 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplosive Output to Enhance Jumping Ability: A Variable Reduction Ratio Design Paradigm for Humanoid Robots Knee Joint
Jun 14, 2025Enhancing the explosive power output of the knee joints is critical for improving the agility and obstacle-crossing capabilities of humanoid robots. However, a mismatch between the knee-to-center-of-mass (CoM) transmission ratio and jumping demands, coupled with motor performance degradation at high speeds, restricts the duration of high-power output and limits jump performance. To address these problems, this paper introduces a novel knee joint design paradigm employing a dynamically decreasing reduction ratio for explosive output during jump. Analysis of motor output characteristics and knee kinematics during jumping inspired a coupling strategy in which the reduction ratio gradually decreases as the joint extends. A high initial ratio rapidly increases torque at jump initiation, while its gradual reduction minimizes motor speed increments and power losses, thereby maintaining sustained high-power output. A compact and efficient linear actuator-driven guide-rod mechanism realizes this coupling strategy, supported by parameter optimization guided by explosive jump control strategies. Experimental validation demonstrated a 63 cm vertical jump on a single-joint platform (a theoretical improvement of 28.1\% over the optimal fixed-ratio joints). Integrated into a humanoid robot, the proposed design enabled a 1.1 m long jump, a 0.5 m vertical jump, and a 0.5 m box jump.
P3P: Pseudo-3D Pre-training for Scaling 3D Masked Autoencoders
Aug 19, 20243D pre-training is crucial to 3D perception tasks. However, limited by the difficulties in collecting clean 3D data, 3D pre-training consistently faced data scaling challenges. Inspired by semi-supervised learning leveraging limited labeled data and a large amount of unlabeled data, in this work, we propose a novel self-supervised pre-training framework utilizing the real 3D data and the pseudo-3D data lifted from images by a large depth estimation model. Another challenge lies in the efficiency. Previous methods such as Point-BERT and Point-MAE, employ k nearest neighbors to embed 3D tokens, requiring quadratic time complexity. To efficiently pre-train on such a large amount of data, we propose a linear-time-complexity token embedding strategy and a training-efficient 2D reconstruction target. Our method achieves state-of-the-art performance in 3D classification and few-shot learning while maintaining high pre-training and downstream fine-tuning efficiency.
LIKO: LiDAR, Inertial, and Kinematic Odometry for Bipedal Robots
Apr 28, 2024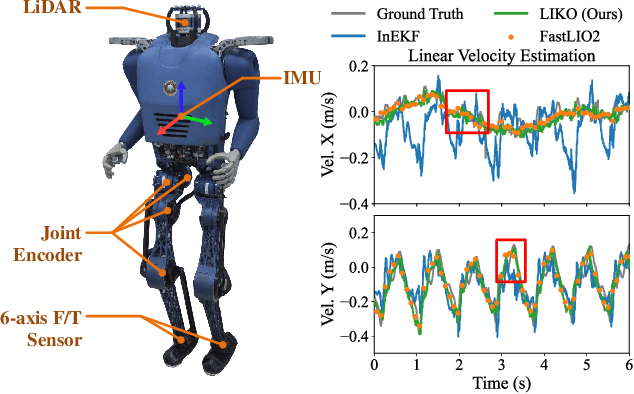
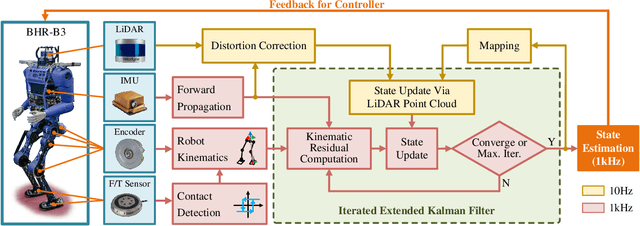
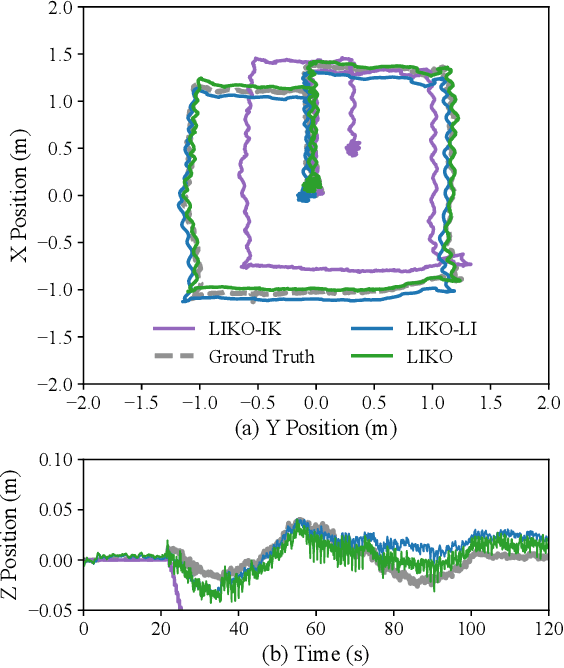
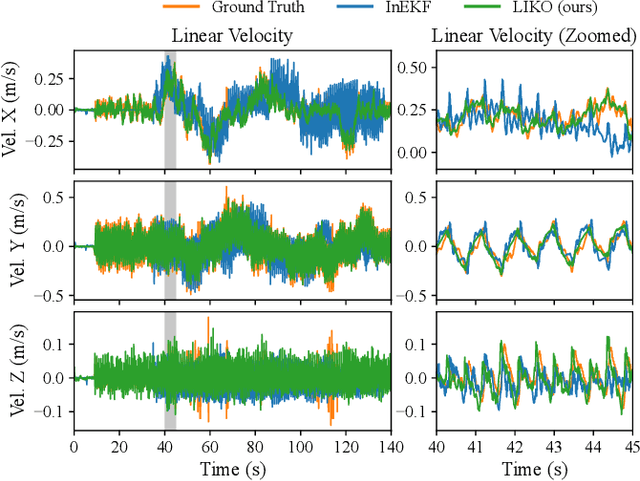
High-frequency and accurate state estimation is crucial for biped robots. This paper presents a tightly-coupled LiDAR-Inertial-Kinematic Odometry (LIKO) for biped robot state estimation based on an iterated extended Kalman filter. Beyond state estimation, the foot contact position is also modeled and estimated. This allows for both position and velocity updates from kinematic measurement. Additionally, the use of kinematic measurement results in an increased output state frequency of about 1kHz. This ensures temporal continuity of the estimated state and makes it practical for control purposes of biped robots. We also announce a biped robot dataset consisting of LiDAR, inertial measurement unit (IMU), joint encoders, force/torque (F/T) sensors, and motion capture ground truth to evaluate the proposed method. The dataset is collected during robot locomotion, and our approach reached the best quantitative result among other LIO-based methods and biped robot state estimation algorithms. The dataset and source code will be available at https://github.com/Mr-Zqr/LIKO.
SVQNet: Sparse Voxel-Adjacent Query Network for 4D Spatio-Temporal LiDAR Semantic Segmentation
Aug 25, 2023



LiDAR-based semantic perception tasks are critical yet challenging for autonomous driving. Due to the motion of objects and static/dynamic occlusion, temporal information plays an essential role in reinforcing perception by enhancing and completing single-frame knowledge. Previous approaches either directly stack historical frames to the current frame or build a 4D spatio-temporal neighborhood using KNN, which duplicates computation and hinders realtime performance. Based on our observation that stacking all the historical points would damage performance due to a large amount of redundant and misleading information, we propose the Sparse Voxel-Adjacent Query Network (SVQNet) for 4D LiDAR semantic segmentation. To take full advantage of the historical frames high-efficiently, we shunt the historical points into two groups with reference to the current points. One is the Voxel-Adjacent Neighborhood carrying local enhancing knowledge. The other is the Historical Context completing the global knowledge. Then we propose new modules to select and extract the instructive features from the two groups. Our SVQNet achieves state-of-the-art performance in LiDAR semantic segmentation of the SemanticKITTI benchmark and the nuScenes dataset.