 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebChain: A Large-Scale Human-Annotated Dataset of Real-World Web Interaction Traces
Mar 05, 2026We introduce WebChain, the largest open-source dataset of human-annotated trajectories on real-world websites, designed to accelerate reproducible research in web agents. It contains 31,725 trajectories and 318k steps, featuring a core Triple Alignment of visual, structural, and action data to provide rich, multi-modal supervision. The data is collected via a scalable pipeline that ensures coverage of complex, high-value tasks often missed by synthetic methods. Leveraging this dataset, we propose a Dual Mid-Training recipe that decouples spatial grounding from planning, achieving state-of-the-art performance on our proposed WebChainBench and other public GUI benchmarks. Our work provides the data and insights necessary to build and rigorously evaluate the next generation of scalable web agents.
GRACE: Designing Generative Face Video Codec via Agile Hardware-Centric Workflow
Nov 12, 2025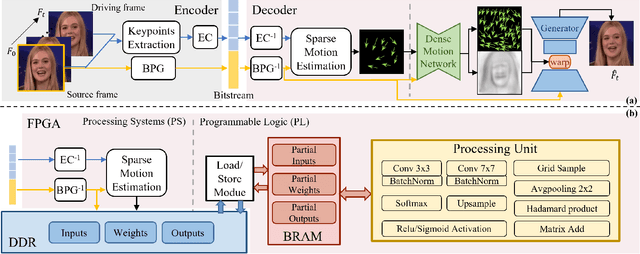


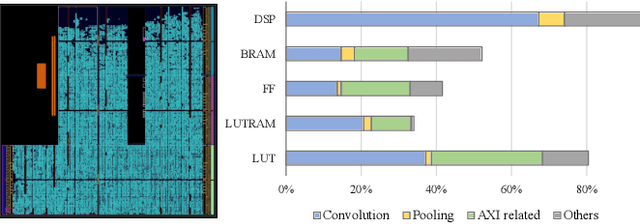
The Animation-based Generative Codec (AGC) is an emerging paradigm for talking-face video compression. However, deploying its intricate decoder on resource and power-constrained edge devices presents challenges due to numerous parameters, the inflexibility to adapt to dynamically evolving algorithms, and the high power consumption induced by extensive computations and data transmission. This paper for the first time proposes a novel field programmable gate arrays (FPGAs)-oriented AGC deployment scheme for edge-computing video services. Initially, we analyze the AGC algorithm and employ network compression methods including post-training static quantization and layer fusion techniques. Subsequently, we design an overlapped accelerator utilizing the co-processor paradigm to perform computations through software-hardware co-design. The hardware processing unit comprises engines such as convolution, grid sampling, upsample, etc. Parallelization optimization strategies like double-buffered pipelines and loop unrolling are employed to fully exploit the resources of FPGA. Ultimately, we establish an AGC FPGA prototype on the PYNQ-Z1 platform using the proposed scheme, achieving \textbf{24.9$\times$} and \textbf{4.1$\times$} higher energy efficiency against commercial Central Processing Unit (CPU) and Graphic Processing Unit (GPU), respectively. Specifically, only \textbf{11.7} microjoules ($\upmu$J) are required for one pixel reconstructed by this FPGA system.
VMTS: Vision-Assisted Teacher-Student Reinforcement Learning for Multi-Terrain Locomotion in Bipedal Robots
Mar 10, 2025Bipedal robots, due to their anthropomorphic design, offer substantial potential across various applications, yet their control is hindered by the complexity of their structure. Currently, most research focuses on proprioception-based methods, which lack the capability to overcome complex terrain. While visual perception is vital for operation in human-centric environments, its integration complicates control further. Recent reinforcement learning (RL) approaches have shown promise in enhancing legged robot locomotion, particularly with proprioception-based methods. However, terrain adaptability, especially for bipedal robots, remains a significant challenge, with most research focusing on flat-terrain scenarios. In this paper, we introduce a novel mixture of experts teacher-student network RL strategy, which enhances the performance of teacher-student policies based on visual inputs through a simple yet effective approach. Our method combines terrain selection strategies with the teacher policy, resulting in superior performance compared to traditional models. Additionally, we introduce an alignment loss between the teacher and student networks, rather than enforcing strict similarity, to improve the student's ability to navigate diverse terrains. We validate our approach experimentally on the Limx Dynamic P1 bipedal robot, demonstrating its feasibility and robustness across multiple terrain types.
LiteVAR: Compressing Visual Autoregressive Modelling with Efficient Attention and Quantization
Nov 26, 2024Visual Autoregressive (VAR) has emerged as a promising approach in image generation, offering competitive potential and performance comparable to diffusion-based models. However, current AR-based visual generation models require substantial computational resources, limiting their applicability on resource-constrained devices. To address this issue, we conducted analysis and identified significant redundancy in three dimensions of the VAR model: (1) the attention map, (2) the attention outputs when using classifier free guidance, and (3) the data precision. Correspondingly, we proposed efficient attention mechanism and low-bit quantization method to enhance the efficiency of VAR models while maintaining performance. With negligible performance lost (less than 0.056 FID increase), we could achieve 85.2% reduction in attention computation, 50% reduction in overall memory and 1.5x latency reduction. To ensure deployment feasibility, we developed efficient training-free compression techniques and analyze the deployment feasibility and efficiency gain of each technique.
M3-CVC: Controllable Video Compression with Multimodal Generative Models
Nov 24, 2024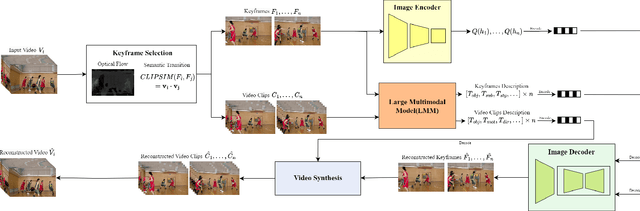
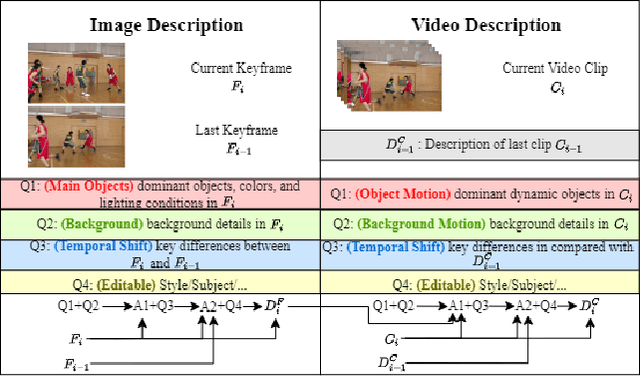
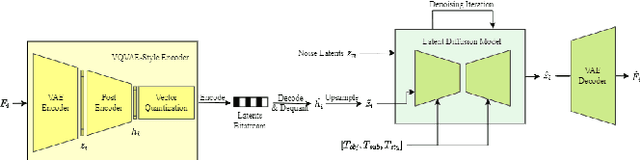
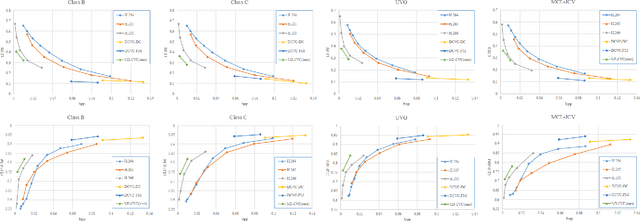
Traditional and neural video codecs commonly encounter limitations in controllability and generality under ultra-low-bitrate coding scenarios. To overcome these challenges, we propose M3-CVC, a controllable video compression framework incorporating multimodal generative models. The framework utilizes a semantic-motion composite strategy for keyframe selection to retain critical information. For each keyframe and its corresponding video clip, a dialogue-based large multimodal model (LMM) approach extracts hierarchical spatiotemporal details, enabling both inter-frame and intra-frame representations for improved video fidelity while enhancing encoding interpretability. M3-CVC further employs a conditional diffusion-based, text-guided keyframe compression method, achieving high fidelity in frame reconstruction. During decoding, textual descriptions derived from LMMs guide the diffusion process to restore the original video's content accurately. Experimental results demonstrate that M3-CVC significantly outperforms the state-of-the-art VVC standard in ultra-low bitrate scenarios, particularly in preserving semantic and perceptual fidelity.
PTA-Det: Point Transformer Associating Point cloud and Image for 3D Object Detection
Jan 18, 2023
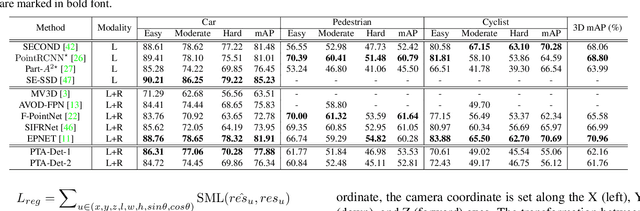
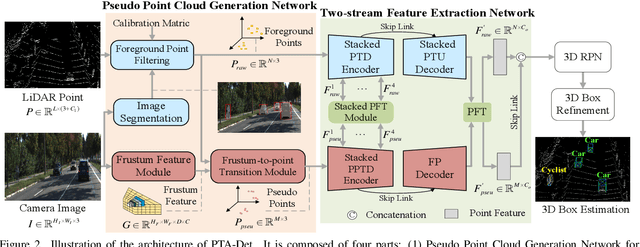
In autonomous driving, 3D object detection based on multi-modal data has become an indispensable approach when facing complex environments around the vehicle. During multi-modal detection, LiDAR and camera are simultaneously applied for capturing and modeling. However, due to the intrinsic discrepancies between the LiDAR point and camera image, the fusion of the data for object detection encounters a series of problems. Most multi-modal detection methods perform even worse than LiDAR-only methods. In this investigation, we propose a method named PTA-Det to improve the performance of multi-modal detection. Accompanied by PTA-Det, a Pseudo Point Cloud Generation Network is proposed, which can convert image information including texture and semantic features by pseudo points. Thereafter, through a transformer-based Point Fusion Transition (PFT) module, the features of LiDAR points and pseudo points from image can be deeply fused under a unified point-based representation. The combination of these modules can conquer the major obstacle in feature fusion across modalities and realizes a complementary and discriminative representation for proposal generation. Extensive experiments on the KITTI dataset show the PTA-Det achieves a competitive result and support its effectiveness.
From One to Many: Dynamic Cross Attention Networks for LiDAR and Camera Fusion
Sep 25, 2022
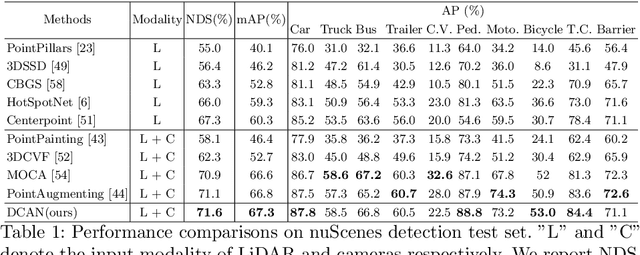
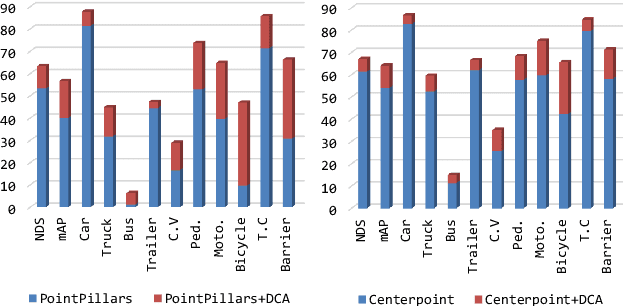
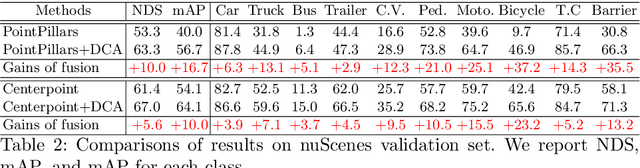
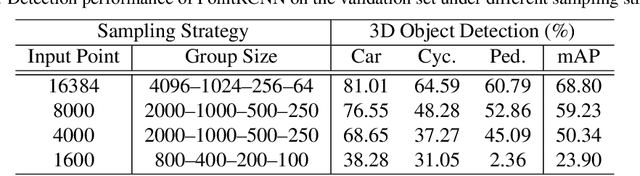
LiDAR and cameras are two complementary sensors for 3D perception in autonomous driving. LiDAR point clouds have accurate spatial and geometry information, while RGB images provide textural and color data for context reasoning. To exploit LiDAR and cameras jointly, existing fusion methods tend to align each 3D point to only one projected image pixel based on calibration, namely one-to-one mapping. However, the performance of these approaches highly relies on the calibration quality, which is sensitive to the temporal and spatial synchronization of sensors. Therefore, we propose a Dynamic Cross Attention (DCA) module with a novel one-to-many cross-modality mapping that learns multiple offsets from the initial projection towards the neighborhood and thus develops tolerance to calibration error. Moreover, a \textit{dynamic query enhancement} is proposed to perceive the model-independent calibration, which further strengthens DCA's tolerance to the initial misalignment. The whole fusion architecture named Dynamic Cross Attention Network (DCAN) exploits multi-level image features and adapts to multiple representations of point clouds, which allows DCA to serve as a plug-in fusion module. Extensive experiments on nuScenes and KITTI prove DCA's effectiveness. The proposed DCAN outperforms state-of-the-art methods on the nuScenes detection challenge.
Sparse Cross-scale Attention Network for Efficient LiDAR Panoptic Segmentation
Jan 16, 2022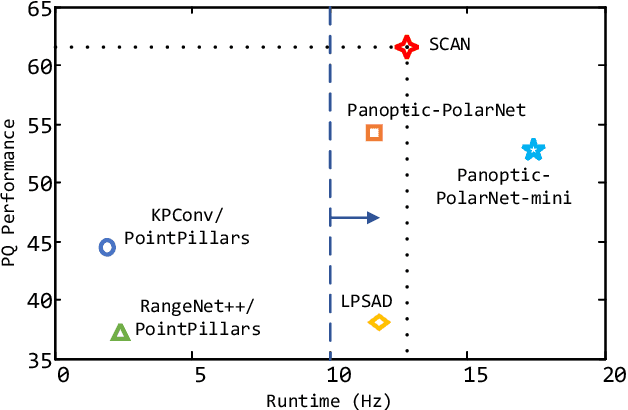


Two major challenges of 3D LiDAR Panoptic Segmentation (PS) are that point clouds of an object are surface-aggregated and thus hard to model the long-range dependency especially for large instances, and that objects are too close to separate each other. Recent literature addresses these problems by time-consuming grouping processes such as dual-clustering, mean-shift offsets, etc., or by bird-eye-view (BEV) dense centroid representation that downplays geometry. However, the long-range geometry relationship has not been sufficiently modeled by local feature learning from the above methods. To this end, we present SCAN, a novel sparse cross-scale attention network to first align multi-scale sparse features with global voxel-encoded attention to capture the long-range relationship of instance context, which can boost the regression accuracy of the over-segmented large objects. For the surface-aggregated points, SCAN adopts a novel sparse class-agnostic representation of instance centroids, which can not only maintain the sparsity of aligned features to solve the under-segmentation on small objects, but also reduce the computation amount of the network through sparse convolution. Our method outperforms previous methods by a large margin in the SemanticKITTI dataset for the challenging 3D PS task, achieving 1st place with a real-time inference speed.
DRINet++: Efficient Voxel-as-point Point Cloud Segmentation
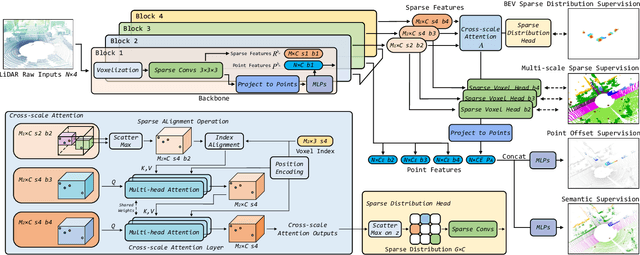
Nov 16, 2021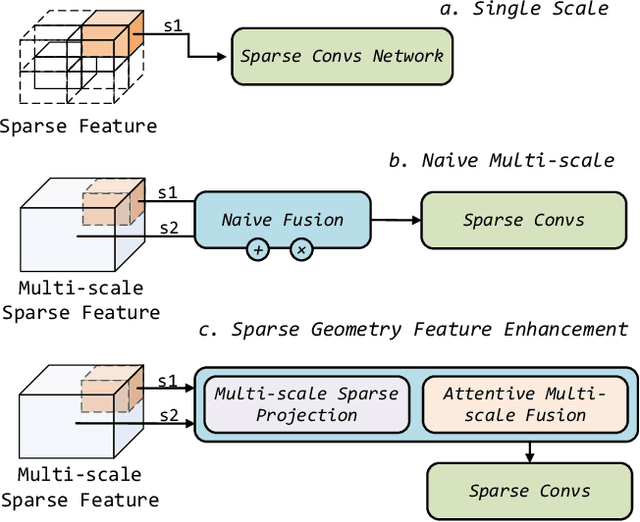
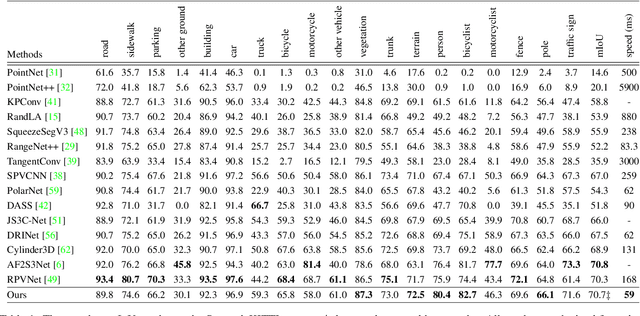
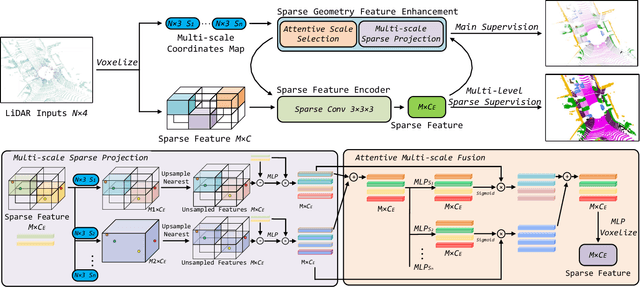
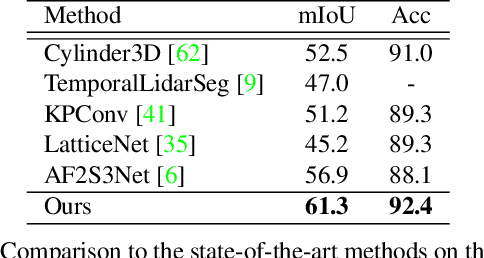
Recently, many approaches have been proposed through single or multiple representations to improve the performance of point cloud semantic segmentation. However, these works do not maintain a good balance among performance, efficiency, and memory consumption. To address these issues, we propose DRINet++ that extends DRINet by enhancing the sparsity and geometric properties of a point cloud with a voxel-as-point principle. To improve efficiency and performance, DRINet++ mainly consists of two modules: Sparse Feature Encoder and Sparse Geometry Feature Enhancement. The Sparse Feature Encoder extracts the local context information for each point, and the Sparse Geometry Feature Enhancement enhances the geometric properties of a sparse point cloud via multi-scale sparse projection and attentive multi-scale fusion. In addition, we propose deep sparse supervision in the training phase to help convergence and alleviate the memory consumption problem. Our DRINet++ achieves state-of-the-art outdoor point cloud segmentation on both SemanticKITTI and Nuscenes datasets while running significantly faster and consuming less memory.