 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePriorMapNet: Enhancing Online Vectorized HD Map Construction with Priors
Aug 16, 2024



Online vectorized High-Definition (HD) map construction is crucial for subsequent prediction and planning tasks in autonomous driving. Following MapTR paradigm, recent works have made noteworthy achievements. However, reference points are randomly initialized in mainstream methods, leading to unstable matching between predictions and ground truth. To address this issue, we introduce PriorMapNet to enhance online vectorized HD map construction with priors. We propose the PPS-Decoder, which provides reference points with position and structure priors. Fitted from the map elements in the dataset, prior reference points lower the learning difficulty and achieve stable matching. Furthermore, we propose the PF-Encoder to enhance the image-to-BEV transformation with BEV feature priors. Besides, we propose the DMD cross-attention, which decouples cross-attention along multi-scale and multi-sample respectively to achieve efficiency. Our proposed PriorMapNet achieves state-of-the-art performance in the online vectorized HD map construction task on nuScenes and Argoverse2 datasets. The code will be released publicly soon.
Learning High-resolution Vector Representation from Multi-Camera Images for 3D Object Detection
Jul 22, 2024The Bird's-Eye-View (BEV) representation is a critical factor that directly impacts the 3D object detection performance, but the traditional BEV grid representation induces quadratic computational cost as the spatial resolution grows. To address this limitation, we present a new camera-based 3D object detector with high-resolution vector representation: VectorFormer. The presented high-resolution vector representation is combined with the lower-resolution BEV representation to efficiently exploit 3D geometry from multi-camera images at a high resolution through our two novel modules: vector scattering and gathering. To this end, the learned vector representation with richer scene contexts can serve as the decoding query for final predictions. We conduct extensive experiments on the nuScenes dataset and demonstrate state-of-the-art performance in NDS and inference time. Furthermore, we investigate query-BEV-based methods incorporated with our proposed vector representation and observe a consistent performance improvement.
SVQNet: Sparse Voxel-Adjacent Query Network for 4D Spatio-Temporal LiDAR Semantic Segmentation
Aug 25, 2023



LiDAR-based semantic perception tasks are critical yet challenging for autonomous driving. Due to the motion of objects and static/dynamic occlusion, temporal information plays an essential role in reinforcing perception by enhancing and completing single-frame knowledge. Previous approaches either directly stack historical frames to the current frame or build a 4D spatio-temporal neighborhood using KNN, which duplicates computation and hinders realtime performance. Based on our observation that stacking all the historical points would damage performance due to a large amount of redundant and misleading information, we propose the Sparse Voxel-Adjacent Query Network (SVQNet) for 4D LiDAR semantic segmentation. To take full advantage of the historical frames high-efficiently, we shunt the historical points into two groups with reference to the current points. One is the Voxel-Adjacent Neighborhood carrying local enhancing knowledge. The other is the Historical Context completing the global knowledge. Then we propose new modules to select and extract the instructive features from the two groups. Our SVQNet achieves state-of-the-art performance in LiDAR semantic segmentation of the SemanticKITTI benchmark and the nuScenes dataset.
From One to Many: Dynamic Cross Attention Networks for LiDAR and Camera Fusion
Sep 25, 2022
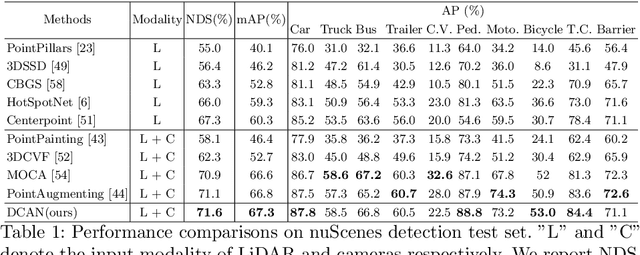
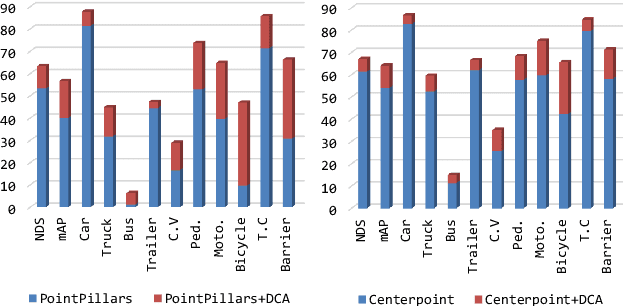
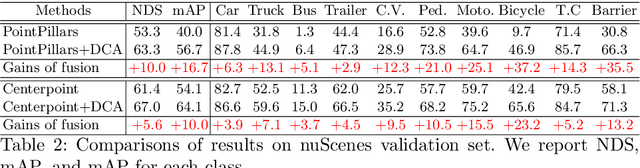
LiDAR and cameras are two complementary sensors for 3D perception in autonomous driving. LiDAR point clouds have accurate spatial and geometry information, while RGB images provide textural and color data for context reasoning. To exploit LiDAR and cameras jointly, existing fusion methods tend to align each 3D point to only one projected image pixel based on calibration, namely one-to-one mapping. However, the performance of these approaches highly relies on the calibration quality, which is sensitive to the temporal and spatial synchronization of sensors. Therefore, we propose a Dynamic Cross Attention (DCA) module with a novel one-to-many cross-modality mapping that learns multiple offsets from the initial projection towards the neighborhood and thus develops tolerance to calibration error. Moreover, a \textit{dynamic query enhancement} is proposed to perceive the model-independent calibration, which further strengthens DCA's tolerance to the initial misalignment. The whole fusion architecture named Dynamic Cross Attention Network (DCAN) exploits multi-level image features and adapts to multiple representations of point clouds, which allows DCA to serve as a plug-in fusion module. Extensive experiments on nuScenes and KITTI prove DCA's effectiveness. The proposed DCAN outperforms state-of-the-art methods on the nuScenes detection challenge.
Sparse Cross-scale Attention Network for Efficient LiDAR Panoptic Segmentation
Jan 16, 2022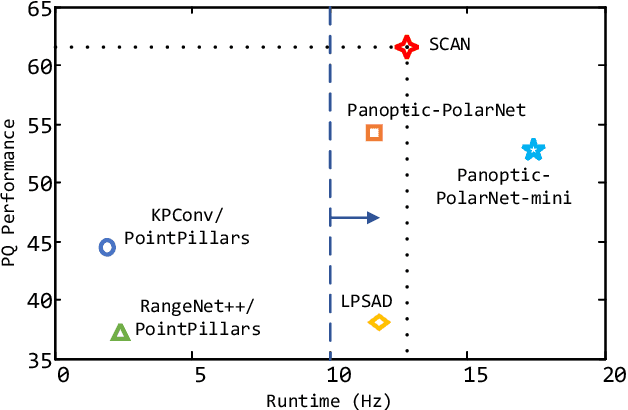


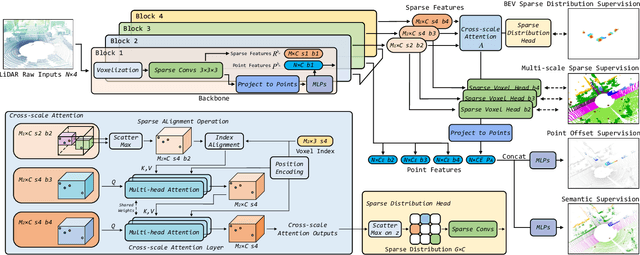
Two major challenges of 3D LiDAR Panoptic Segmentation (PS) are that point clouds of an object are surface-aggregated and thus hard to model the long-range dependency especially for large instances, and that objects are too close to separate each other. Recent literature addresses these problems by time-consuming grouping processes such as dual-clustering, mean-shift offsets, etc., or by bird-eye-view (BEV) dense centroid representation that downplays geometry. However, the long-range geometry relationship has not been sufficiently modeled by local feature learning from the above methods. To this end, we present SCAN, a novel sparse cross-scale attention network to first align multi-scale sparse features with global voxel-encoded attention to capture the long-range relationship of instance context, which can boost the regression accuracy of the over-segmented large objects. For the surface-aggregated points, SCAN adopts a novel sparse class-agnostic representation of instance centroids, which can not only maintain the sparsity of aligned features to solve the under-segmentation on small objects, but also reduce the computation amount of the network through sparse convolution. Our method outperforms previous methods by a large margin in the SemanticKITTI dataset for the challenging 3D PS task, achieving 1st place with a real-time inference speed.