 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding the Delta: Unifying Remote Sensing Change Detection and Understanding with Multimodal Large Language Models
Apr 15, 2026While Multimodal Large Language Models (MLLMs) excel in general vision-language tasks, their application to remote sensing change understanding is hindered by a fundamental "temporal blindness". Existing architectures lack intrinsic mechanisms for multi-temporal contrastive reasoning and struggle with precise spatial grounding. To address this, we first introduce Delta-QA, a comprehensive benchmark comprising 180k visual question-answering samples. Delta-QA unifies pixel-level segmentation and visual question answering across bi- and tri-temporal scenarios, structuring change interpretation into four progressive cognitive dimensions. Methodologically, we propose Delta-LLaVA, a novel MLLM framework explicitly tailored for multi-temporal remote sensing interpretation. It overcomes the limitations of naive feature concatenation through three core innovations: a Change-Enhanced Attention module that systematically isolates and amplifies visual differences, a Change-SEG module utilizing Change Prior Embedding to extract differentiable difference features as input for the LLM, and Local Causal Attention to prevent cross-temporal contextual leakage. Extensive experiments demonstrate that Delta-LLaVA decisively outperforms leading generalist MLLMs and specialized segmentation models in complex change deduction and high-precision boundary localization, establishing a unified framework for earth observation intelligence.
Clue Matters: Leveraging Latent Visual Clues to Empower Video Reasoning
Mar 16, 2026Multi-modal Large Language Models (MLLMs) have significantly advanced video reasoning, yet Video Question Answering (VideoQA) remains challenging due to its demand for temporal causal reasoning and evidence-grounded answer generation. Prevailing end-to-end MLLM frameworks lack explicit structured reasoning between visual perception and answer derivation, causing severe hallucinations and poor interpretability. Existing methods also fail to address three core gaps: faithful visual clue extraction, utility-aware clue filtering, and end-to-end clue-answer alignment. Inspired by hierarchical human visual cognition, we propose ClueNet, a clue-aware video reasoning framework with a two-stage supervised fine-tuning paradigm without extensive base model modifications. Decoupled supervision aligns clue extraction and chain-based reasoning, while inference supervision with an adaptive clue filter refines high-order reasoning, alongside lightweight modules for efficient inference. Experiments on NExT-QA, STAR, and MVBench show that ClueNet outperforms state-of-the-art methods by $\ge$ 1.1%, with superior generalization, hallucination mitigation, inference efficiency, and cross-backbone compatibility. This work bridges the perception-to-generation gap in MLLM video understanding, providing an interpretable, faithful reasoning paradigm for high-stakes VideoQA applications.
FusionTrack: End-to-End Multi-Object Tracking in Arbitrary Multi-View Environment
May 24, 2025Multi-view multi-object tracking (MVMOT) has found widespread applications in intelligent transportation, surveillance systems, and urban management. However, existing studies rarely address genuinely free-viewpoint MVMOT systems, which could significantly enhance the flexibility and scalability of cooperative tracking systems. To bridge this gap, we first construct the Multi-Drone Multi-Object Tracking (MDMOT) dataset, captured by mobile drone swarms across diverse real-world scenarios, initially establishing the first benchmark for multi-object tracking in arbitrary multi-view environment. Building upon this foundation, we propose \textbf{FusionTrack}, an end-to-end framework that reasonably integrates tracking and re-identification to leverage multi-view information for robust trajectory association. Extensive experiments on our MDMOT and other benchmark datasets demonstrate that FusionTrack achieves state-of-the-art performance in both single-view and multi-view tracking.
C$^{2}$INet: Realizing Incremental Trajectory Prediction with Prior-Aware Continual Causal Intervention
Nov 19, 2024Trajectory prediction for multi-agents in complex scenarios is crucial for applications like autonomous driving. However, existing methods often overlook environmental biases, which leads to poor generalization. Additionally, hardware constraints limit the use of large-scale data across environments, and continual learning settings exacerbate the challenge of catastrophic forgetting. To address these issues, we propose the Continual Causal Intervention (C$^{2}$INet) method for generalizable multi-agent trajectory prediction within a continual learning framework. Using variational inference, we align environment-related prior with posterior estimator of confounding factors in the latent space, thereby intervening in causal correlations that affect trajectory representation. Furthermore, we store optimal variational priors across various scenarios using a memory queue, ensuring continuous debiasing during incremental task training. The proposed C$^{2}$INet enhances adaptability to diverse tasks while preserving previous task information to prevent catastrophic forgetting. It also incorporates pruning strategies to mitigate overfitting. Comparative evaluations on three real and synthetic complex datasets against state-of-the-art methods demonstrate that our proposed method consistently achieves reliable prediction performance, effectively mitigating confounding factors unique to different scenarios. This highlights the practical value of our method for real-world applications.
MetaTra: Meta-Learning for Generalized Trajectory Prediction in Unseen Domain
Feb 13, 2024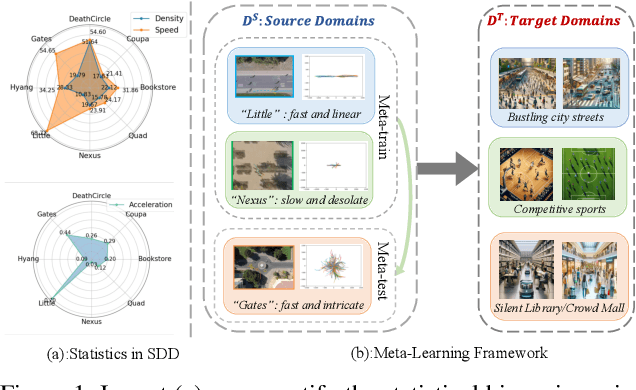
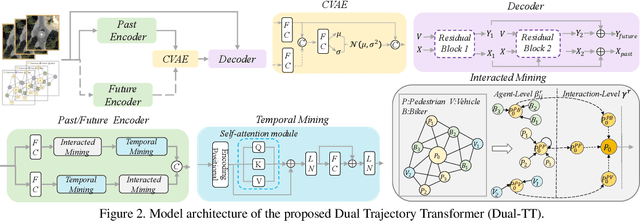

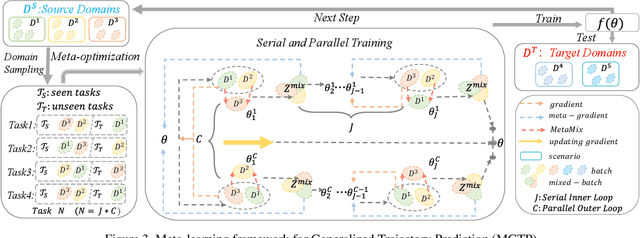
Trajectory prediction has garnered widespread attention in different fields, such as autonomous driving and robotic navigation. However, due to the significant variations in trajectory patterns across different scenarios, models trained in known environments often falter in unseen ones. To learn a generalized model that can directly handle unseen domains without requiring any model updating, we propose a novel meta-learning-based trajectory prediction method called MetaTra. This approach incorporates a Dual Trajectory Transformer (Dual-TT), which enables a thorough exploration of the individual intention and the interactions within group motion patterns in diverse scenarios. Building on this, we propose a meta-learning framework to simulate the generalization process between source and target domains. Furthermore, to enhance the stability of our prediction outcomes, we propose a Serial and Parallel Training (SPT) strategy along with a feature augmentation method named MetaMix. Experimental results on several real-world datasets confirm that MetaTra not only surpasses other state-of-the-art methods but also exhibits plug-and-play capabilities, particularly in the realm of domain generalization.
Graph Neural Network with Curriculum Learning for Imbalanced Node Classification
Feb 05, 2022



Graph Neural Network (GNN) is an emerging technique for graph-based learning tasks such as node classification. In this work, we reveal the vulnerability of GNN to the imbalance of node labels. Traditional solutions for imbalanced classification (e.g. resampling) are ineffective in node classification without considering the graph structure. Worse still, they may even bring overfitting or underfitting results due to lack of sufficient prior knowledge. To solve these problems, we propose a novel graph neural network framework with curriculum learning (GNN-CL) consisting of two modules. For one thing, we hope to acquire certain reliable interpolation nodes and edges through the novel graph-based oversampling based on smoothness and homophily. For another, we combine graph classification loss and metric learning loss which adjust the distance between different nodes associated with minority class in feature space. Inspired by curriculum learning, we dynamically adjust the weights of different modules during training process to achieve better ability of generalization and discrimination. The proposed framework is evaluated via several widely used graph datasets, showing that our proposed model consistently outperforms the existing state-of-the-art methods.