 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-enhanced Vector Index
Sep 23, 2023

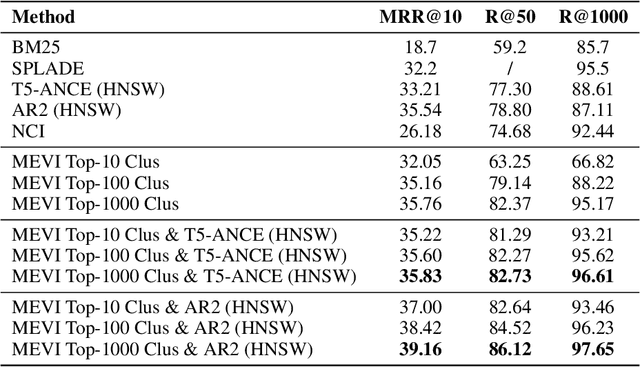

Embedding-based retrieval methods construct vector indices to search for document representations that are most similar to the query representations. They are widely used in document retrieval due to low latency and decent recall performance. Recent research indicates that deep retrieval solutions offer better model quality, but are hindered by unacceptable serving latency and the inability to support document updates. In this paper, we aim to enhance the vector index with end-to-end deep generative models, leveraging the differentiable advantages of deep retrieval models while maintaining desirable serving efficiency. We propose Model-enhanced Vector Index (MEVI), a differentiable model-enhanced index empowered by a twin-tower representation model. MEVI leverages a Residual Quantization (RQ) codebook to bridge the sequence-to-sequence deep retrieval and embedding-based models. To substantially reduce the inference time, instead of decoding the unique document ids in long sequential steps, we first generate some semantic virtual cluster ids of candidate documents in a small number of steps, and then leverage the well-adapted embedding vectors to further perform a fine-grained search for the relevant documents in the candidate virtual clusters. We empirically show that our model achieves better performance on the commonly used academic benchmarks MSMARCO Passage and Natural Questions, with comparable serving latency to dense retrieval solutions.
Annotation-Free and One-Shot Learning for Instance Segmentation of Homogeneous Object Clusters
Feb 07, 2018
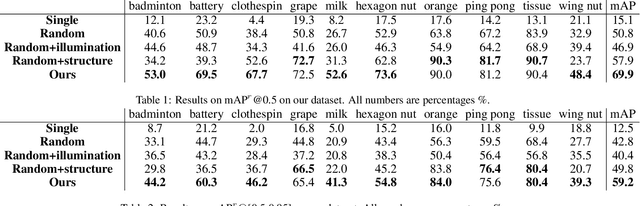
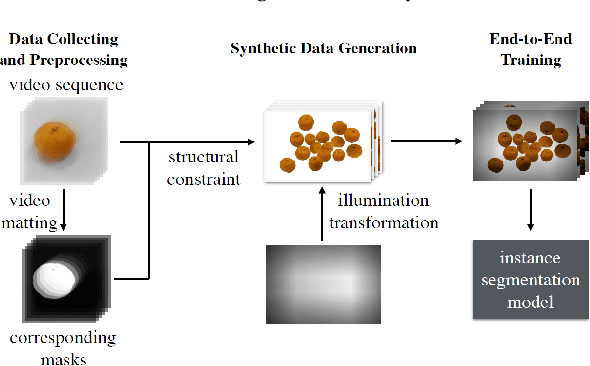

We propose a novel approach for instance segmen- tation given an image of homogeneous object clus- ter (HOC). Our learning approach is one-shot be- cause a single video of an object instance is cap- tured and it requires no human annotation. Our in- tuition is that images of homogeneous objects can be effectively synthesized based on structure and illumination priors derived from real images. A novel solver is proposed that iteratively maximizes our structured likelihood to generate realistic im- ages of HOC. Illumination transformation scheme is applied to make the real and synthetic images share the same illumination condition. Extensive experiments and comparisons are performed to ver- ify our method. We build a dataset consisting of pixel-level annotated images of HOC. The dataset and code will be published with the paper.