 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Graph Neural Network based Mask Reconstruction for Video Object Segmentation
Paper and Code
Dec 10, 2020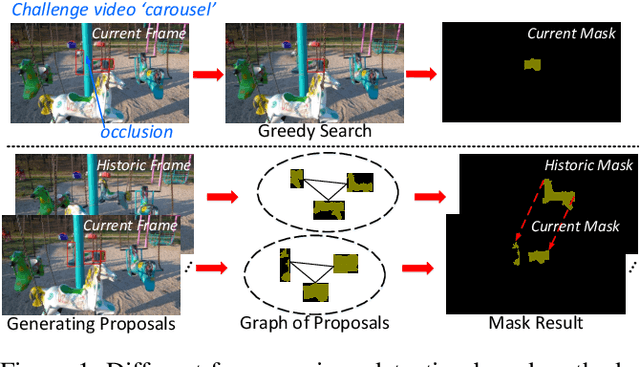
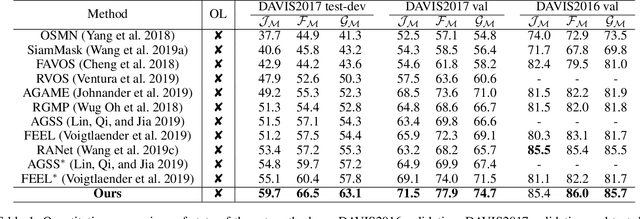
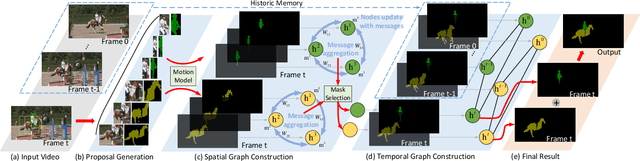
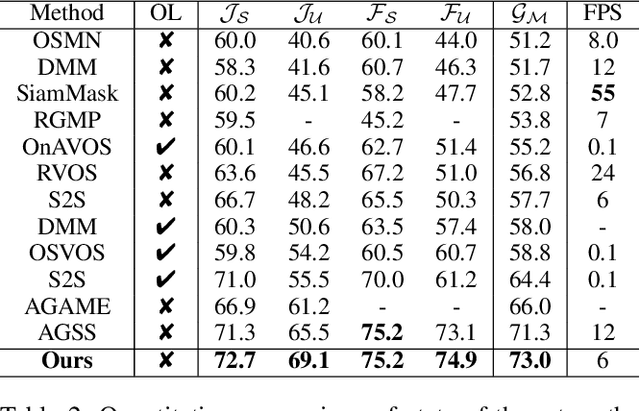
This paper addresses the task of segmenting class-agnostic objects in semi-supervised setting. Although previous detection based methods achieve relatively good performance, these approaches extract the best proposal by a greedy strategy, which may lose the local patch details outside the chosen candidate. In this paper, we propose a novel spatiotemporal graph neural network (STG-Net) to reconstruct more accurate masks for video object segmentation, which captures the local contexts by utilizing all proposals. In the spatial graph, we treat object proposals of a frame as nodes and represent their correlations with an edge weight strategy for mask context aggregation. To capture temporal information from previous frames, we use a memory network to refine the mask of current frame by retrieving historic masks in a temporal graph. The joint use of both local patch details and temporal relationships allow us to better address the challenges such as object occlusion and missing. Without online learning and fine-tuning, our STG-Net achieves state-of-the-art performance on four large benchmarks (DAVIS, YouTube-VOS, SegTrack-v2, and YouTube-Objects), demonstrating the effectiveness of the proposed approach.