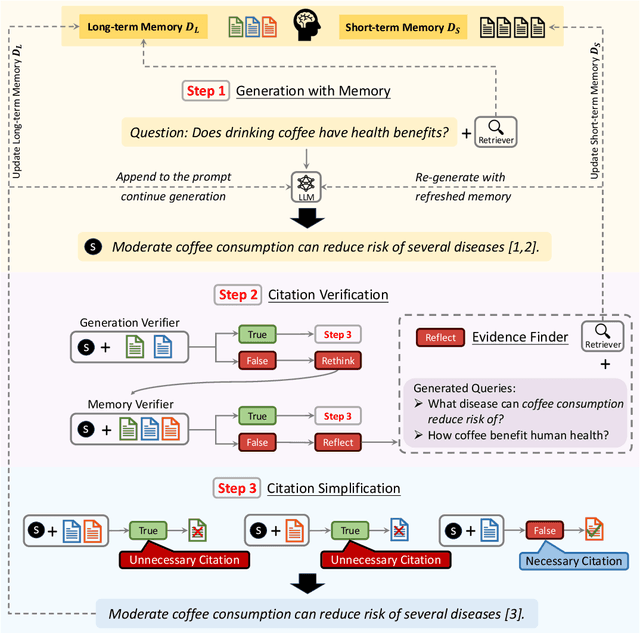
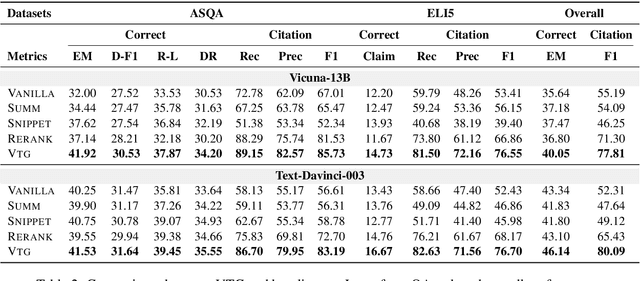
Large Language Models (LLMs) face several challenges, including the tendency to produce incorrect outputs, known as hallucination. An effective solution is verifiable text generation, which prompts LLMs to generate content with citations for accuracy verification. However, verifiable text generation is non-trivial due to the focus-shifting phenomenon, the dilemma between the precision and scope in document retrieval, and the intricate reasoning required to discern the relationship between the claim and citations. In this paper, we present VTG, an innovative approach for Verifiable Text Generation with evolving memory and self-reflection. VTG maintains evolving long short-term memory to retain both valuable documents and up-to-date documents. Active retrieval and diverse query generation are utilized to enhance both the precision and scope of the retrieved documents. Furthermore, VTG features a two-tier verifier and an evidence finder, enabling rethinking and reflection on the relationship between the claim and citations. We conduct extensive experiments on five datasets across three knowledge-intensive tasks and the results reveal that VTG significantly outperforms existing baselines.
Model-enhanced Vector Index
Sep 23, 2023

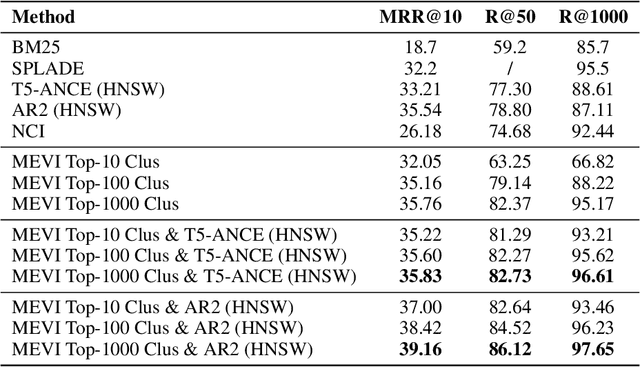

Embedding-based retrieval methods construct vector indices to search for document representations that are most similar to the query representations. They are widely used in document retrieval due to low latency and decent recall performance. Recent research indicates that deep retrieval solutions offer better model quality, but are hindered by unacceptable serving latency and the inability to support document updates. In this paper, we aim to enhance the vector index with end-to-end deep generative models, leveraging the differentiable advantages of deep retrieval models while maintaining desirable serving efficiency. We propose Model-enhanced Vector Index (MEVI), a differentiable model-enhanced index empowered by a twin-tower representation model. MEVI leverages a Residual Quantization (RQ) codebook to bridge the sequence-to-sequence deep retrieval and embedding-based models. To substantially reduce the inference time, instead of decoding the unique document ids in long sequential steps, we first generate some semantic virtual cluster ids of candidate documents in a small number of steps, and then leverage the well-adapted embedding vectors to further perform a fine-grained search for the relevant documents in the candidate virtual clusters. We empirically show that our model achieves better performance on the commonly used academic benchmarks MSMARCO Passage and Natural Questions, with comparable serving latency to dense retrieval solutions.
A Neural Corpus Indexer for Document Retrieval
Jun 06, 2022
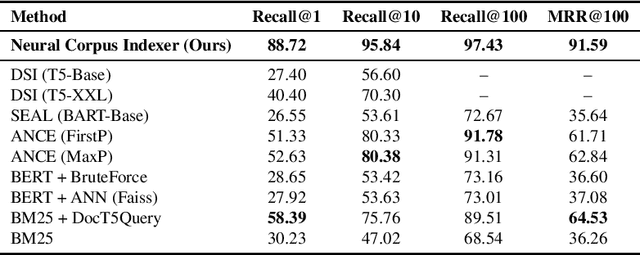
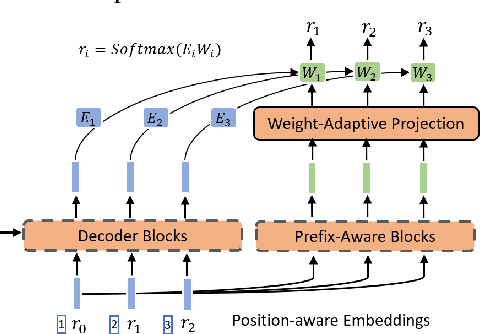
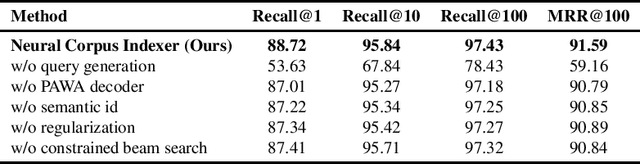
Current state-of-the-art document retrieval solutions mainly follow an index-retrieve paradigm, where the index is hard to be optimized for the final retrieval target. In this paper, we aim to show that an end-to-end deep neural network unifying training and indexing stages can significantly improve the recall performance of traditional methods. To this end, we propose Neural Corpus Indexer (NCI), a sequence-to-sequence network that generates relevant document identifiers directly for a designated query. To optimize the recall performance of NCI, we invent a prefix-aware weight-adaptive decoder architecture, and leverage tailored techniques including query generation, semantic document identifiers and consistency-based regularization. Empirical studies demonstrated the superiority of NCI on a commonly used academic benchmark, achieving +51.9% relative improvement on NQ320k dataset compared to the best baseline.