 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning High-resolution Vector Representation from Multi-Camera Images for 3D Object Detection
Jul 22, 2024The Bird's-Eye-View (BEV) representation is a critical factor that directly impacts the 3D object detection performance, but the traditional BEV grid representation induces quadratic computational cost as the spatial resolution grows. To address this limitation, we present a new camera-based 3D object detector with high-resolution vector representation: VectorFormer. The presented high-resolution vector representation is combined with the lower-resolution BEV representation to efficiently exploit 3D geometry from multi-camera images at a high resolution through our two novel modules: vector scattering and gathering. To this end, the learned vector representation with richer scene contexts can serve as the decoding query for final predictions. We conduct extensive experiments on the nuScenes dataset and demonstrate state-of-the-art performance in NDS and inference time. Furthermore, we investigate query-BEV-based methods incorporated with our proposed vector representation and observe a consistent performance improvement.
DeepEMplanner: An End-to-End EM Motion Planner with Iterative Interactions
Nov 29, 2023

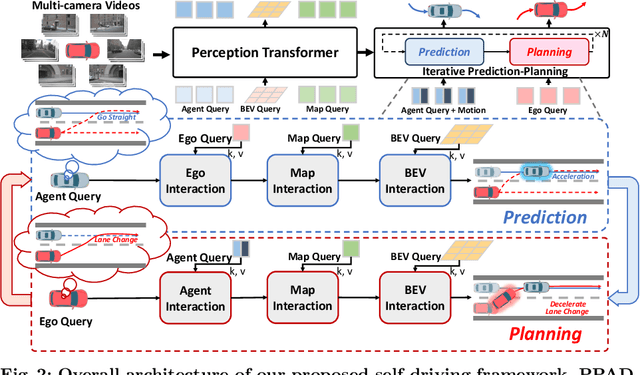

Motion planning is a computational problem that finds a sequence of valid trajectories, often based on surrounding agents' forecasting, environmental understanding, and historical and future contexts. It can also be viewed as a game in which agents continuously plan their next move according to other agents' intentions and the encountering environment, further achieving their ultimate goals through incremental actions. To model the dynamic planning and interaction process, we propose a novel framework, DeepEMplanner, which takes the stepwise interaction into account for fine-grained behavior learning. The ego vehicle maximizes each step motion to reach its eventual driving outcome based on the stepwise expectation from agents and its upcoming road conditions. On the other hand, the agents also follow the same philosophy to maximize their stepwise behavior under the encountering environment and the expectations from ego and other agents. Our DeepEMplanner models the interactions among ego, agents, and the dynamic environment in an autoregressive manner by interleaving the Expectation and Maximization processes. Further, we design ego-to-agents, ego-to-map, and ego-to-BEV interaction mechanisms with hierarchical dynamic key objects attention to better model the interactions. Experiments on the nuScenes benchmark show that our approach achieves state-of-the-art results.
SVQNet: Sparse Voxel-Adjacent Query Network for 4D Spatio-Temporal LiDAR Semantic Segmentation
Aug 25, 2023



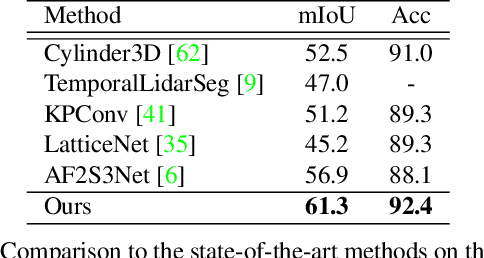
LiDAR-based semantic perception tasks are critical yet challenging for autonomous driving. Due to the motion of objects and static/dynamic occlusion, temporal information plays an essential role in reinforcing perception by enhancing and completing single-frame knowledge. Previous approaches either directly stack historical frames to the current frame or build a 4D spatio-temporal neighborhood using KNN, which duplicates computation and hinders realtime performance. Based on our observation that stacking all the historical points would damage performance due to a large amount of redundant and misleading information, we propose the Sparse Voxel-Adjacent Query Network (SVQNet) for 4D LiDAR semantic segmentation. To take full advantage of the historical frames high-efficiently, we shunt the historical points into two groups with reference to the current points. One is the Voxel-Adjacent Neighborhood carrying local enhancing knowledge. The other is the Historical Context completing the global knowledge. Then we propose new modules to select and extract the instructive features from the two groups. Our SVQNet achieves state-of-the-art performance in LiDAR semantic segmentation of the SemanticKITTI benchmark and the nuScenes dataset.
From One to Many: Dynamic Cross Attention Networks for LiDAR and Camera Fusion
Sep 25, 2022
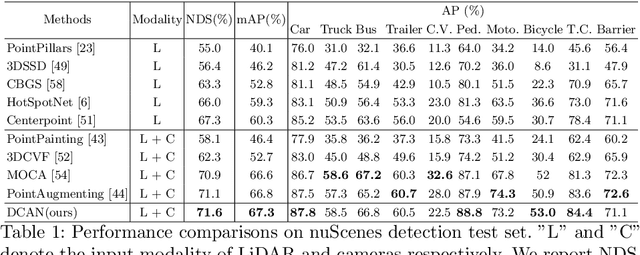
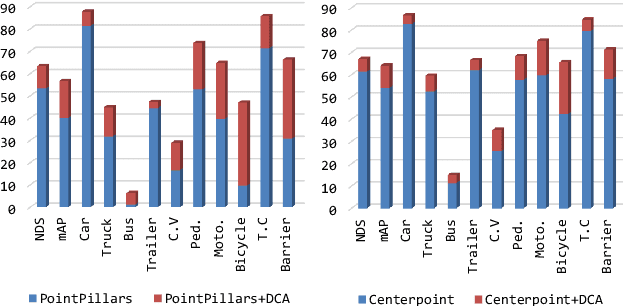
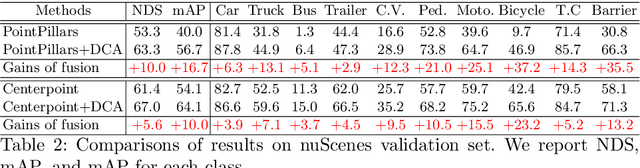
LiDAR and cameras are two complementary sensors for 3D perception in autonomous driving. LiDAR point clouds have accurate spatial and geometry information, while RGB images provide textural and color data for context reasoning. To exploit LiDAR and cameras jointly, existing fusion methods tend to align each 3D point to only one projected image pixel based on calibration, namely one-to-one mapping. However, the performance of these approaches highly relies on the calibration quality, which is sensitive to the temporal and spatial synchronization of sensors. Therefore, we propose a Dynamic Cross Attention (DCA) module with a novel one-to-many cross-modality mapping that learns multiple offsets from the initial projection towards the neighborhood and thus develops tolerance to calibration error. Moreover, a \textit{dynamic query enhancement} is proposed to perceive the model-independent calibration, which further strengthens DCA's tolerance to the initial misalignment. The whole fusion architecture named Dynamic Cross Attention Network (DCAN) exploits multi-level image features and adapts to multiple representations of point clouds, which allows DCA to serve as a plug-in fusion module. Extensive experiments on nuScenes and KITTI prove DCA's effectiveness. The proposed DCAN outperforms state-of-the-art methods on the nuScenes detection challenge.
Sparse Cross-scale Attention Network for Efficient LiDAR Panoptic Segmentation
Jan 16, 2022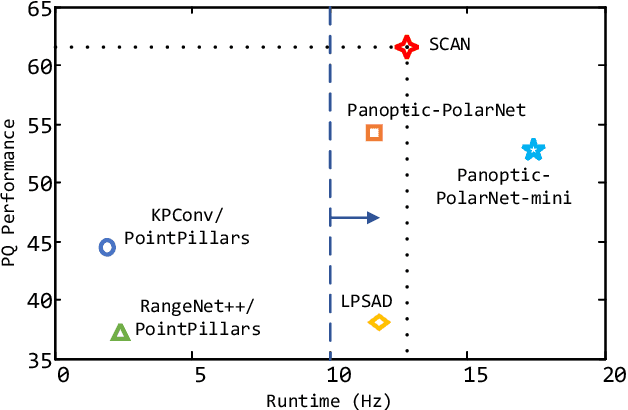


Two major challenges of 3D LiDAR Panoptic Segmentation (PS) are that point clouds of an object are surface-aggregated and thus hard to model the long-range dependency especially for large instances, and that objects are too close to separate each other. Recent literature addresses these problems by time-consuming grouping processes such as dual-clustering, mean-shift offsets, etc., or by bird-eye-view (BEV) dense centroid representation that downplays geometry. However, the long-range geometry relationship has not been sufficiently modeled by local feature learning from the above methods. To this end, we present SCAN, a novel sparse cross-scale attention network to first align multi-scale sparse features with global voxel-encoded attention to capture the long-range relationship of instance context, which can boost the regression accuracy of the over-segmented large objects. For the surface-aggregated points, SCAN adopts a novel sparse class-agnostic representation of instance centroids, which can not only maintain the sparsity of aligned features to solve the under-segmentation on small objects, but also reduce the computation amount of the network through sparse convolution. Our method outperforms previous methods by a large margin in the SemanticKITTI dataset for the challenging 3D PS task, achieving 1st place with a real-time inference speed.
DRINet++: Efficient Voxel-as-point Point Cloud Segmentation
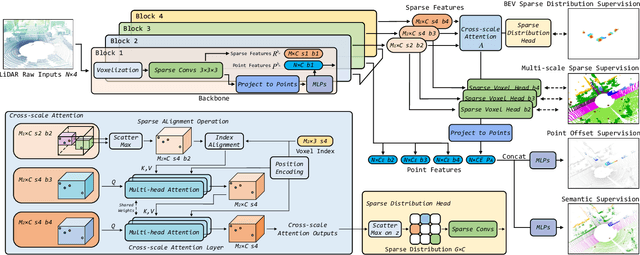
Nov 16, 2021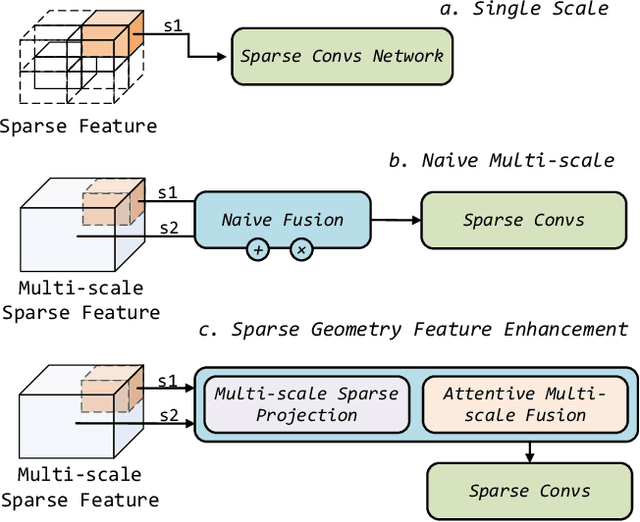
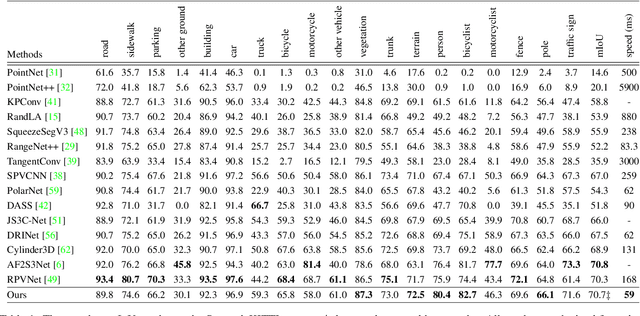
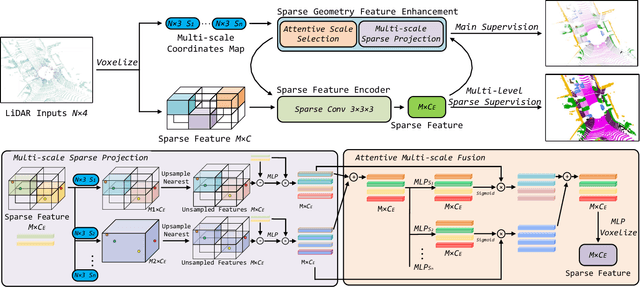
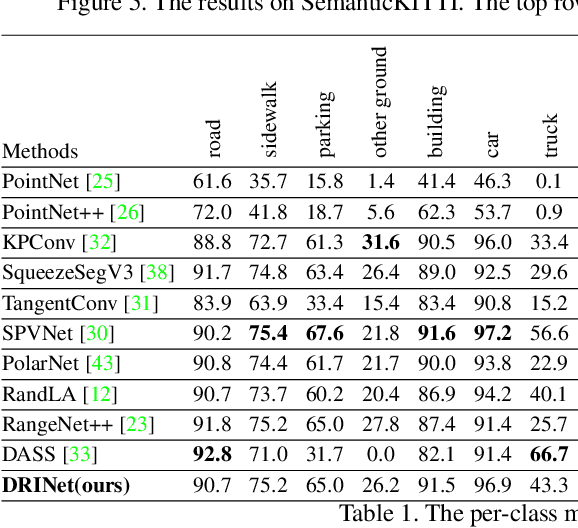
Recently, many approaches have been proposed through single or multiple representations to improve the performance of point cloud semantic segmentation. However, these works do not maintain a good balance among performance, efficiency, and memory consumption. To address these issues, we propose DRINet++ that extends DRINet by enhancing the sparsity and geometric properties of a point cloud with a voxel-as-point principle. To improve efficiency and performance, DRINet++ mainly consists of two modules: Sparse Feature Encoder and Sparse Geometry Feature Enhancement. The Sparse Feature Encoder extracts the local context information for each point, and the Sparse Geometry Feature Enhancement enhances the geometric properties of a sparse point cloud via multi-scale sparse projection and attentive multi-scale fusion. In addition, we propose deep sparse supervision in the training phase to help convergence and alleviate the memory consumption problem. Our DRINet++ achieves state-of-the-art outdoor point cloud segmentation on both SemanticKITTI and Nuscenes datasets while running significantly faster and consuming less memory.
DRINet: A Dual-Representation Iterative Learning Network for Point Cloud Segmentation
Aug 09, 2021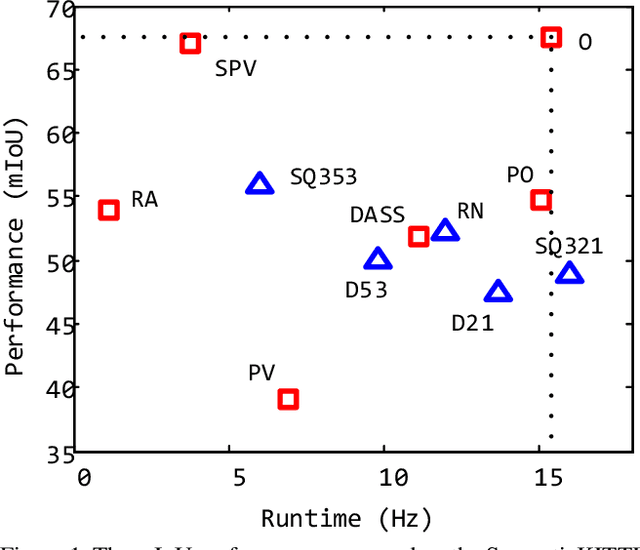
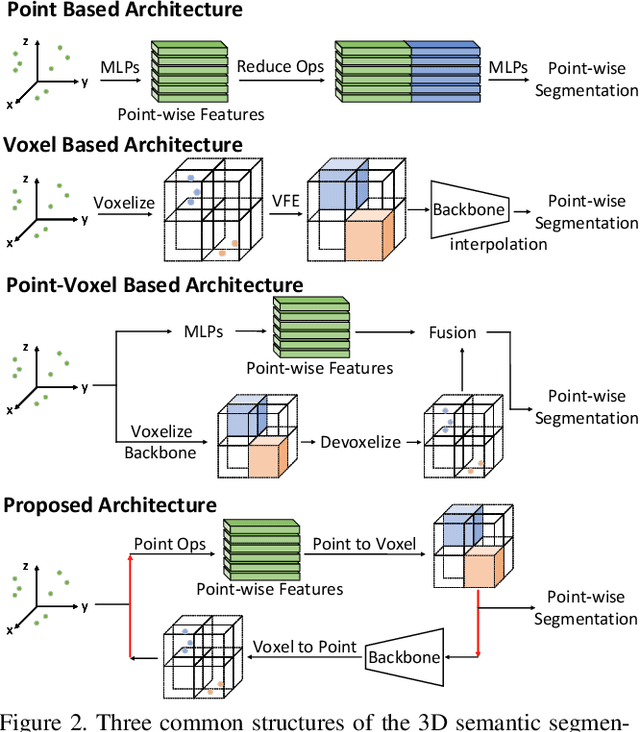

We present a novel and flexible architecture for point cloud segmentation with dual-representation iterative learning. In point cloud processing, different representations have their own pros and cons. Thus, finding suitable ways to represent point cloud data structure while keeping its own internal physical property such as permutation and scale-invariant is a fundamental problem. Therefore, we propose our work, DRINet, which serves as the basic network structure for dual-representation learning with great flexibility at feature transferring and less computation cost, especially for large-scale point clouds. DRINet mainly consists of two modules called Sparse Point-Voxel Feature Extraction and Sparse Voxel-Point Feature Extraction. By utilizing these two modules iteratively, features can be propagated between two different representations. We further propose a novel multi-scale pooling layer for pointwise locality learning to improve context information propagation. Our network achieves state-of-the-art results for point cloud classification and segmentation tasks on several datasets while maintaining high runtime efficiency. For large-scale outdoor scenarios, our method outperforms state-of-the-art methods with a real-time inference speed of 62ms per frame.
Coarse to Fine: Domain Adaptive Crowd Counting via Adversarial Scoring Network
Jul 27, 2021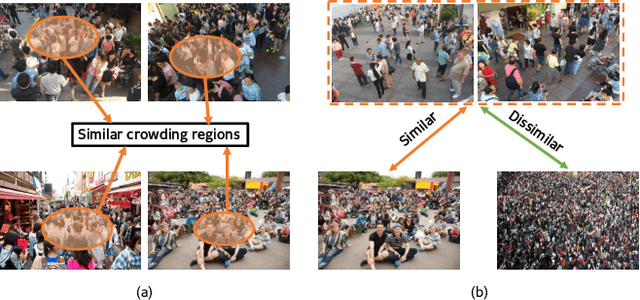
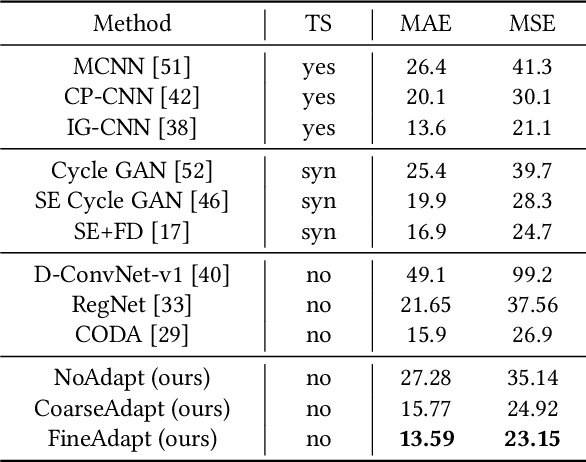
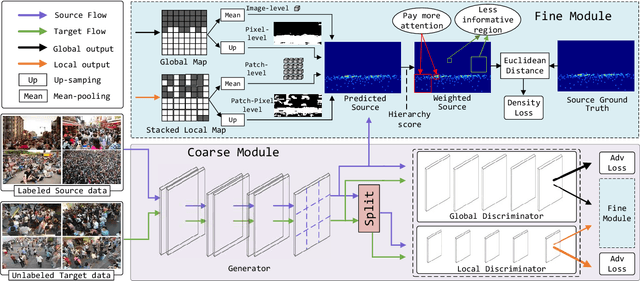
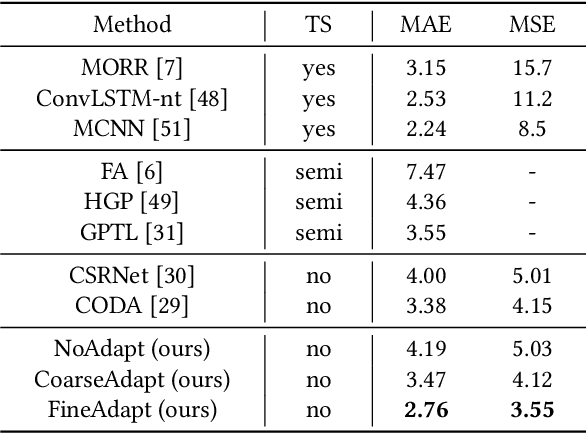
Recent deep networks have convincingly demonstrated high capability in crowd counting, which is a critical task attracting widespread attention due to its various industrial applications. Despite such progress, trained data-dependent models usually can not generalize well to unseen scenarios because of the inherent domain shift. To facilitate this issue, this paper proposes a novel adversarial scoring network (ASNet) to gradually bridge the gap across domains from coarse to fine granularity. In specific, at the coarse-grained stage, we design a dual-discriminator strategy to adapt source domain to be close to the targets from the perspectives of both global and local feature space via adversarial learning. The distributions between two domains can thus be aligned roughly. At the fine-grained stage, we explore the transferability of source characteristics by scoring how similar the source samples are to target ones from multiple levels based on generative probability derived from coarse stage. Guided by these hierarchical scores, the transferable source features are properly selected to enhance the knowledge transfer during the adaptation process. With the coarse-to-fine design, the generalization bottleneck induced from the domain discrepancy can be effectively alleviated. Three sets of migration experiments show that the proposed methods achieve state-of-the-art counting performance compared with major unsupervised methods.
Spatiotemporal Graph Neural Network based Mask Reconstruction for Video Object Segmentation
Dec 10, 2020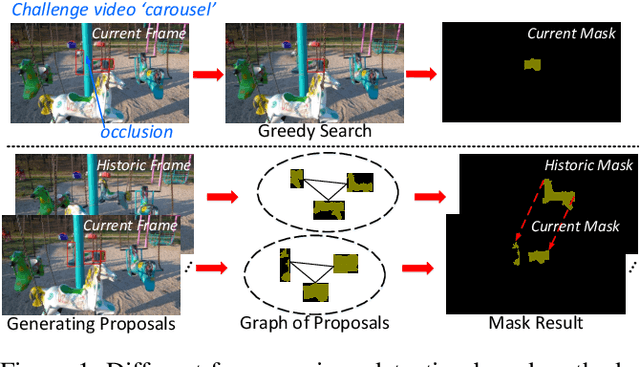
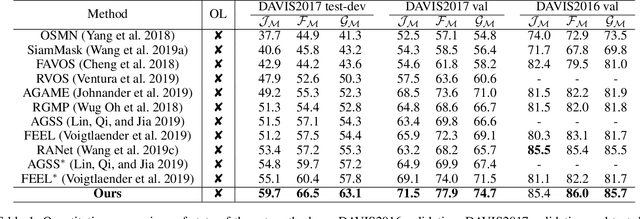
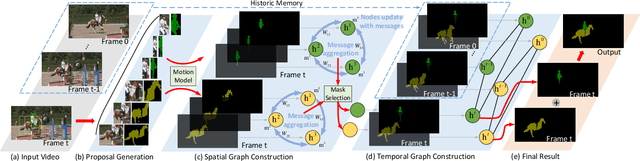
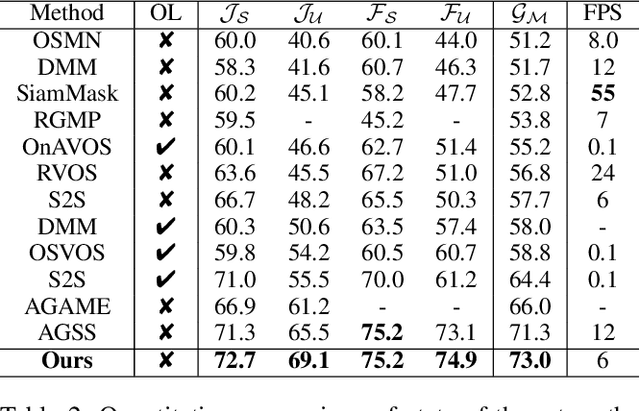
This paper addresses the task of segmenting class-agnostic objects in semi-supervised setting. Although previous detection based methods achieve relatively good performance, these approaches extract the best proposal by a greedy strategy, which may lose the local patch details outside the chosen candidate. In this paper, we propose a novel spatiotemporal graph neural network (STG-Net) to reconstruct more accurate masks for video object segmentation, which captures the local contexts by utilizing all proposals. In the spatial graph, we treat object proposals of a frame as nodes and represent their correlations with an edge weight strategy for mask context aggregation. To capture temporal information from previous frames, we use a memory network to refine the mask of current frame by retrieving historic masks in a temporal graph. The joint use of both local patch details and temporal relationships allow us to better address the challenges such as object occlusion and missing. Without online learning and fine-tuning, our STG-Net achieves state-of-the-art performance on four large benchmarks (DAVIS, YouTube-VOS, SegTrack-v2, and YouTube-Objects), demonstrating the effectiveness of the proposed approach.
HVNet: Hybrid Voxel Network for LiDAR Based 3D Object Detection
Mar 16, 2020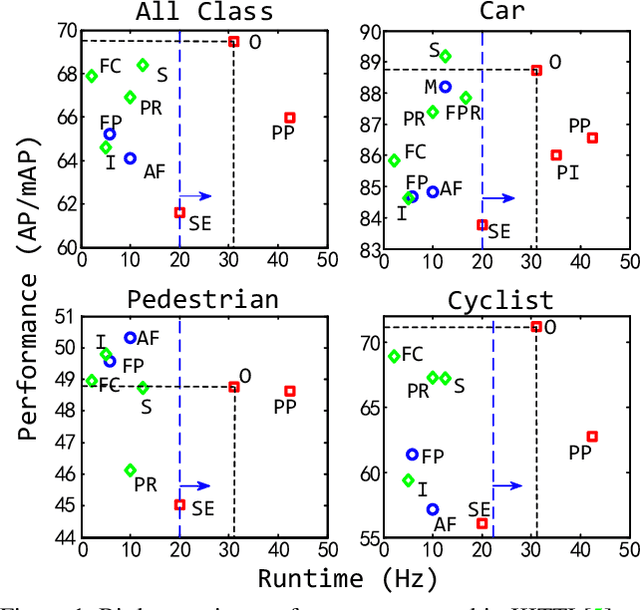
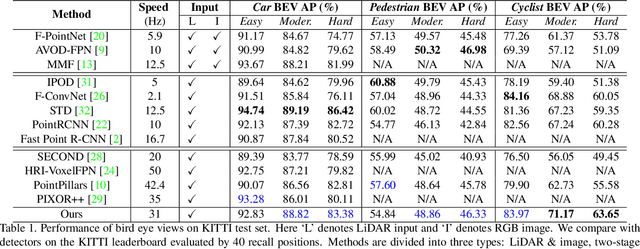
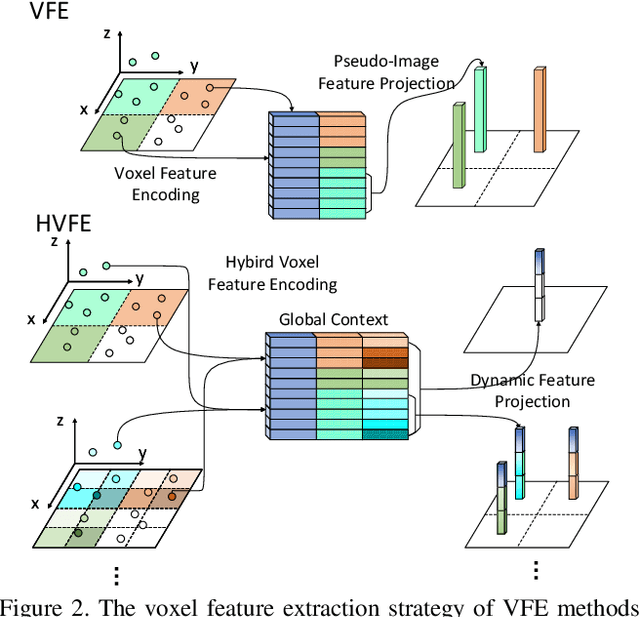
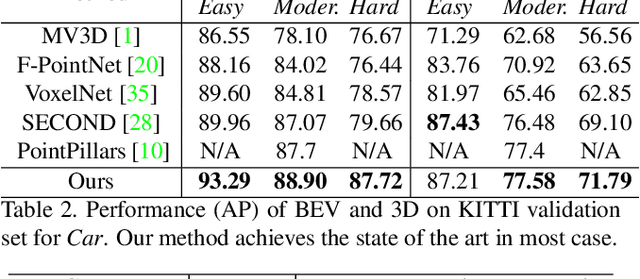
We present Hybrid Voxel Network (HVNet), a novel one-stage unified network for point cloud based 3D object detection for autonomous driving. Recent studies show that 2D voxelization with per voxel PointNet style feature extractor leads to accurate and efficient detector for large 3D scenes. Since the size of the feature map determines the computation and memory cost, the size of the voxel becomes a parameter that is hard to balance. A smaller voxel size gives a better performance, especially for small objects, but a longer inference time. A larger voxel can cover the same area with a smaller feature map, but fails to capture intricate features and accurate location for smaller objects. We present a Hybrid Voxel network that solves this problem by fusing voxel feature encoder (VFE) of different scales at point-wise level and project into multiple pseudo-image feature maps. We further propose an attentive voxel feature encoding that outperforms plain VFE and a feature fusion pyramid network to aggregate multi-scale information at feature map level. Experiments on the KITTI benchmark show that a single HVNet achieves the best mAP among all existing methods with a real time inference speed of 31Hz.